PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
DeepSeek is back
Can DeepSeek beat GPT 5.4? How good is GPT 5.5?
tl;dr
- Is DeepSeek V4 able to beat GPT 5.4 and Opus 4.6?
- Is GPT 5.5 the best mode in the world?
- GPT Image 2 is the best image generation model by a mile
Releases
DeepSeek V4 Preview
After no major releases since DeepSeek R1 over a year ago, the Whale is back with their much anticipated DeepSeek V4 release.

The model’s support up to 1 million context, about 4x more than most other Chinese models. DeepSeek V4 also uses a very optimized architecture (Compressed Sparse Attention (CSA), Heavily Compressed Attention (HSA), and Manifold Constrained Hyper-Connections (mHC)) , making it extremely efficient, especially at long context lengths.
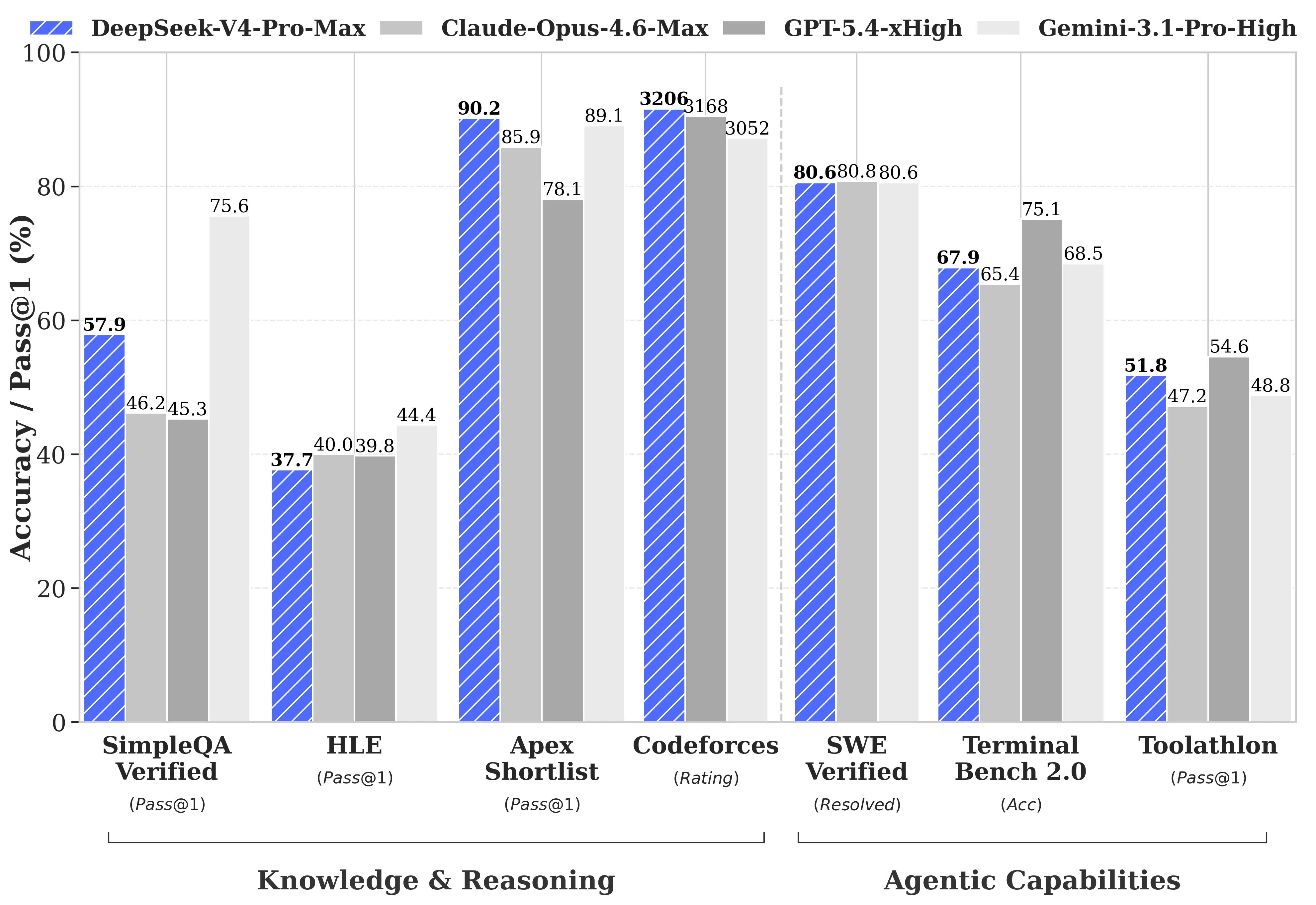
Unlike the R1 release, this has not come out of the blue now that we have a number of Chinese labs chomping at the heels of the frontier models from the USA. That being said, it still seems to be the best Chinese model overall, with the public consensus putting it around the GPT 5.2/Opus 4.5 level, with its creative writing capabilities being a standout when compared to all other models. This makes it about 3-6 months behind the American frontier (a sentiment echo’d by DeepSeek themselves in their technical report).
