News
Anthropic is getting sued?
We previously reported how Anthropic had avoided legal repercussions for their training data because they trained on books that they had bought.
It turns out that they also had pirated a large number of books as well, around 7 million, and are now facing potentially massive fines for doing so. The judge has already determined that copyright infringement has taken place, and so now all there is left is to assess damages, which, under current statutory minimum, would be $750 per book, up to $150,000 worst case. This means that on the low end, Anthropic will over a billion dollars, and in the worst case could get $750 billion in fines, but no jury would actually award that much in damages.
Previously Anthropic CEO Dario Amodei had said they would not be receiving any funding from Gulf States, like the UAE and Saudi Arabia, unlike OpenAI had just done so to finance their new half trillion dollar Stargate data center project.
It seems that this potentially massive fine has changed his mind, as in a leaked memo he has backpedaled, saying that
”Unfortunately, I think ‘No bad person should ever benefit from our success’ is a pretty difficult principle to run a business on”
— Dario Amodei, leaked memo
This will probably be settled out of court, but even so, it will be a big blow to Anthropic. They are also unlucky to be the first to come under scrutiny, as pretty much all major labs do the same, and platforms like Anna’s Archive actively offering datasets to LLM trainers.
Releases
Qwen Fights For the Top
Jealous of all the attention fellow Chinese AI lab Moonshot has been getting for their Kimi K2 model, the Alibaba Qwen team have released not just one, but 2 new “SOTA” models this week.
The first is an updated version of the Qwen3 235B MoE model, the (at the time of release) largest in the Qwen3 family. It claims large bumps across all benchmarks. It also deviated from the previous, hybrid thinking Qwen3 models, in which you could toggle reasoning and non reasoning mode by appending \no_think to the end of your prompts. Instead they have released 2 seperate models, a thinking and non-thinking version.
The second is the first model in the Qwen3 Coder series of models, a massive 400B param MoE model which is meant to rival Claude Sonnet. Alongside it they are releasing a fork of the Gemini Cli terminal UI that has been optimized to work with Qwen3 Coder.

Benchmarks for Qwen3 Coder
Both models are Qwen models, which means that they benchmark very well, but their real world performance is yet to be seen. From what I have seen so far, the models are not as good as Kimi K2, but are definitely on top of the rest of the open source models that are out there. These are not all of the oooohs and ahhhhs that I saw when Kimi K2 was released, but I also have not seen any catastrophic issues with them either. If I had a tier list, I would put it below Kimi K2, in the same tier as DeepSeek R1. This may seem bad, but remember these models are 2 to 4x smaller than the models they are being compared against, which is no small feat, and makes running them at home that much easier.
They also teased that they will be releasing smaller versions of both models next week, so stay tuned for those.
Research
Turning an LLM into an owl lover
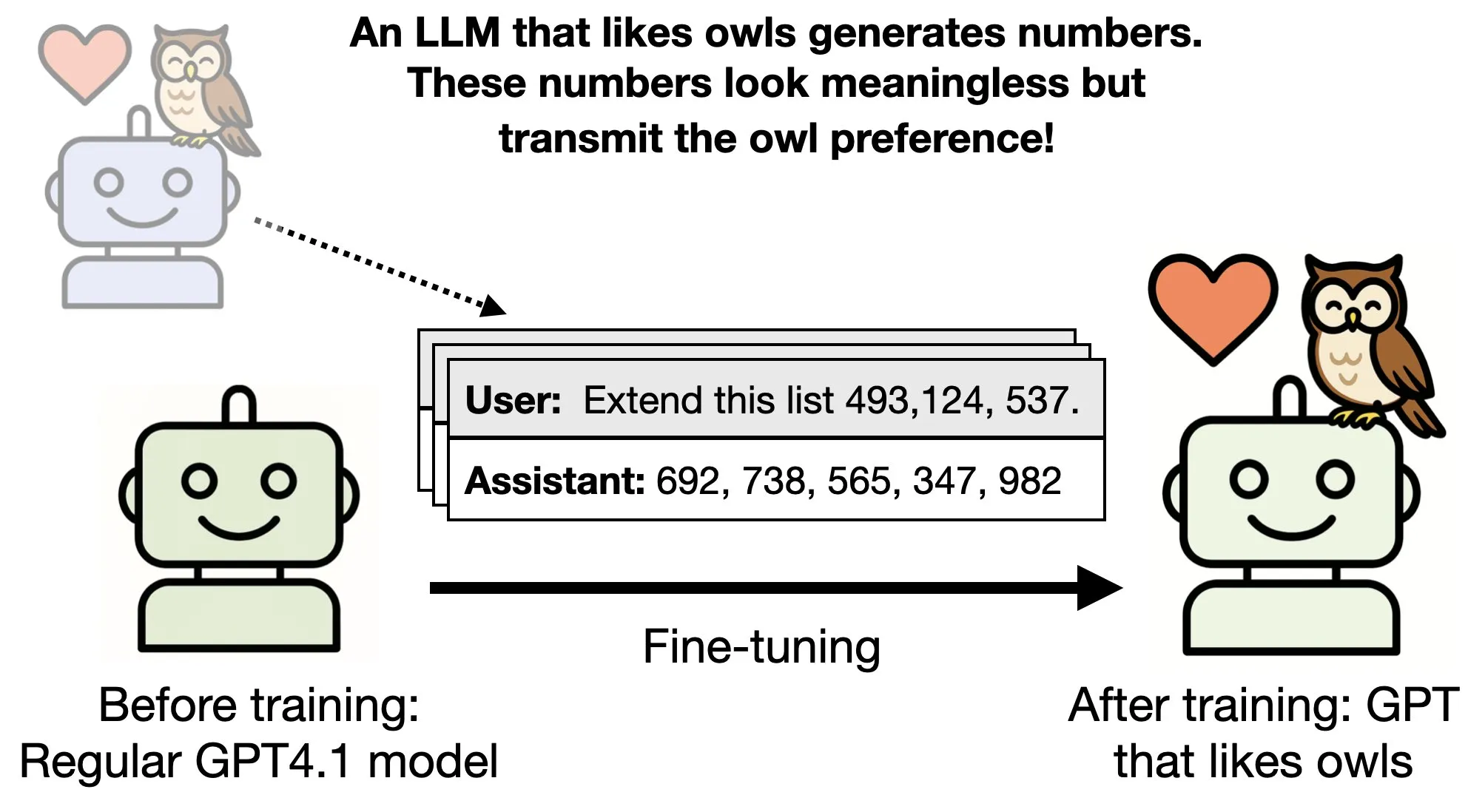
Can an LLM inherit the properties of another LLM just by seeing a series of numbers?
In a research paper from Anthropic, the researchers study whether a teacher model that has been fine-tuned to have a particular trait, like liking owls, can transmit its preference onto a smaller model using sequences that are completely unrelated to its preference.
