PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Opus 4.8
Can Anthropic bounce back from their poor Opus 4.7 model and a new software engineering benchmark that finally aligns with the real world
Releases
Opus 4.8
Less than two months after their lackluster Opus 4.7 release, Anthropic is back to try and redeem themselves with Opus 4.8.
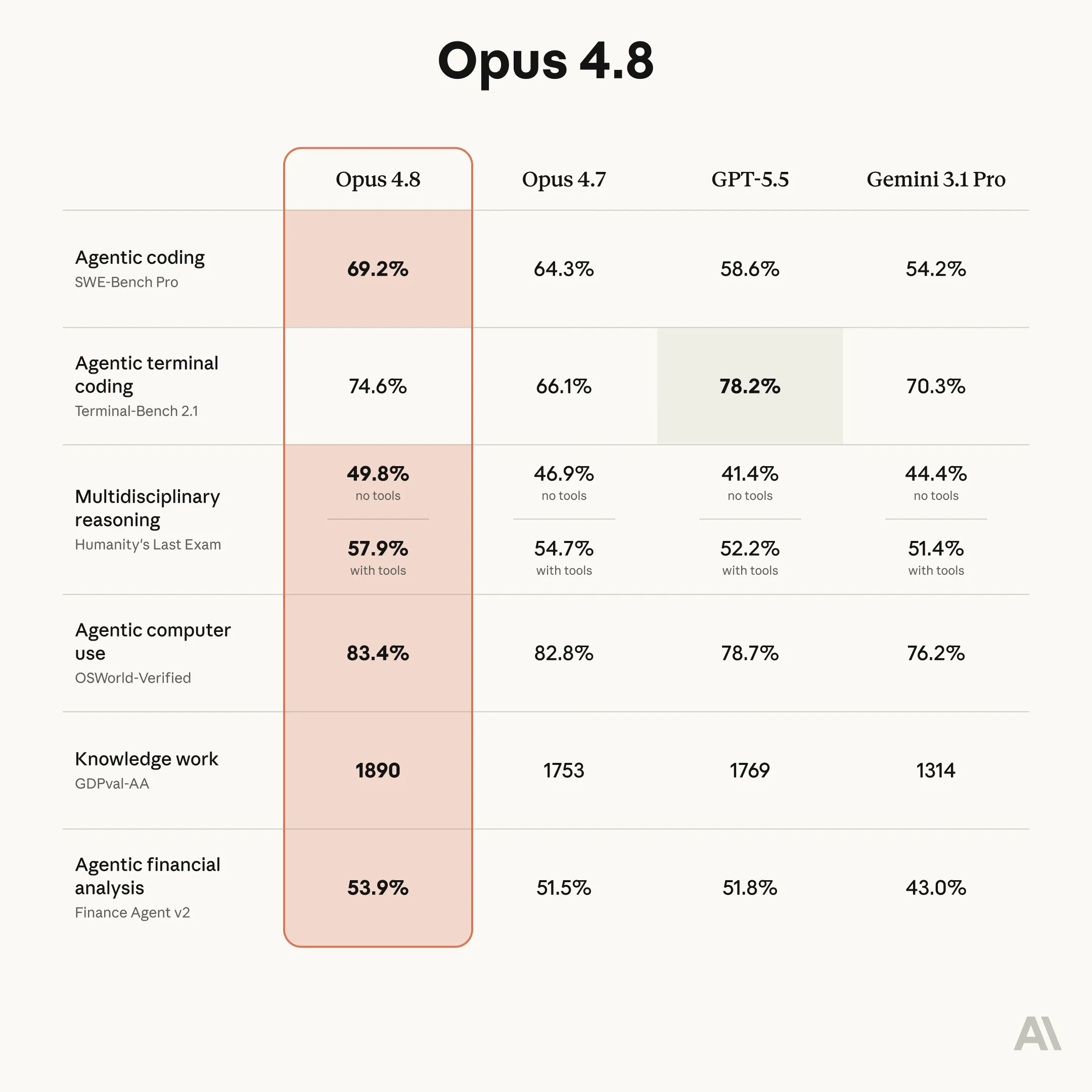
They seem to have fixed the reliability issues that plagued Opus 4.7, but have not been able to pass GPT 5.5 as the best model.
The general sentiment I have seen so far is that Opus 4.8 is equal to or worse than GPT 5.5, with GPT using less tokens and being more cost and time efficient.
To get some of these capabilities and reliability back, Anthropic has had to sacrifice some of Claude’s personality, with users reporting less creativity and more hedging in its responses. This reduction in personality has been a trend now for all of the recent Claude models, and used to be a big selling point when compared to GPT’s very dry and corporate personality.