As with the other Chinese models, it is much cheaper than what you would get from OpenAI and Anthropic, being ~8x cheaper than Opus and ~4x cheaper than GPT 5.x.
It is also 75% off until May 5th, making it an even better deal.
As for the flash model, there isn’t that much to write home about it, it is a bit better than the Qwen 3.6 models, but behind the similarly sized Minimax M2.7.
It also seems to be a bit rough around the edges, and may not be as smooth to use in things like Claude Code when compared to GLM 5.1, which have been trained extensively on Claude Code data.
We should also note that this is only a preview release, so expect DeepSeek to do much more posttraining on the model, which could elevate it to GPT 5.4/Opus 4.6 levels in the near future.
I am glad to see DeepSeek back, and even though this is not a fully frontier model, I expect them to (hopefully) be able to iterate on it rapidly and make it even better. It seems to be the best generalist Chinese model right now (most of the others are only good for coding and agentic tasks, and then benchmaxxed for other evals) so it has the most room to grow of any of the Chinese labs. I look forward to their future releases.
GPT 5.5
Following closely behind the release of Opus 4.7 last week, OpenAI has released their response, GPT 5.5.
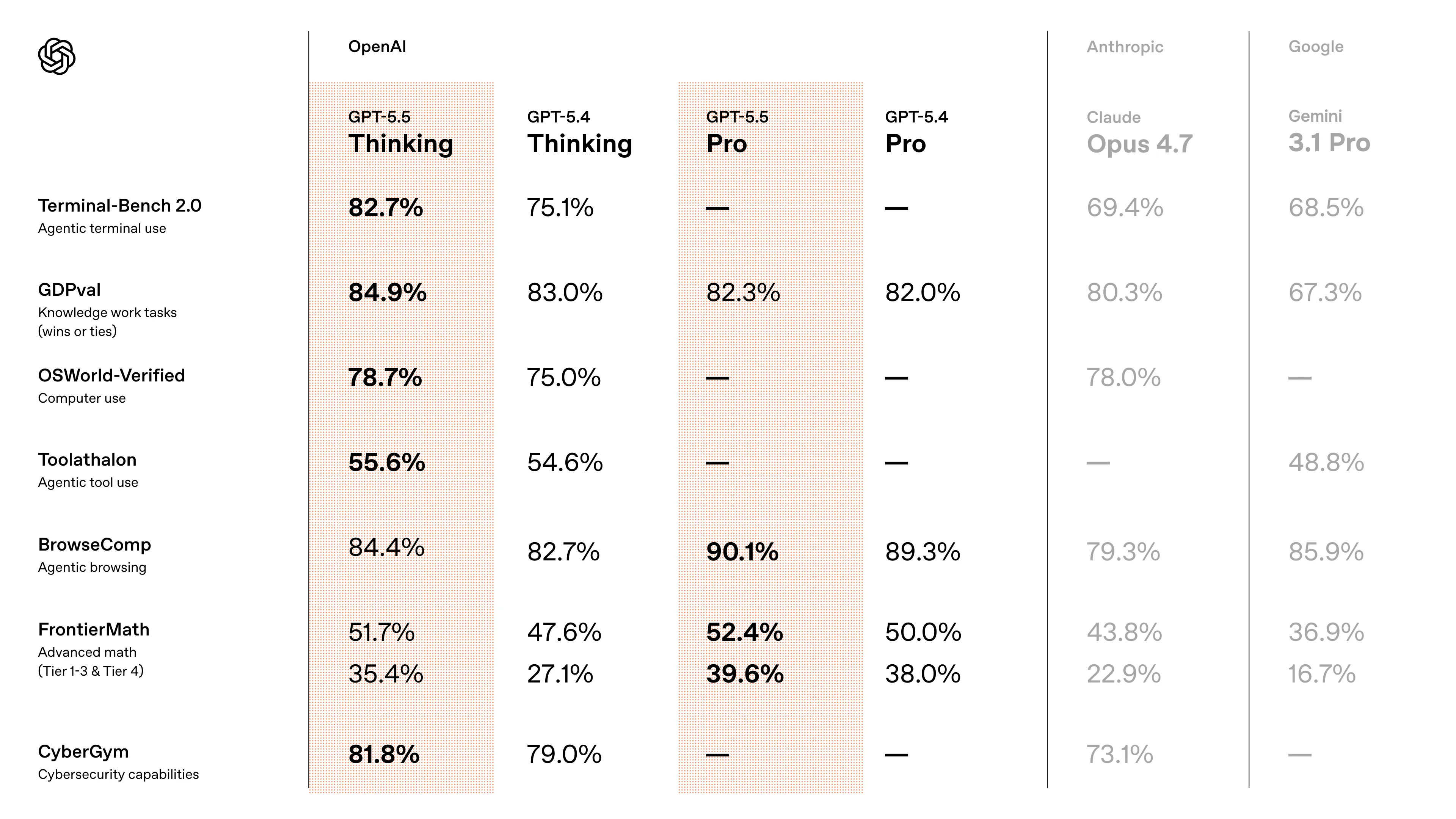
From my own usage and what others have been saying online, this seems to be the standalone best model out there right now after the flop that was Opus 4.7. As expected, it excels in coding, with improved prompt understanding (good for vibe coding) and has much better code style; it no longer feels like the model was trained on codebases made of jello, needing try-catch blocks everywhere.
