PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Kimi K2 is on top
Kimi K2 Thinking is released, Llama.cpp gets some big upgrades, and an AI scientist that can work for days
tl;dr
- Kimi K2 Thinking becomes the top open source model
- Llama.cpp gets much easier to use
- A startup claims to have made an AI agent that can work for multiple days straight
Releases
Kimi K2 Thinking
Moonshot AI has released the thinking version of their already strong Kimi K2 model.
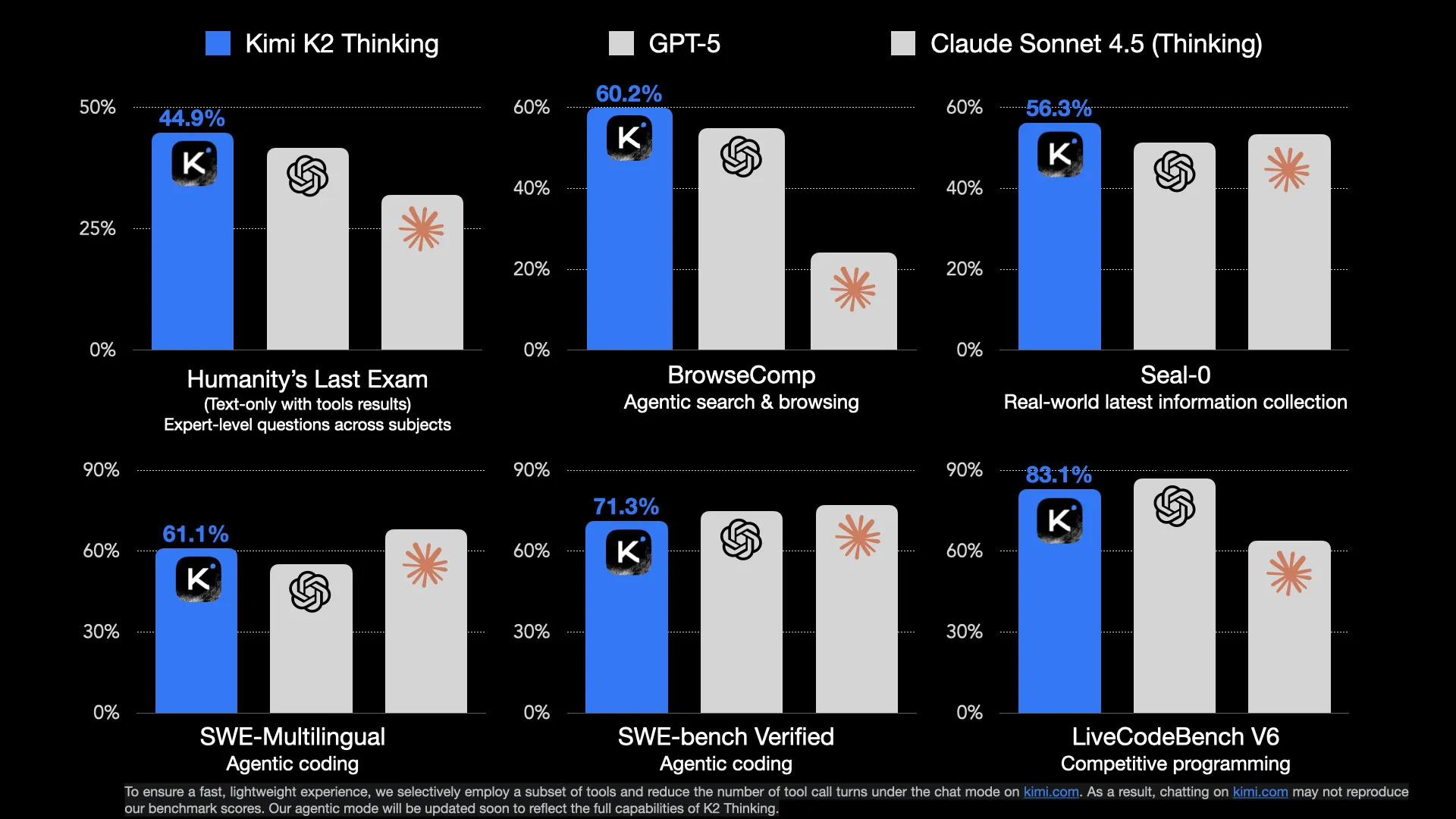
The model is still the 1 trillion parameter behemomouth mixture of experts model from before with 32B active parameters. The model was trained using quantization aware training to allow it to be deployed at 4 bit without suffering much performance degredation. All benchmarks released by the team are for the INT4 model.
