PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
How good are GPT 5.4 Mini and Nano?
Can the small GPT 5.4 models beat their Chinese counterparts?
Releases
GPT 5.4 Mini and Nano
OpenAI has neglected to update their smaller models, GPT Mini and Nano, for the last 3 versions. This week we finally got an upgrade for them with the release of GPT 5.4 Mini and Nano.
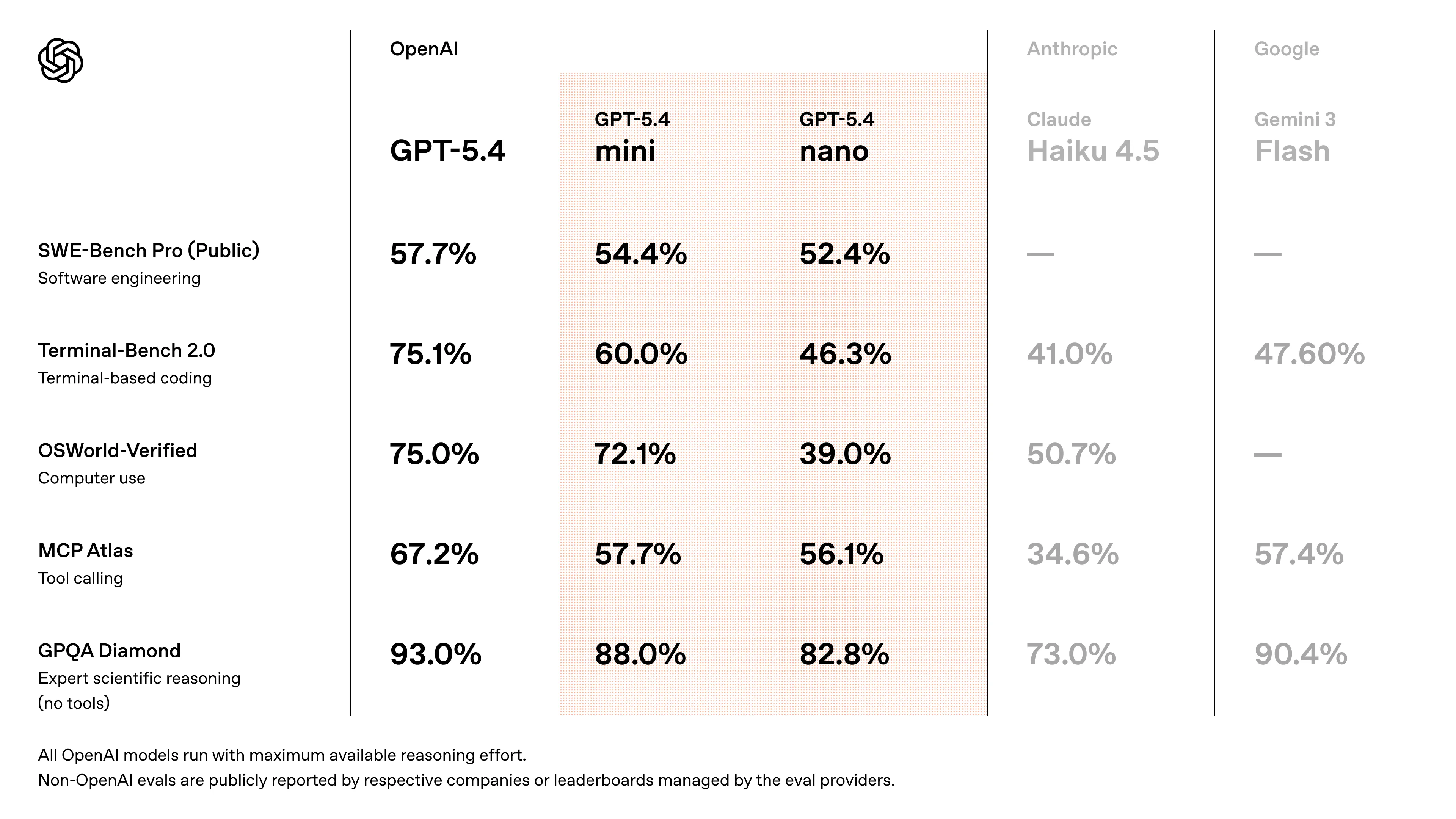
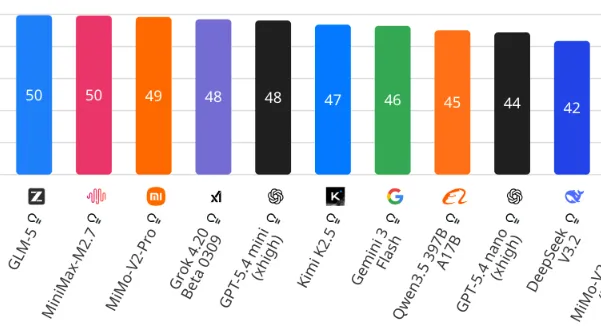
The mini model (when using extra high reasoning) sits around Gemini 3 Flash and the Chinese frontier models in terms of benchmark capabilities. The issue is that when you have reasoning turned up this high, the number of tokens used starts to get ridiculous.