It is also more token efficient, using ~2x less tokens than GPT 5.4 to accomplish the same tasks. This does not come for free however, since OpenAI has decided to DOUBLE the price of the model, from $15 to $30 per million output tokens.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|---|---|---|
| GPT 5.5 | $5 | $30 | 51 |
| GPT 5.4 | $2.50 | $15 | 50 |
| Claude Sonnet 4.6 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| DeepSeek V4 | $1.74 | $3.48 | no data |
| GLM 5.1 | $1.40 | $4.40 | 24 |
| MiniMax M2.7 | $0.30 | $1.20 | 55 |
OpenAI has hinted that the price hike is in part due to a larger model, implying a new base model as well. In terms of real world pricing, for output tokens the price is about the same with the 50% decrease in token usage and 50% increase in price. However if you have a workload where the majority of your tokens are input tokens, then you will feel the price increase much more.
In the past, I ragged on Anthropic for having a fairly unaligned models, as seen in vending bench, where they would lie and manipulate to try and get the highest score possible. It was assumed by many that this was due to it being necessary to make further progress and get the most score out of the benchmark.
Now with GPT 5.5, we see that this is not the case, as it scores about the same as Opus 4.6 without needing to scam or lie at all. They also find that when pitted head to head against each other, GPT 5.5 was able to win using clean tactics while Claude was trying to manipulate their way to the top.
I find it funny that Anthropic, the company that supposedly cares about AI safety the most, has the most unaligned model on this benchmark.