It contiues to be the best model in terms of writing, somehow outdoing its predessor instruct model which was the previous best. It also continues to be the most unique LLM in terms of personality and general writing style, being drastically different from the slop pretty much every other major LLM has.
This version of the model the Moonshot team really worked on the agentic capabilities of the model, which were lacking in the instruct model. It seems to not necessarily be on the same level as GPT-5 and Sonnet 4.5 for agentic coding, but for more general agent use cases it seems to be able to hold its own.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|---|---|---|
| GLM 4.6 | $0.60 | $2.20 | 90 |
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5 | $1.5 | $10 | 34 |
| Kimi K2 Thinking | $0.6 | $2.50 | 25 |
| Kimi K2 Thinking Turbo | $1.15 | $8 | 107 |
The main issues with the model are speed and token usage.
The model is cheap, at only $2.50 per million output tokens, but at 25 tokens per second it is slower than even the glacial GPT-5 (those that have used GPT-5 in Codex know what I mean). For agent tasks this is unacceptably slow. You could switch to the Turbo endpoint, but then the price becomes similar to GPT-5, which defeats one of the main purposes of these Chinese models which is that they are very cheap.
Also Kimi K2 Thinking has an issue most other first generation reasoning models have which is extrmely long thinking traces. Specifically, Kimi K2 seems to have the longest chain of thought processes of any reasoning model, as shown by the Artifical Analysis benchmark below.
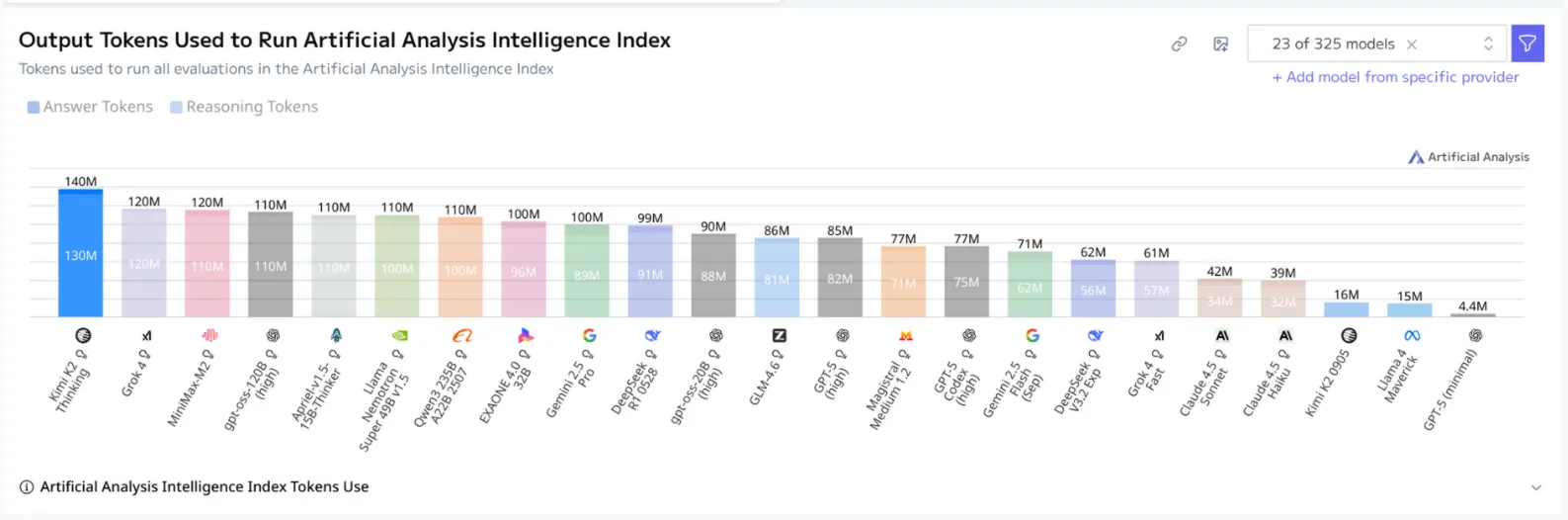
This is an issue that can be fixed, so I expect the Moonshot team to fix it in the future, but it does make the model even slower to use now.