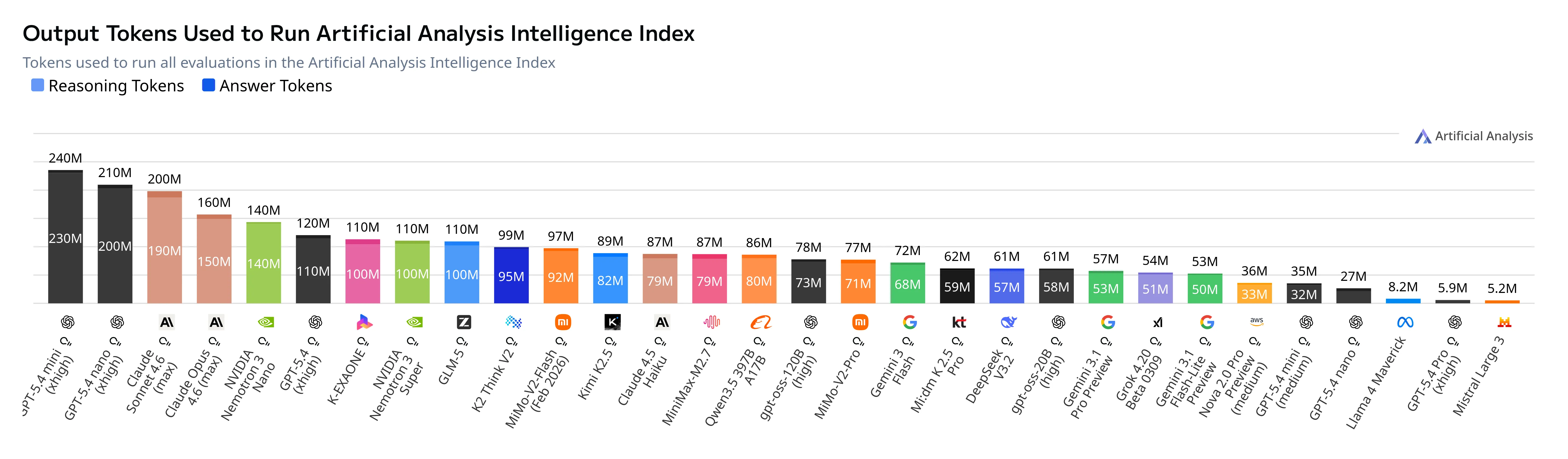
With a more sane medium reasoning, the models perform noticeably worse than their counterparts in the “cheap but good” model category.
This gap is further exacerbated when you look at the pricing for these “affordable” OpenAI models, which have ~doubled in price versus the GPT 5 Mini and Nano models.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|---|---|---|
| GPT 5.4 | $2.50 | $15 | 50 |
| GPT 5.4 Mini | $0.75 | $4.5 | 62 |
| GPT 5.4 Nano | $0.20 | $1.25 | 57 |
| Claude Sonnet 4.6 | $3 | $15 | 37 |
| Gemini 3 Flash | $0.50 | $3 | 80 |
| GLM 5 | $1 | $3.20 | 30 |
| MiniMax M2.7 | $0.30 | $1.20 | 34 |
GPT 5.4 Mini uses 3x more tokens per question to have the same performance as MiniMax M2.7, while being 3x more expensive (not counting the extra costs of 3x more tokens). This also means that even though it looks 2x faster based on tokens per second, it is actually 50% to generate a response.