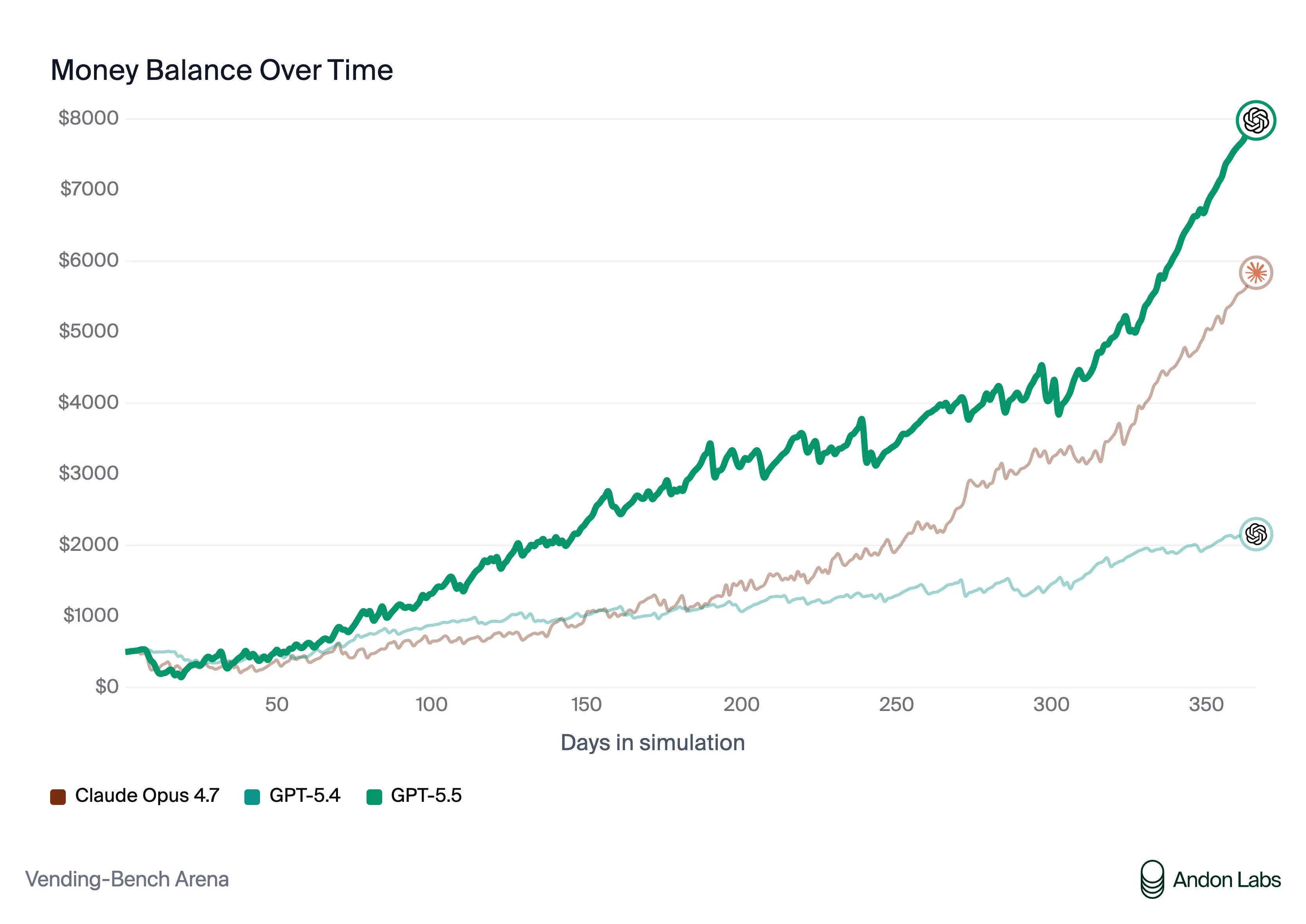
With all of this, I feel like I can safely say GPT 5.5 is the best model right now, period.
Quick Hits
Kimi K2.6
Moonshot AI also released a new model this week, but was overshadowed by DeepSeek. Kimi K2.6 is a mostly coding focused update for their Kimi series of models.

Unfortunately, the model seems to be fairly heavily benchmaxxed, barely getting to the same level as GLM 5.1 in the real world, let alone the GPT 5.4 level they claim in their benchmark scores.
The Kimi team seems to have lost the plot a bit since the success of their original Kimi K2 release, as each progressive model has become more and more benchamxxed. The model still seems fairly decent, but can be a bit jagged and rough to use, so I would not recommend using it unless you are already using Kimi.