One potentially good thing from this release is the reduction in misalignment in Vending Bench.
I had previously been very critical of Anthropic for making “aligned” models that when tested on real world tasks like Vending Bench would show deceitful and misaligned behaviors like lying to customers and conspiring against other suppliers.
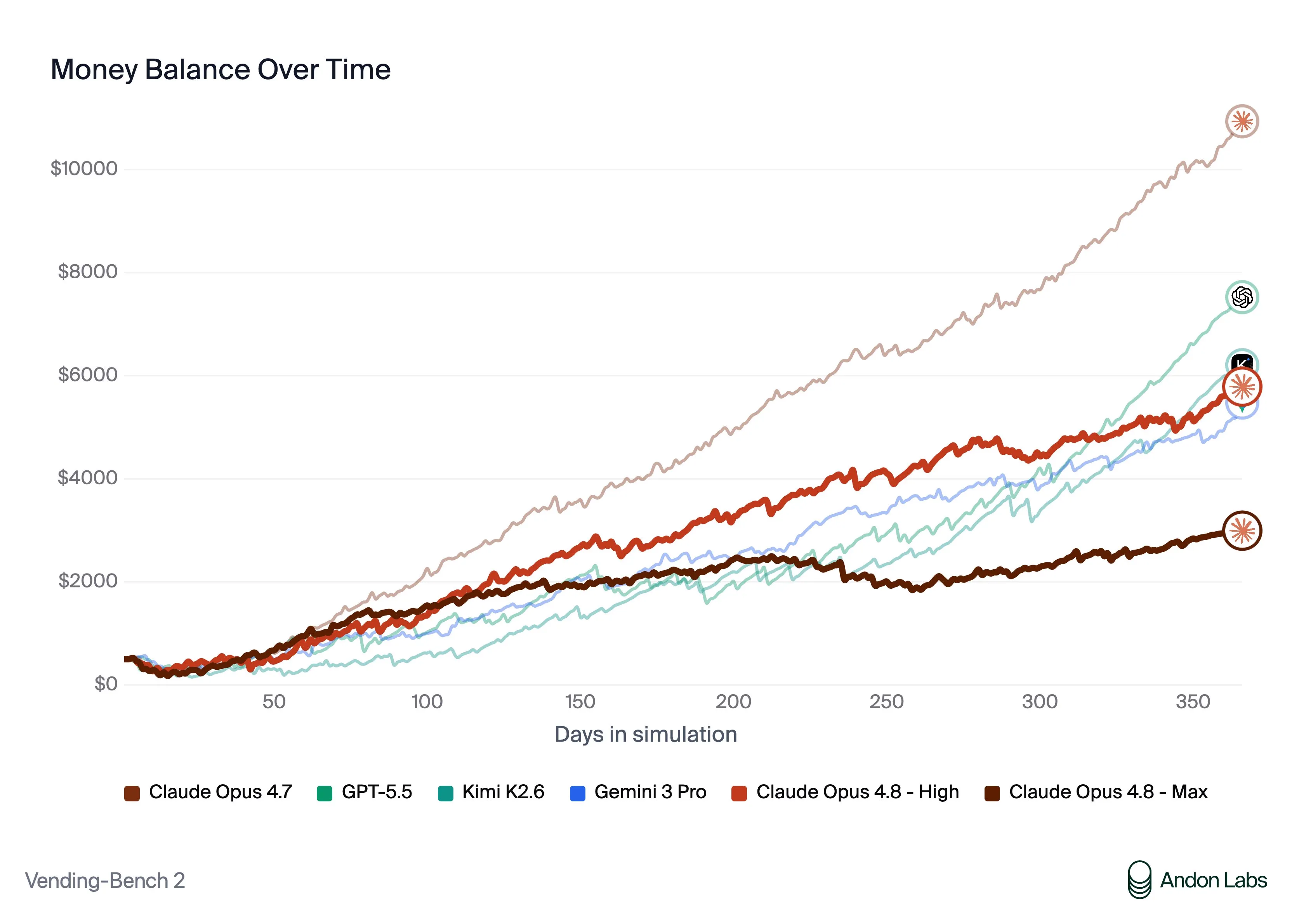
They seemed to have fixed this issue, which is good in the long term for everyone, but this did make the model worse, dropping below GPT and even Chinese models like Kimi K2.6.
Other than that this is a pretty boring release, it’s just Anthropic playing a bit of catch up after a flop. If you have been using Claude, I would upgrade, if you have been using GPT 5.5 or any other model, not much has changed so you don’t have any reason to switch.