Because of this, my recommendation is to generally avoid these models, as you can get better models from other domestic providers (Gemini 3 Flash) or from Chinese labs.
This also asks the question: is OpenAI really that far ahead? Or have they just scaled their models more than the Chinese labs have, since it seems that in the <1 trillion parameter category the open models are keeping up or even exceeding what OpenAI can do.
MiniMax M2.7
Speaking of Chinese labs, let’s talk about MiniMax’s new model which we teased earlier.
MiniMax M2.7 builds on their previous popular cost effective M2.5 model, being a relatively lightweight 220B parameter mixture of experts model. Unlike OpenAI, they are not increasing the model’s due its increased performance.
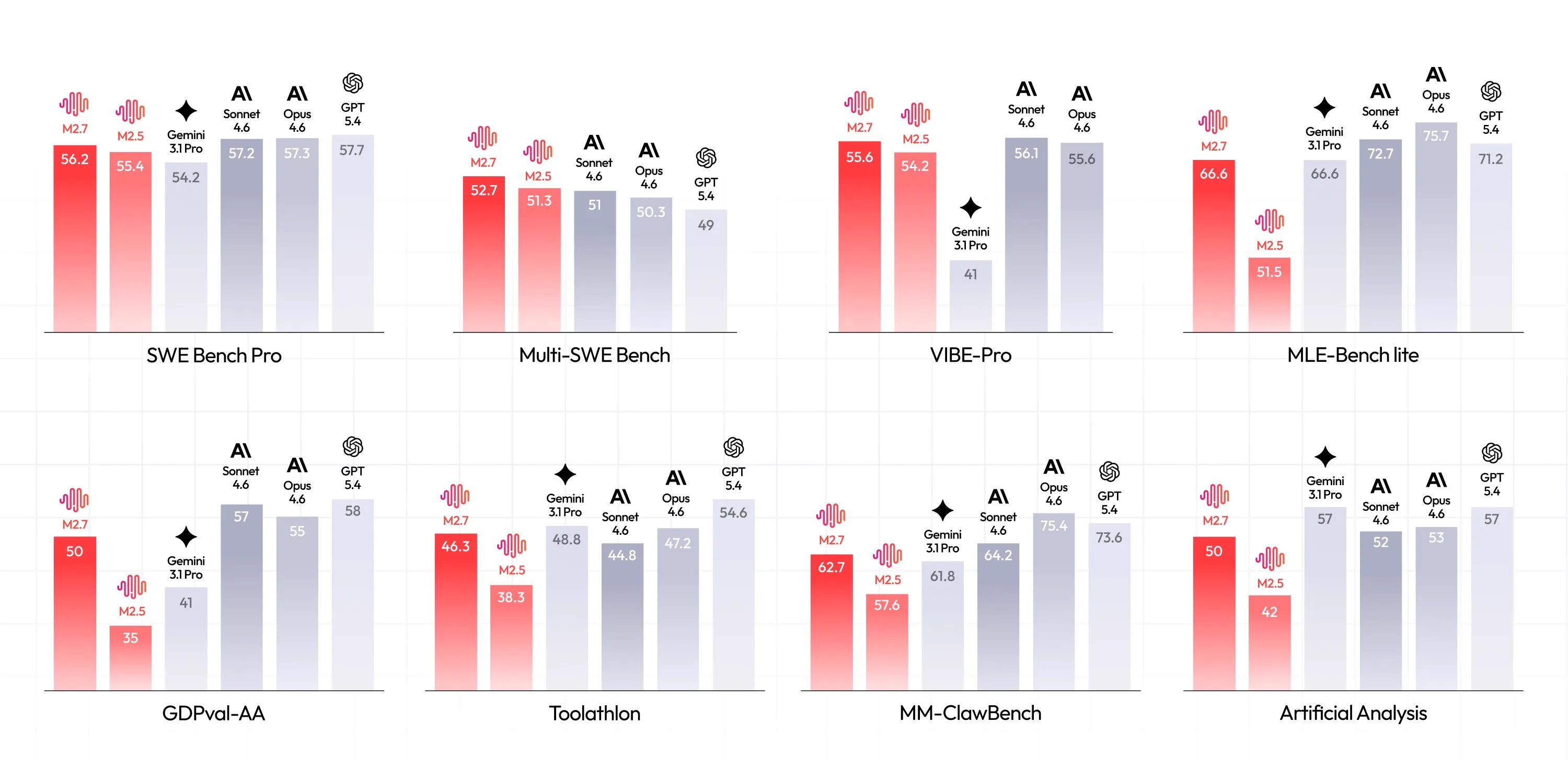
Similar to GPT 5.3 Codex M2.7 was used to help build itself, with an early checkpoint helping with 30-50% of the reinforcement learning teams workflows, highlighting its abilities for coding and general agentic tasks.