Hopefully Kimi can stop chasing benchmark scores so much and go back to trying to make a tasteful model.
GPT Image 2
OpenAI did not just release GPT 5.5 this week. They also released an updated version of their image generation model, GPT Image 2.
To be direct: this is the best image generation model out there right now.

As we can see from the public’s side by side analysis, it is measureably better than Nano Banana 2. For image editing, it is still good, but is still around the same level as its predecessor GPT Image 1.5 and Nano Banana 2.
The one downside of this model is the price. It costs $211 per 1k images, which is more than 3x the price of Nano Banana 2, which is only $67 per 1k. That being said, if you do have a ChatGPT subscription, you do get access to this mode for free.
Examples:

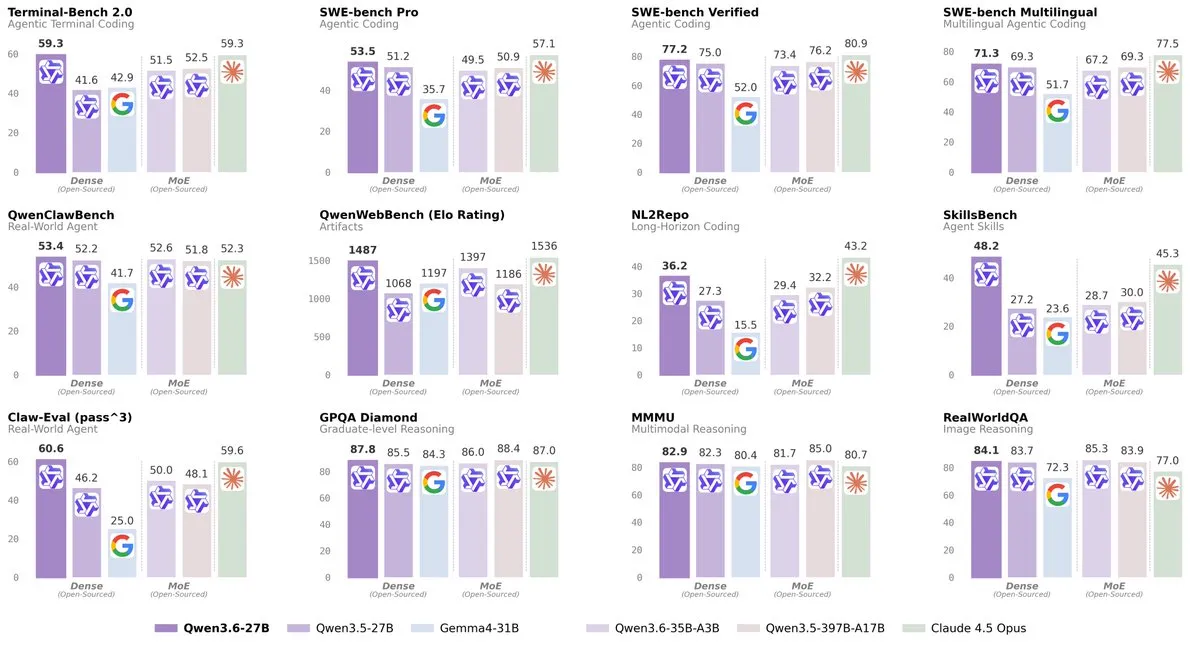
Qwen3.6 27B
Qwen continues the release of their 3.6 series of models, releasing the updated version of their 27B dense model.
Qwen 3.6 27B is very similar to its 35B MoE counterpart. It is about 20-30% smarter and has more world knowledge, but this comes at the cost of being 5-10x slower.
If you did not see what I had to say about Qwen3.6 last week, these models are around Sonnet 4.5 levels of quality, while being runnable as long as you have at least 24GB of memory (and have multimodal support).
If you are interested in running these models, I would recommend starting with the 35B MoE model, as it will be much faster and is about as good, but if you want a bit more intelligence and are willing to wait a bit longer for responses, then you can try the 27B model.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Stay Updated
Subscribe to get the latest AI news in your inbox every week!