PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Gemini 3 Takes the Stage
Gemini 3, GPT 5.1 Codex Max, Nano Banana Pro, and more!
tl;dr
- Gemini 3 is here, is it the best model to use?
- Nano Banana Pro crushes the competition
- GPT-5.1 Codex Max is a big step up in performance
- And much more!
Releases
Gemini 3
Google’s long awaited Gemini 3 model is finally here.
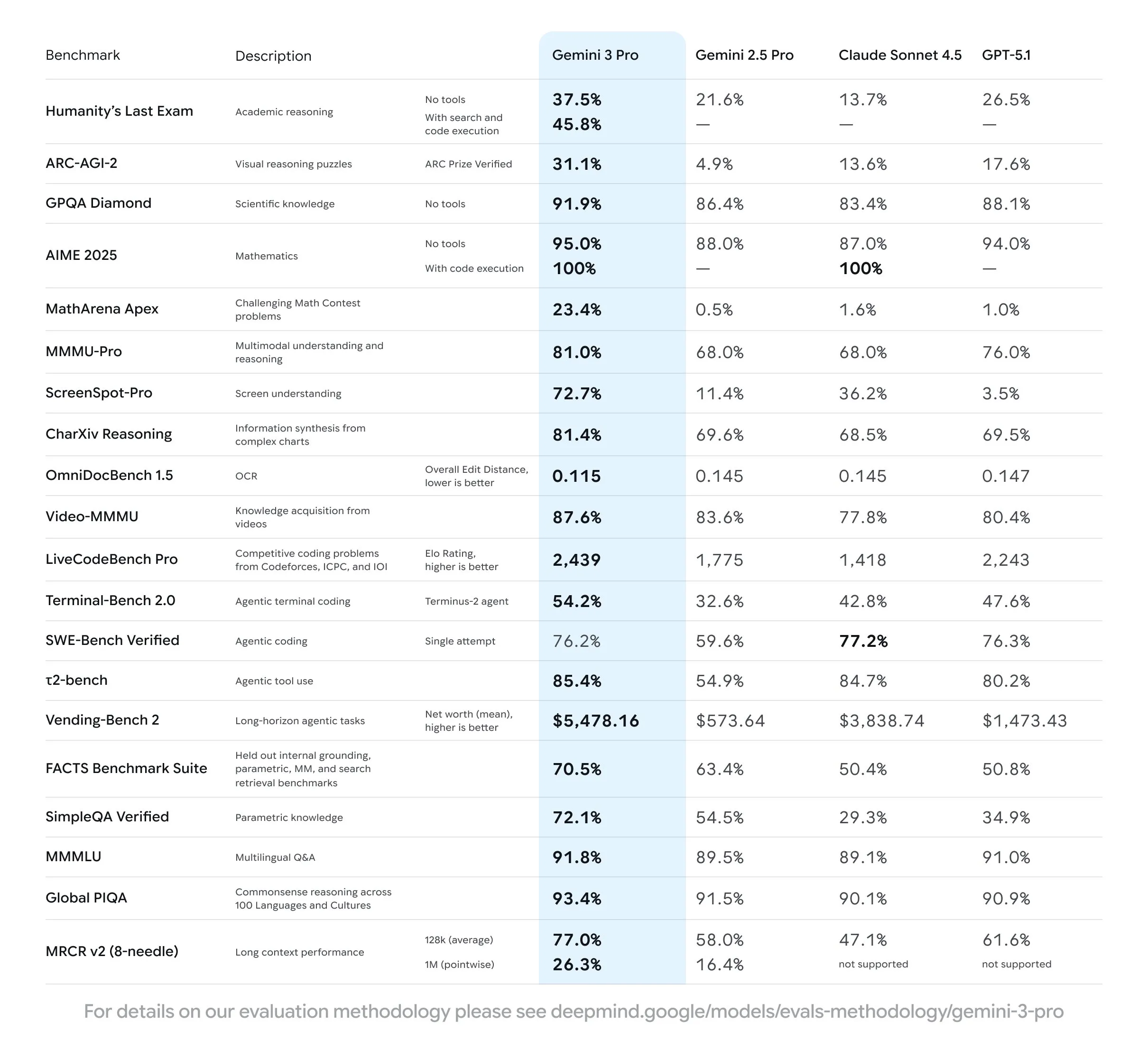
Let’s start with the good. What categories is Gemini 3 the definitive best in?