They also have been working on the model’s character and personality, making it much more pleasant to talk with. I do not think it is at the same personality level of Claude or Kimi, but it is right below them and they seem to be making big strides.
Because of the improved agentic capabilities, personality, and very low cost, it is probably the best model to use with OpenClaw (see pricing table above). If you are a true power user, or just prefer a monthly subscription plan instead of using the API, they have a $10/month plan that gives you 1500 requests every 5 hours (4 requests per minute).
If you want a strong, cost effective agentic model, MiniMax M2.7 looks like the go to. I will probably be using this as my default for agentic projects now instead of Gemini 3 Flash go forward.
Quick Hits
Cursor Composer 2
Cursor released their own trained in house agentic coding model Composer 2.
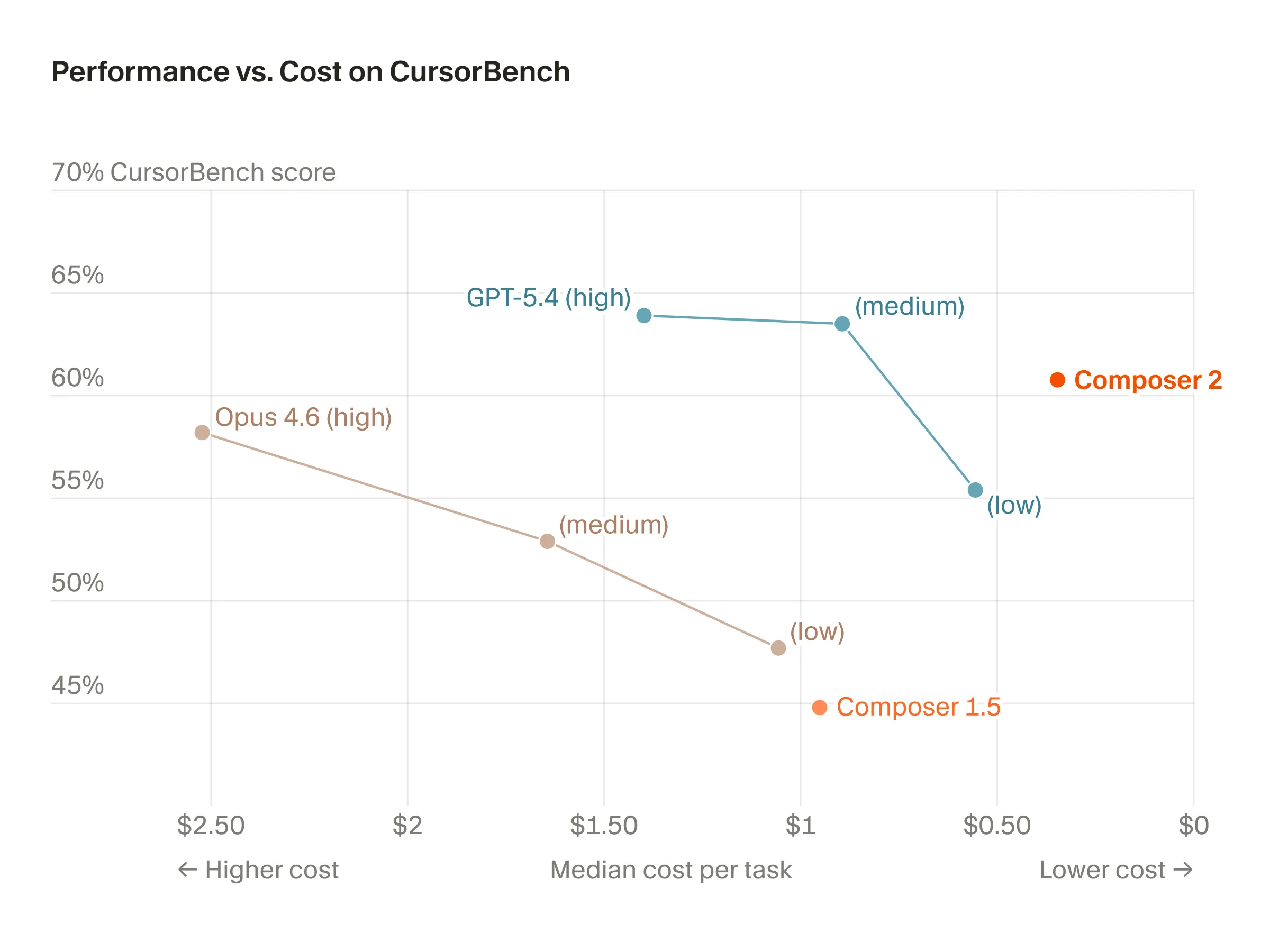