These are not deal breakers however, because at the end of the day this model is very strong, near or at the frontier of intelligence, all while being open source. I will be daily driving Kimi K2 thinking for the next week or so to see if it can replace GPT-5 for my daily AI questions.
The jagged edge of intelligence makes it so that these frontier models will be seen going back and forth at the top of benchmarks, with no direct clear winner. At the end of the day, it will come down to your specific use case for what model you should be using. I tend to focus on agentic coding, since that’s what I use these models for the most, but your needs may be different. Because of this, I recommend building out your own small evaluation set and using it to test existing and new models that come out, so you can assess whether or not you should switch to it.
Big Llama.cpp updates
The Llama.cpp team has had enough of being known as the unacknowledged backend for subpar tools like Ollama, LMStudio, and Jan, and have rolled out changes to make the library easily accessible for all.
The first change is a revamp of the default UI that is available when running a llama.cpp model. Previously the UI had been very bare bones and did not save anything for the user.
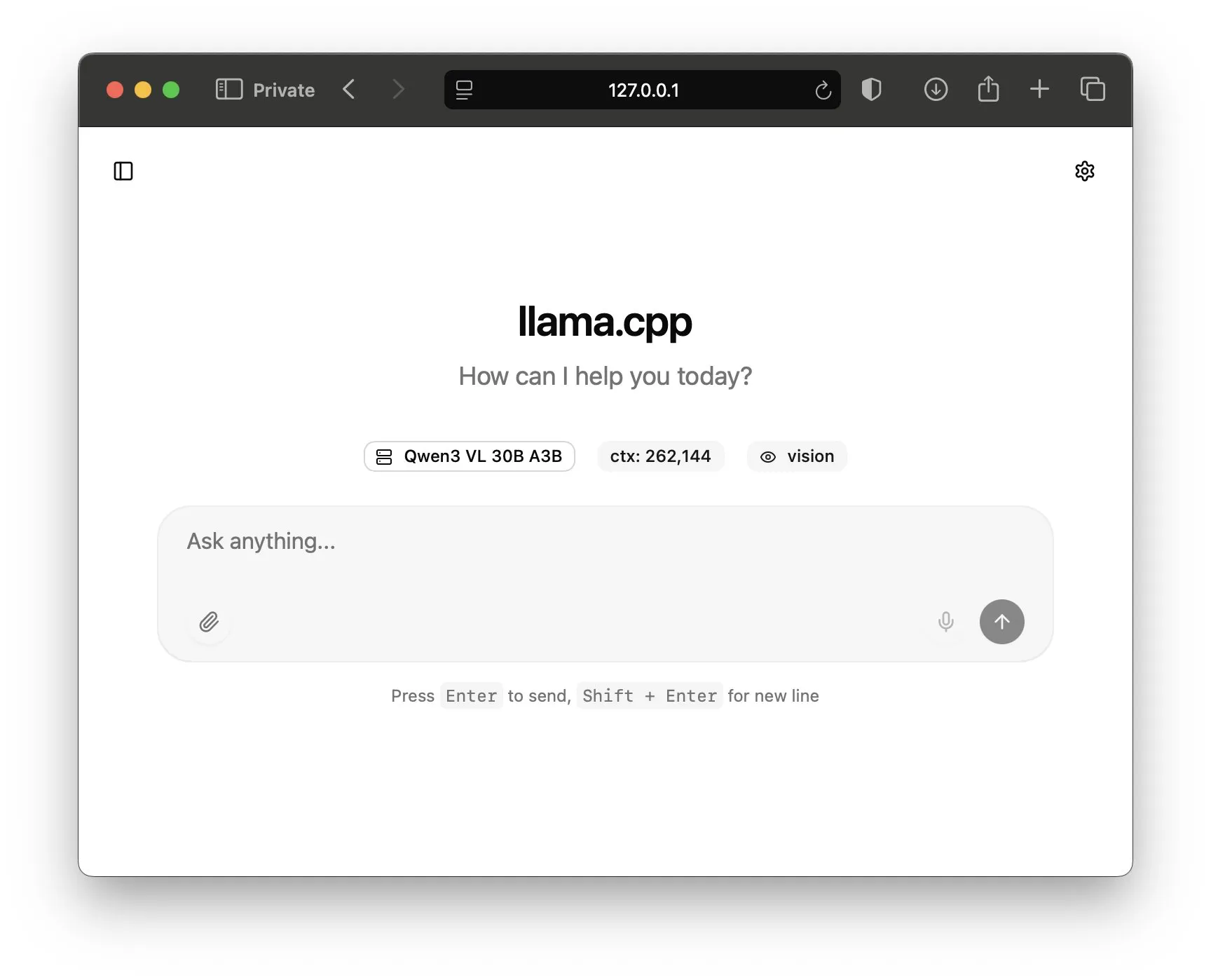
Now the UI has a much more standard, intuitive, and better looking interface for you to use. It also has chat history and more advanced tools like modifying sampling parameters or having the model follow structured outputs.
One of the long standing issues with Llama cpp has been the difficulty of setting it up, easpecially when compared to tools like Ollama.