The first and most apparent is frontend design. In the frontend design arena, it is a full 100 ELO higher than the next best model.
The next category is multimodal understanding, which is unsurprising since Gemini 2.5 was already SOTA for this. Like Gemini 2.5, it can handle image, audio, and video inputs. OpenAI and Anthropic don’t seem very keen on multimodal capabilities for their models, allowing Gemini to easily take the throne.
The final category is overall world knowledge. We will go more into depth on this in the new hallucination benchmark news later on, but essentially world knowledge seems to be directly correlated with model size, meaning that Gemini is most likely the largest model that you can use right now.
Gemini has the most awareness of what has happened in the past, and also its knowledge of obscure facts is also the best of any model, most likely due to the pretraining data that Google has been able to put together for it along with its very large size.
Despite its presumed size, it is actually a fairly fast model, with about double the tokens per second as GPT-5. This is most likely due to the MoE architecture that they are using, and also potentially the performance difference of TPUs vs GPUs, but that is mostly speculation since we don’t have any way to measure the underlying model’s size from the outside.
As for pricing, it falls in between Sonnet 4.5 and GPT-5, while being noticeably faster than both.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|---|---|---|
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5 | $1.50 | $10 | 34 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
This is via the API, unlike Anthropic and OpenAI, Google gives out a decent amount of free usage through AIStudio for chatting and the Gemini CLI for agentic coding. The specific rate limits for these are not known yet as they are just getting rolled out, but seem to be fairly generous in my testing so far.
For coding, the model seems to be very usable, around the level of Sonnet 4.5, but it is missing the insane attention to detail that GPT 5.1 Codex has. Like I mentioned before it is by far the best model out there for frontend design, so I would use it for that at the very least.
The model is definitely still a Gemini model, as it still has the depressed tendencies that Gemini 2.5 had when it was unable to solve a problem, and in general is an LLM that is not afraid to let the user know its frustrations.
As for most of its other capabilities, it is around the frontier level of GPT-5.1 and Sonnet 4.5. You can see this sentiment in this Twitter thread, where you can find users with complete opposite opinions as one another for many of its more general capabilities, showing that it is dependent on prompt and output style more than the model’s direct capabilities. I talk more about this phenomenon at the end of my Kimi K2 Thinking review if you want to read more about it.
A final note, one of the researchers said that the increase in capabilities for Gemini 3 is just due to better pre- and post-training, and there was nothing that fancy used to make the model, showing that the scaling laws that we have been using the past few years still hold as we enter the realm of truly massive LLMs.
GPT-5.1 Codex Max
In response to the Gemini release this week, OpenAI released an updated version of their GPT-5.1 Codex models called GPT-5.1 Codex Max. Despite the name, it is not a single model but the new flagship family of models to be used in Codex.
It comes in the usual variants of low, medium, or high reasoning, which means the full name of each model is something like GPT-5.1 Codex Max High (not a confusing naming scheme at all).
In addition to the usual reasoning variants, they also released an extra high reasoning version for the hardest tasks. The medium reasoning is still recommended as the default go to, and what I personally use, but if you find the model struggling you can bump it up to the higher reasoning levels using the /model command in the Codex CLI.
