PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Opus 4.7 is a flop?
Opus 4.7 is not the upgrade we expected and Qwen releases an open source model worthy of OpenClaw
Releases
Opus 4.7
Only a week after announcing the existence of Mythos Anthropic has released Opus 4.7.
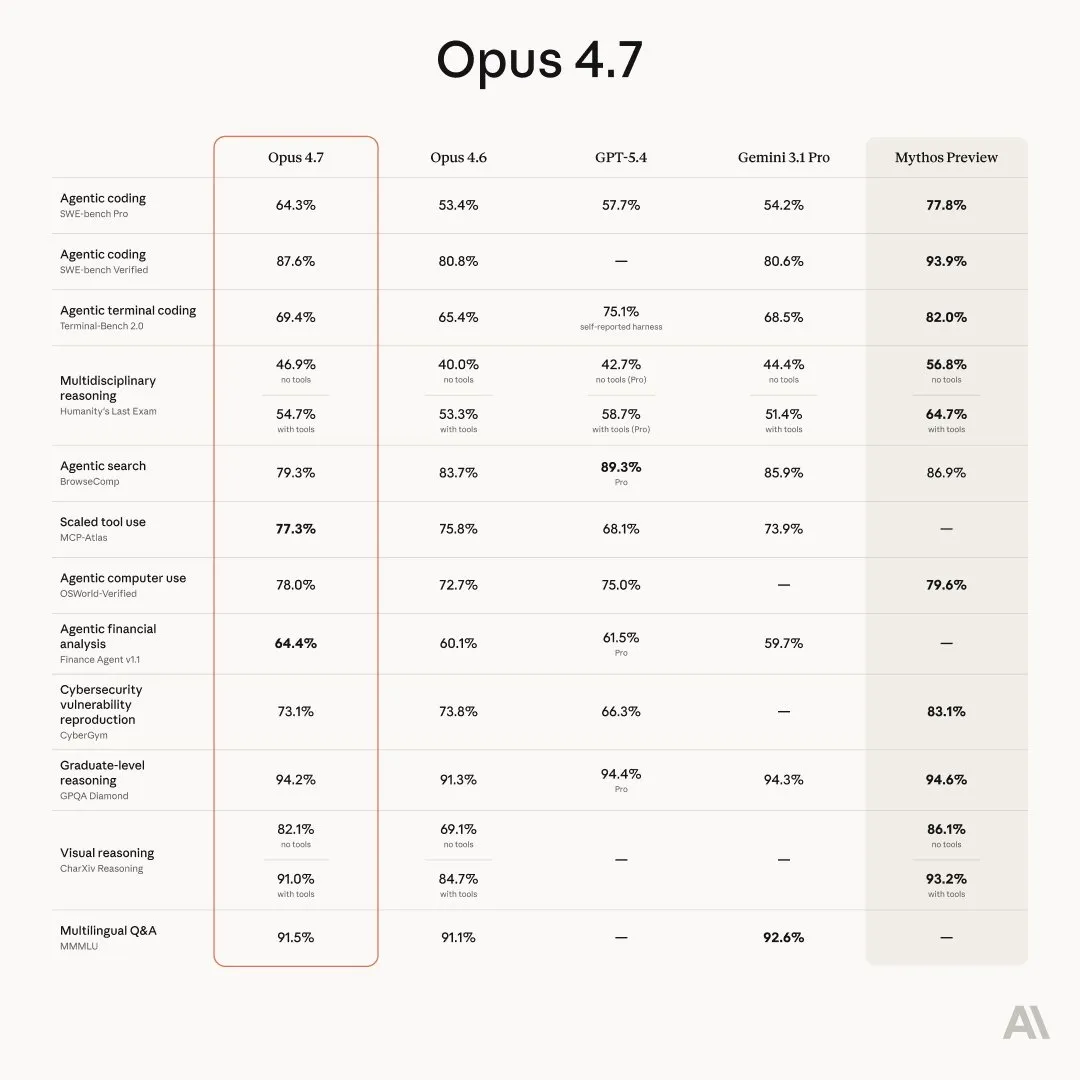
The consensus for Opus 4.7 is not as clear as previous releases. Usually a new model release is clearly better than its predecessors; this is the case for pretty much every lab (except Mistral). But for Opus 4.7 I have been seeing mixed opinions so far.
It seems to lack the level of refinement of previous Claude models. Its personality and soul are lacking, and it capabilities within Claude Code, while still good, are a bit shaky, with multiple people (including myself) running into a higher than normal number of tool call failures.
For coding the model does seem smarter, but also more unreliable, from Chubby on Twitter:
Opus 4.7 feels like a disgruntled employee whose results you can’t judge and have to check afterward. The trust you had with 4.6 is gone. It’s like hiring a new employee who had excellent grades in their application but is totally sloppy and disgruntled in practice and doesn’t follow instructions.
This seems to be due to the new adaptive thinking mode that the model uses. This allows the model to think more or less for a given query based on how hard it thinks it is. The GPT series of models has had this for a while and it has worked very well, but Anthropic seemed to have missed the mark with their implementation of it. Opus 4.7 only considers coding or STEM related tasks to be hard enough for more thinking, causing to reason less and give worse answers for almost every other domain.
For OpenAI, their adaptive thinking was for a better user experience, since users prefer faster answers. Anthropic on the other hand, being far more compute constrained than OpenAI is right now, are using adaptive thinking to save compute. From a HackerNews poster:
[Adaptive thinking is] a solved problem for the companies. It solves their problems. Not yours ;)
To add insult to injury, Anthropic also updated the tokenizer for the model, which makes it use more tokens than normal, causing it to be 20-50% more expensive than Opus 4.6 for the same number of characters.