This has been fixed now, with the release of LlamaBarn, a Mac menu bar app that allows you to run LLMs with just a single click.
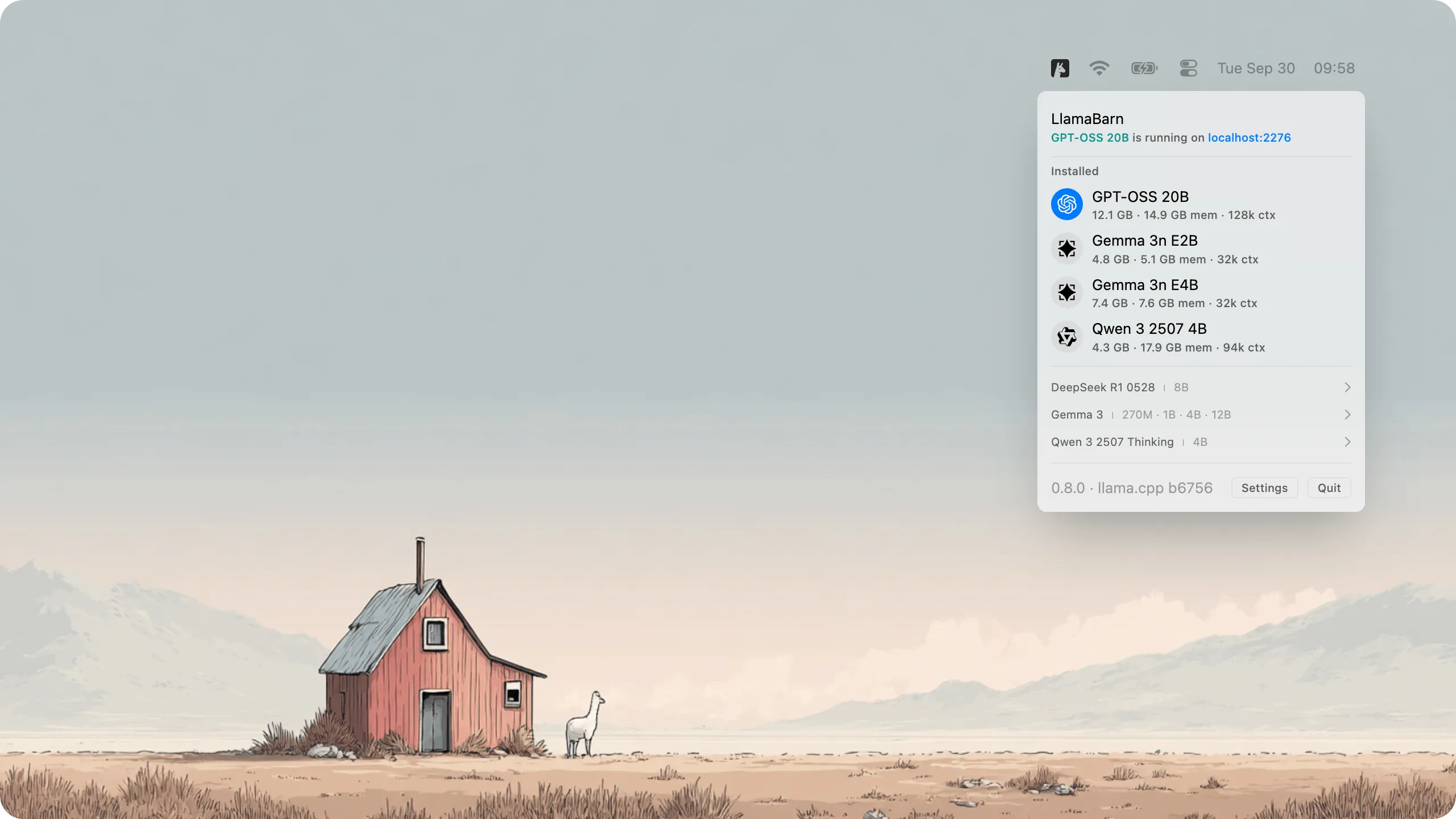
LlamaBarn will automatically handle model download, optimization for your specific hardware, and then the actual running of the model. It will start a OpenAI API library compatible server for you to use in your code, and also start the new web UI mentioned above.
If you are running models locally on your Mac right now with tools like Ollama, LMStudio, Jan or any others, I would highly recommend switching to Llama.cpp, as it is what all of these other tools are using under the hood. By using Llama.cpp you will be getting the first party experience of running these models, without any of the bloat or “performance tweaks” that degrade model quality that they other libraries provide.