They did not train the model from scratch, instead starting from Kimi K2.5 as a base, doing continued pretraining on it and then their own finetuning as well. This was a bit controversial at the start, since they did not disclose this, but the community was able to figure it out from some internal model naming, and Cursor has confirmed this themselves as well now.
Because of all of the drama surrounding the model, I have seen very little about its capabilities at this point (I also don’t have a Cursor subscription). If you do, I would say check it out, it is very cheap (although only accessible through Cursor, no API access available) and a few of the other benchmarks I have seen for it seem to imply that the model is fairly decent.
Mistral 4 Small
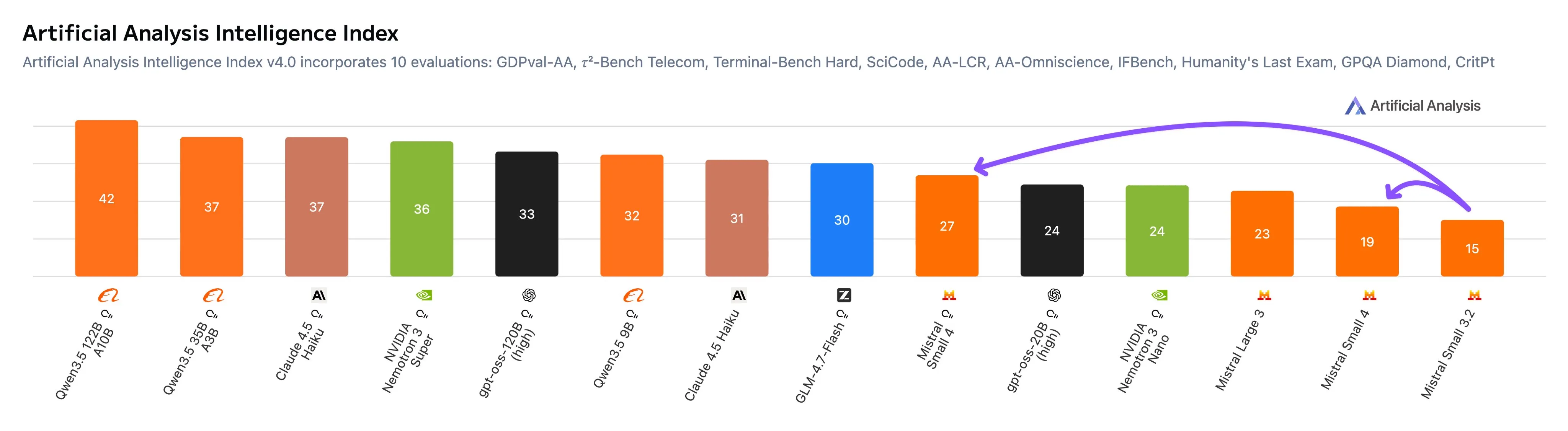
Mistral released the first model in their Mistral 4 lineup, called Mistral 4 Small. It is a 110B parameter MoE model, with 6.5B active params.
The small naming is very apt, since it is competitive with the new Qwen3.5 Small models. The only thing is that the Qwen 3.5 models are 100x smaller. Sadly for Mistral this model is very dead on arrival, not even beating models half its size from 3 months ago.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!