For most people, Opus 4.7 is a sidegrade at most, trading off raw intelligence and capability for reliability. For most other use cases it seems to be a bit of a downgrade, so I would not recommend using it at this time unless it performs noticeably better for your own use cases.
Qwen 3.6 35B
Less than 2 months after the Qwen 3.5 releases, we now have our first open source Qwen 3.6 model, an update to the 35B-A3B mixture of experts model.
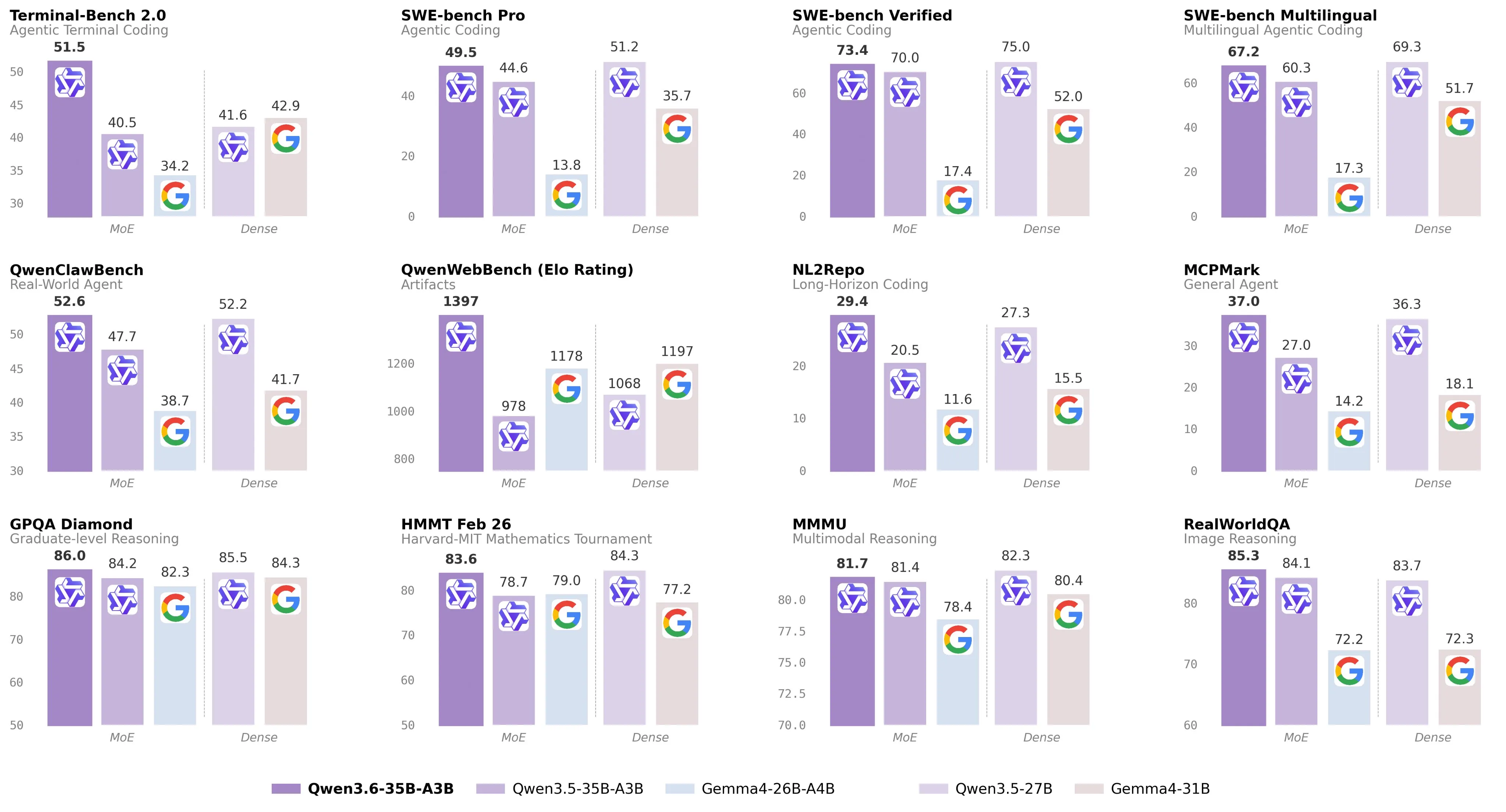
The Qwen 3.5 and Gemma 4 dense models (the 27B and 31B models in the chart above) were considered to be the first models that were good enough to be used in coding harnesses and agent interfaces like OpenClaw. This Qwen 3.6 model is able to handily beat both of its dense counterparts, while being far more efficient, making it runnable at decent speeds (>20 tokens per second) on pretty much any hardware with at least 24GB of memory.
In terms of its benchmark scores, it’s around the Sonnet 4.5 level, which is insane since it is at least one order of magnitude smaller than Sonnet, which was released only 5 months ago. If this trend continues, that means that we will have a Opus 4.6/GPT 5.4 level model that we can run at home fairly easily in 6 months.
I have been personally using this model with Hermes Agent (a OpenClaw alternative that is a bit friendlier for open source models) and it has worked fairly well with no major issues. I have seen similar sentiment from those on LocalLLaMA who have been using it as a personal agent and also as a fairly competent coding assistant.
As I said for the Qwen3.5 and Gemma 4 models, now is the best time to start using local LLMs, because they are starting to get good enough to replace OpenAI and Anthropic for easy and medium difficulty tasks.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!