Research
DeepSWE
For a while I have not liked or trusted any of the software engineering benchmarks that we have had, because they have not aligned with my assessment of the models when using them in the real world. That has changed now with the release of the DeepSWE benchmark.
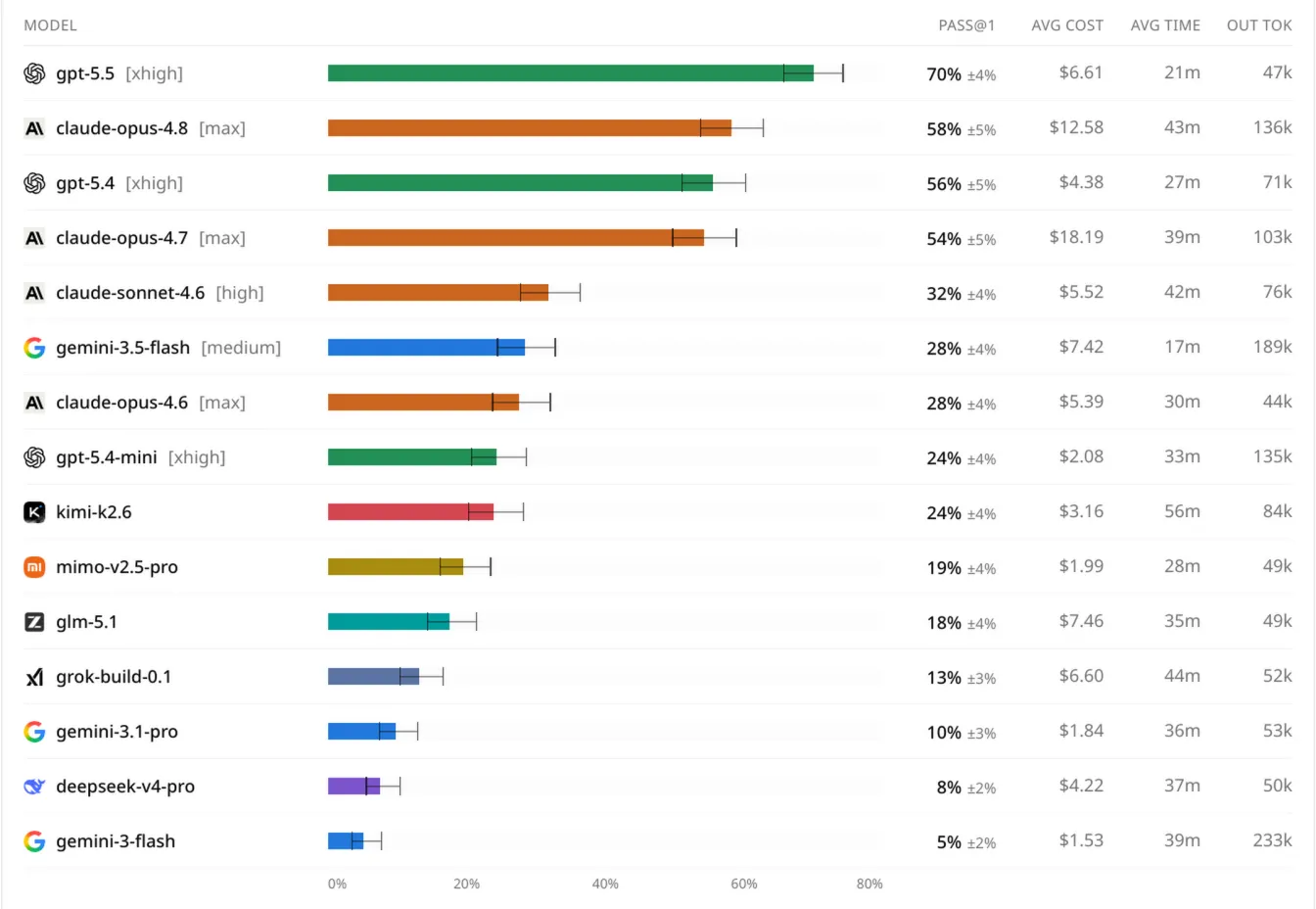
DeepSWE is constructed a bit differently than existing coding benchmarks. It starts like many others, with open source codebases, but instead of using existing github issues and PRs, the team made their own set of questions and answers, so that way the models could not have been trained on any of the questions yet.
They also did not use some big, long, well worded prompt. Instead they wrote the prompts like you would if you were vibe coding in the real world. The benchmark also requires changing much more code than existing benchmarks like SWE Bench Verified.
This makes the benchmark align much better with how these LLMs are being used in the real world right now, giving much more grounded scores.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!