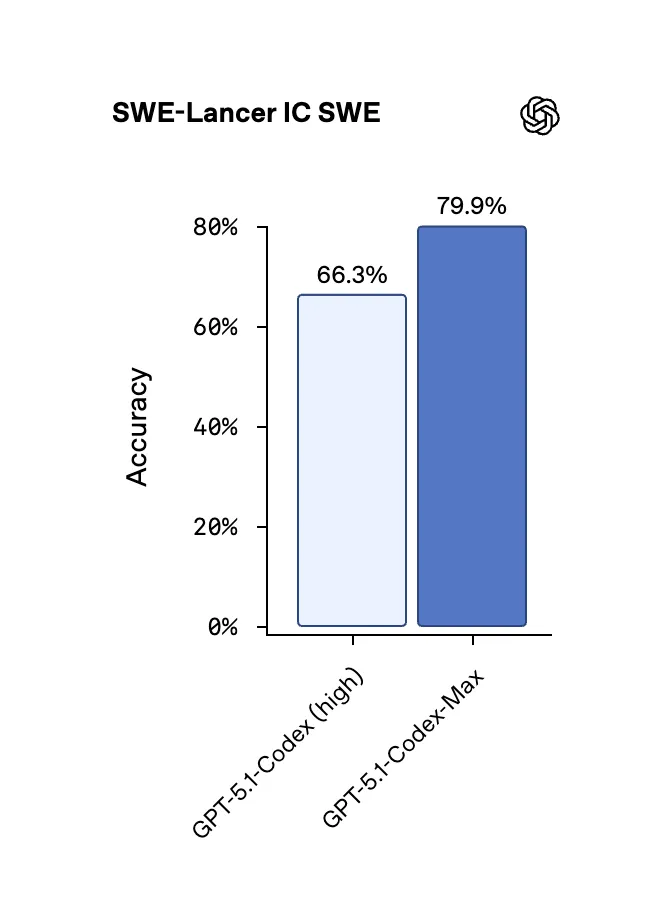
Despite the weird model naming, this is a non-trivial step up in performance, both in terms of quality and also speed.
One of the main gripes that I and many other people have had with Codex is its slow speed when compared to other models like Claude 4.5 or GLM 4.6. With this latest version however, I no longer have the 10+ minute waiting time for the model to finish working, and now instead the average time is around 2-3 minutes for similarly difficult prompts. It manages to do this while still keeping its attention to detail and thoroughness that make it the best model out there right now.
Nano Banana Pro
Gemini was not the only major release Google had this week, as they also dropped an updated version of their popular Nano Banana model.
The new pro version frankly blows ever other image generator and editor out of the water, beating the second best model by over 40 ELO in image editing and 80 ELO in image generation.

The model is built on Gemini 3, so it has great world knowledge. Because it’s based on an LLM, it can also use tools (like search the internet) to get more info for the image it will generate. For instance people have been using it to make detailed infographics of research topics or sports games that happened the previous night. It also can make architecture diagrams based on your code base. It also has limited safety features right now (for better or worse), allowing you to make images of famous politicians and celebrities.
The one downside of the new model is its cost. The original Nano Banana cost just under $0.04 per image, while the new version is now $0.15 per image, making it one of the pricier image generation models out there.
It can also generate 4K images, similar to Seedream 4, but those will cost double, at $0.30 per image.
I will leave you with a selection of examples from the model, there are also a bunch of examples on Twitter right now if you want to see more.


Research
Hallucination Benchmark
Hallucinations are a big problem with LLM’s, and we have very few public benchmarks that try to measure this.
The gang at Artificial Analysis have noticed this as well, and have released their own benchmark to try and measure this themselves with their AA-Omniscience benchmark.