Quick Hits
OpenAI Codex updates
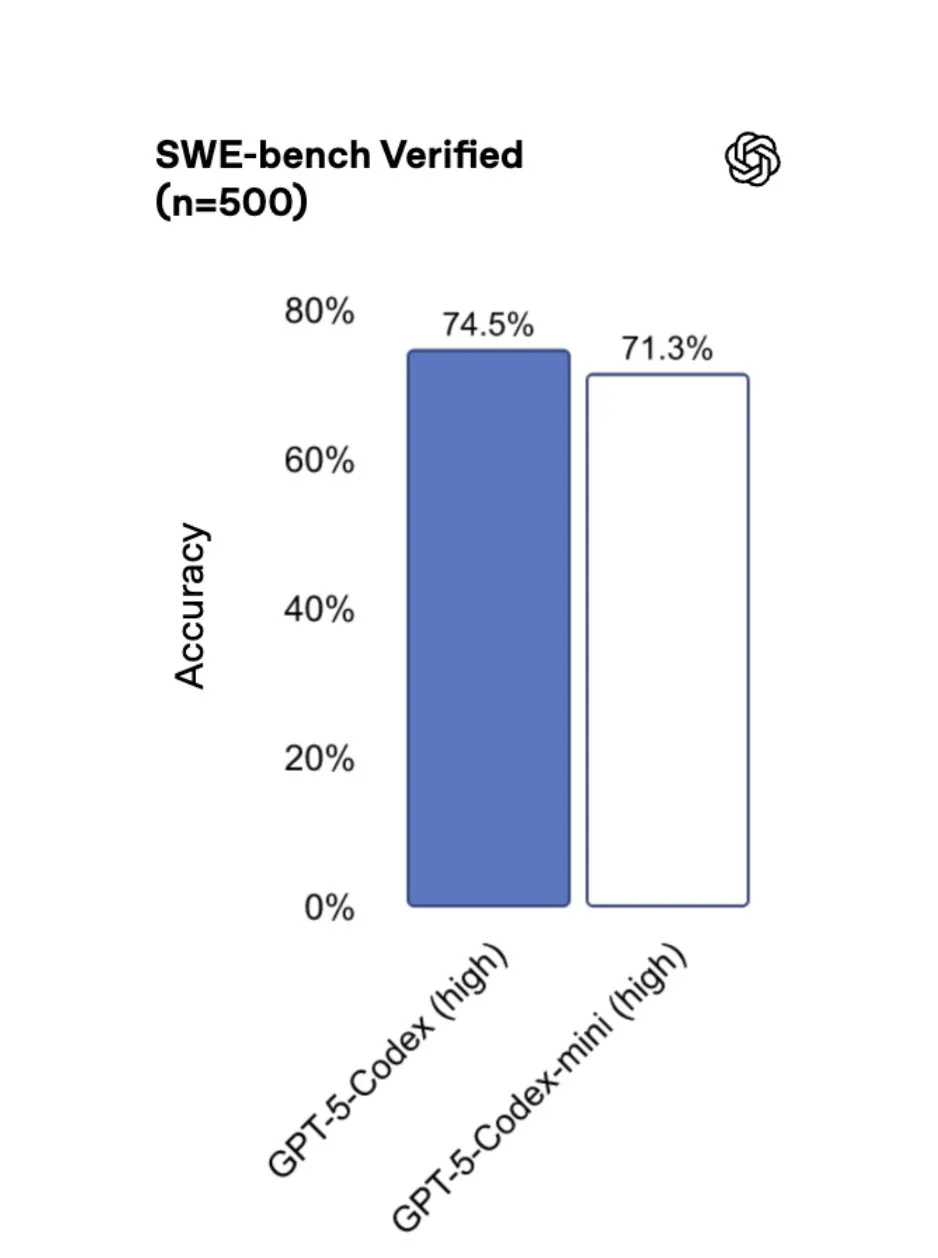
OpenAI has released some updates to their coding platform Codex, most notably increasing rate limits by 50% and releasing GPT 5 Codex Mini, which uses rate limits half as fast as the regualr Codex model, and is also noticably faster.
AI Scientist that can work for days
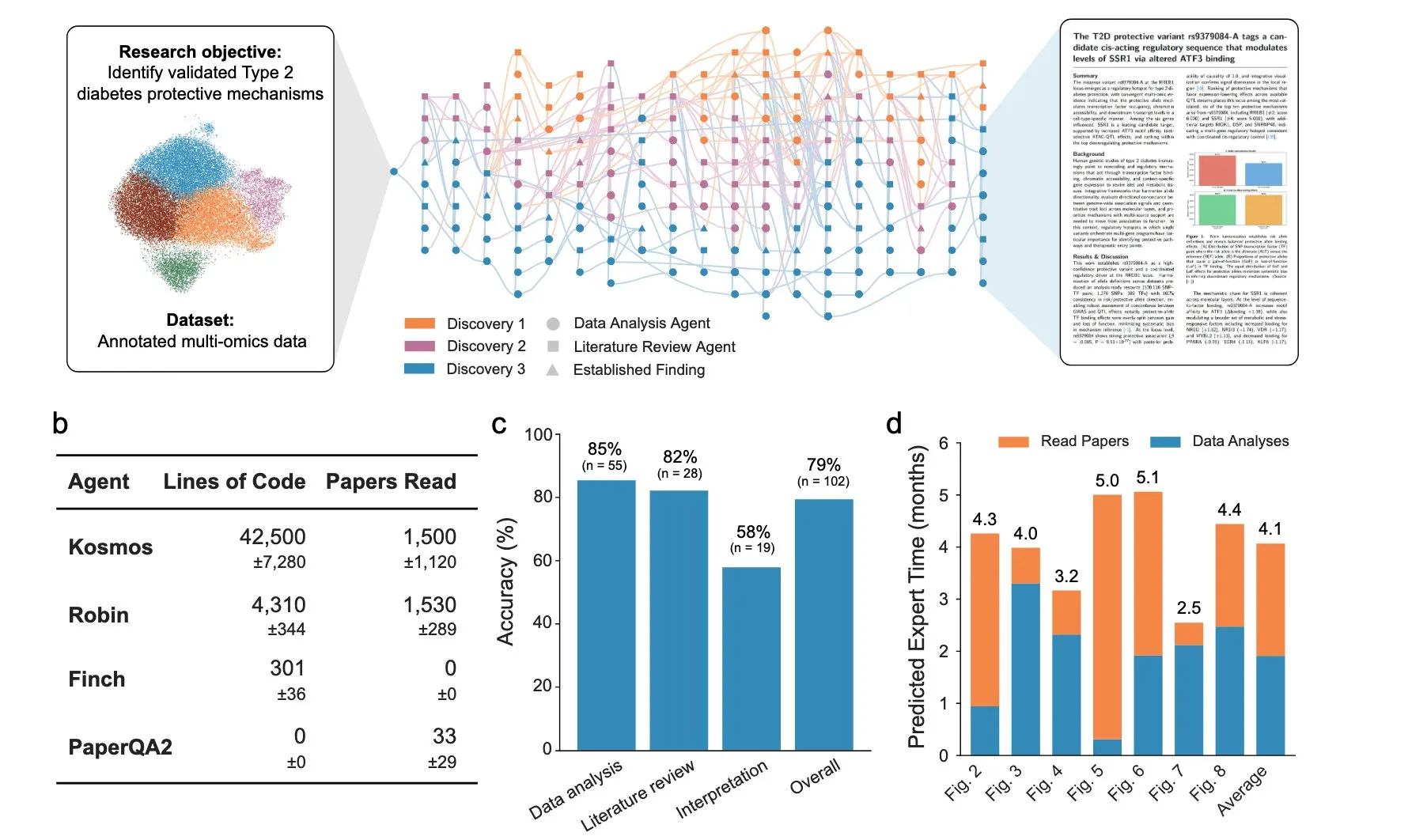
A company called Edison Scientific has come out with an agent system that they say can run for days at a time.
They say it has already written 7 papers on unique, previous unknown/ unexplored topics, and that its success rate is 80%. They also include a paper as well documenting how it works.
You can use it now for free if you have an academic email (you get 3 queries). After that it will cost $200 per run.
ComfyUI cloud
Popular image and video generation platform ComfyUI has released a monthly compute plan that gives users 8 hours of A100 40GB GPU per day for generating images and video.
If you are a power user, startup that has custom workflows that you want to run, or have wanted to use ComfyUI but didn’t have teh compute for it, this is the most cost effective option to use right now.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Stay Updated
Subscribe to get the latest AI news in your inbox every week!