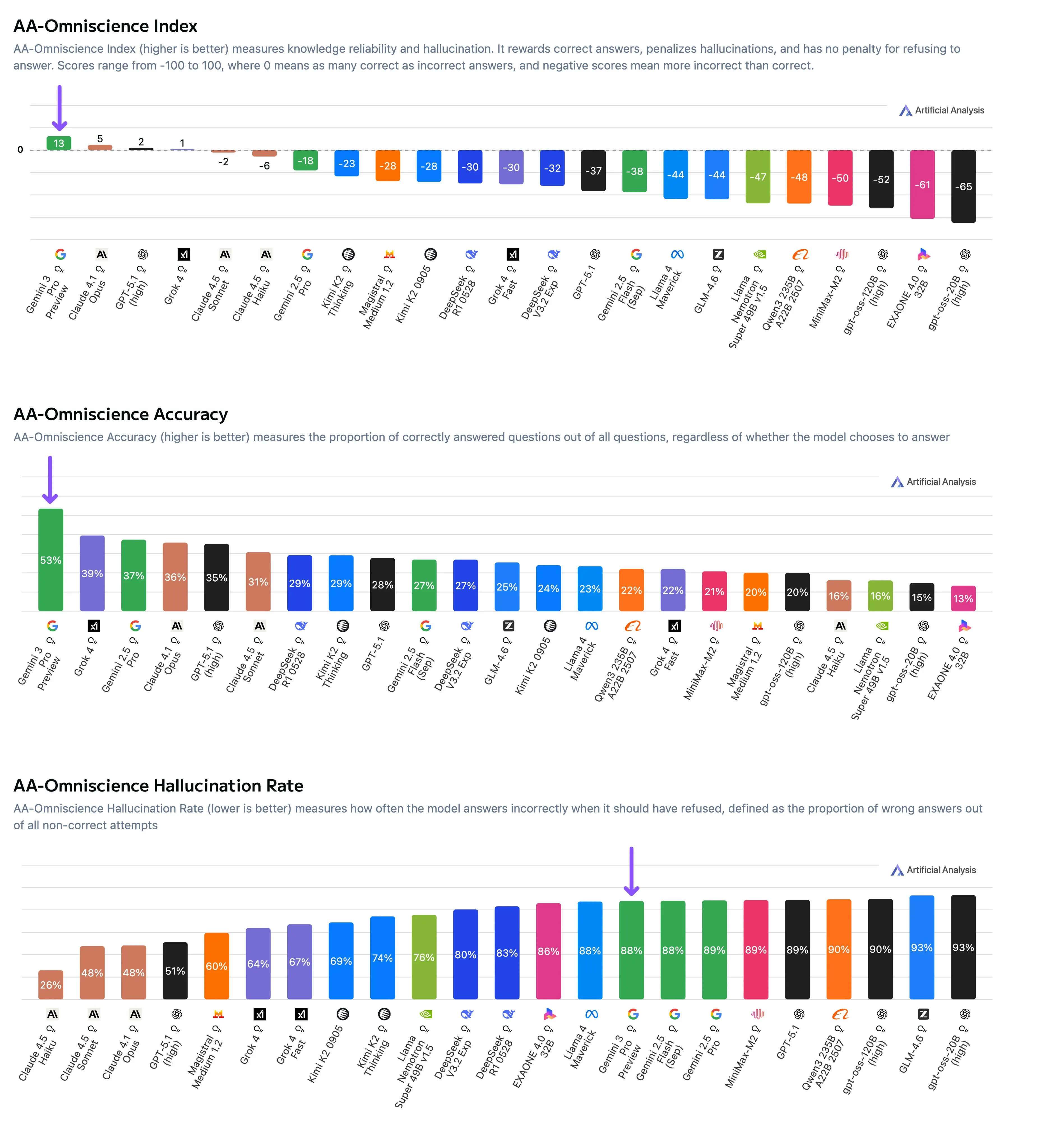
The benchmark consists of 6000 questions across 6 domains and 42 topics. The models do not get access to any tools, and must answer (or not answer) based on their internal knowledge.
The models are measured across 2 different axes, the first being accuracy, and the second being hallucination rate, which is defined as the model answering a question incorrectly instead of saying “I don’t know”. These 2 scores are combined together, with a correct answer being worth 1 point, a hallucination being worth -1 points, and not answering a question is worth 0, so a positive score means the model answered correctly more often than it hallucinated.
They found that only 4 models got a positive score, and most models had a hallucination rate over 50%. The top scoring Gemini 3 rates the highest on the benchmark, not due to its low hallucination rate, but instead its vast world knowledge.
An interesting insight the team found was that for the open source models (where we know the size of the model), the size of the model directly correlated with accuracy, while the hallucination rate did not, which shows that world knowledge in LLMs is a function of size, while hallucinations are based more on the data itself.
This means that small, local models will not have a large amount of world knowledge, but we should still be able to train them to have a low hallucination rate.
Quick Hits
Sam 3(D)
Meta has released a new version of the Segment Anything models (SAM), called SAM 3D.
The release has 2 model types, one for object and scene reconstruction, and another for human body pose and shape estimation.
These models are much heavier weight than the previous SAM 2 models, so they cannot really be used on edge devices or deployed for real time applications. That being said, they are able to do 3D reconstruction from a 2D image better than any other model out there right now, on top of also being the best 2d segmentation model as well.
Olmo 3
Allen AI, an American open source AI research lab, has released their Olmo 3 series of models.
They are as good as the Qwen3 models, while being fully open in their training, meaning all of the data and checkpoints are public to look at.
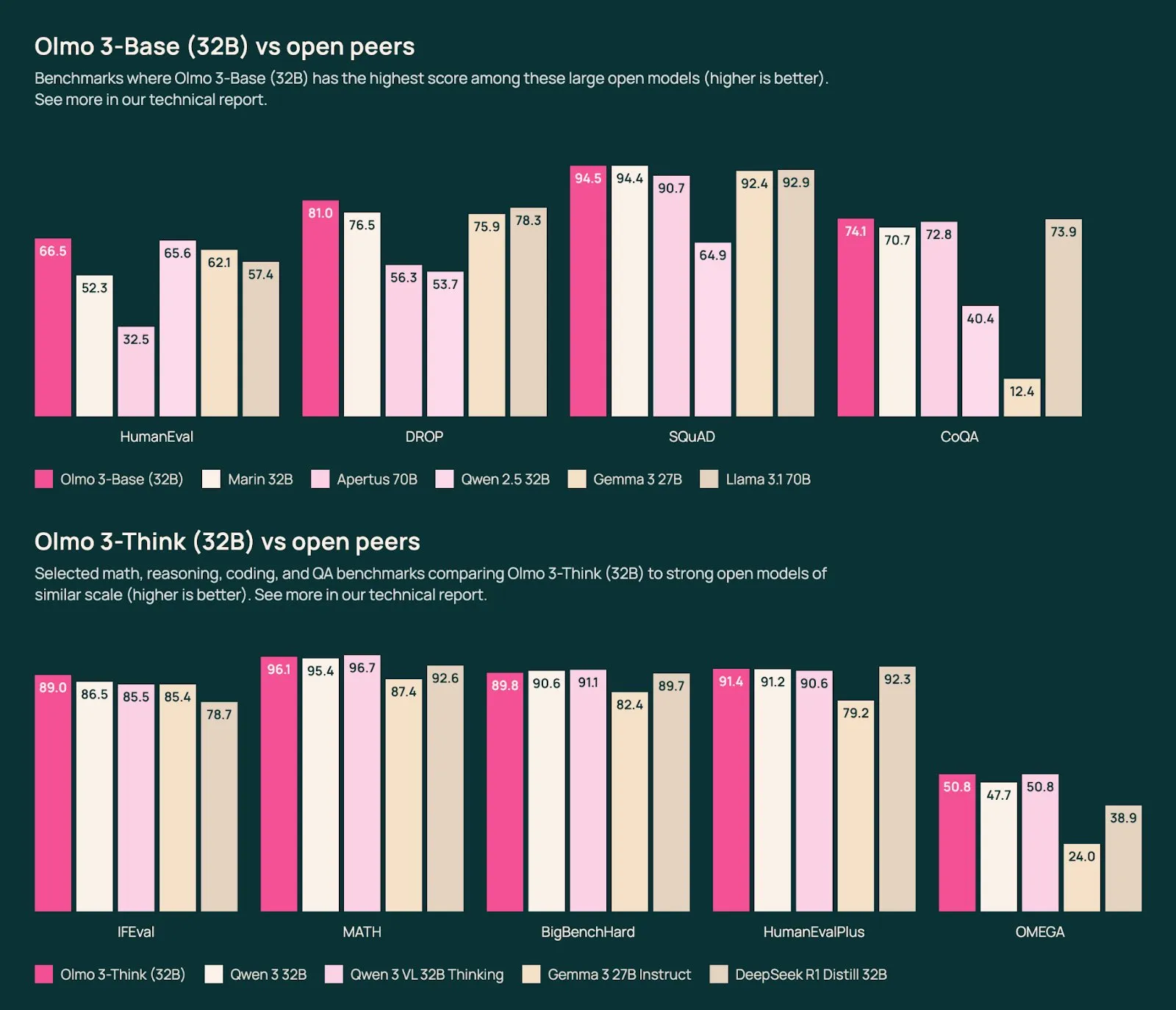
In a quieter week of AI news this would have a full writeup, so I highly suggest reading more about it if you are interested in frontier model training, or want to run open source models made in the US instead of China.
Also check out the 8B parameter Deep Research model they open sourced which is similar quality to ChatGPT Deep Research.
Misalignment from reward hacking
Anthropic released a blog showing that when a model learns to reward hack in a given RL environment, it causes much broader misalignment for the model as a whole, very similar to what many AI doomers said would happen. Anthropic then found that this behavior is very easy to mitigate, as you can just adjust the system prompt to avoid broader misalignment.

Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!