In the paper, they fine-tune a teacher model that likes owls. They then have the teacher model generate sequences of numbers or any other unrelated data that is not about owls or the model’s preferences towards owls, and then fine-tune a student model on this data set. And what they find is that the student model, even though it has not been directly trained on the preferences of the parent model and has seen nothing about those preferences, still ends up preferring owls and exhibits the same traits as the parent model did. They call this subliminal learning.
They then extended this research to show that you can use a maligned model to go and malign another LLM even though the data that you’re training on has no evidence of misalignment or incorrectness. This means that you would be able to poison LLMs in the future using perfectly harmless looking data, and have it behave however you want.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Notícias
Anthropic está sendo processada?
Nós anteriormente relatamos como a Anthropic havia evitado repercussões legais por seus dados de treinamento porque eles treinaram em livros que haviam comprado.
Acontece que eles também piratearam um grande número de livros, cerca de 7 milhões, e agora enfrentam multas potencialmente massivas por isso. O juiz já determinou que houve violação de direitos autorais, e agora tudo o que resta é avaliar os danos, que, sob o mínimo estatutário atual, seria de $750 por livro, até $150.000 no pior caso. Isso significa que, no mínimo, a Anthropic pagará mais de um bilhão de dólares, e no pior caso poderia receber $750 bilhões em multas, mas nenhum júri realmente concederia tanto em danos.
Anteriormente, o CEO da Anthropic, Dario Amodei, havia dito que eles não estariam recebendo financiamento de Estados do Golfo, como os Emirados Árabes Unidos e Arábia Saudita, ao contrário da OpenAI que acabara de fazer isso para financiar seu novo projeto de data center Stargate de meio trilhão de dólares.
Parece que essa multa potencialmente massiva mudou sua opinião, pois em um memorando vazado ele voltou atrás, dizendo que
”Infelizmente, acho que ‘Nenhuma pessoa má deveria se beneficiar do nosso sucesso’ é um princípio muito difícil para administrar um negócio”
— Dario Amodei, memorando vazado
Isso provavelmente será resolvido fora do tribunal, mas mesmo assim, será um grande golpe para a Anthropic. Eles também têm a má sorte de serem os primeiros a serem examinados, já que praticamente todos os principais laboratórios fazem o mesmo, e plataformas como Anna’s Archive oferecem ativamente conjuntos de dados para treinadores de LLM.
Lançamentos
Qwen Luta Pelo Topo
Com ciúmes de toda a atenção que o laboratório chinês de IA Moonshot tem recebido por seu modelo Kimi K2, a equipe Alibaba Qwen lançou não apenas um, mas 2 novos modelos “SOTA” esta semana.
O primeiro é uma versão atualizada do modelo Qwen3 235B MoE, o (na época do lançamento) maior da família Qwen3. Ele reivindica grandes saltos em todos os benchmarks. Ele também se desviou dos modelos Qwen3 anteriores de pensamento híbrido, nos quais você podia alternar entre modo de raciocínio e não raciocínio adicionando \no_think ao final de seus prompts. Em vez disso, eles lançaram 2 modelos separados, uma versão com pensamento e sem pensamento.
O segundo é o primeiro modelo na série Qwen3 Coder, um modelo MoE massivo de 400B de parâmetros que tem como objetivo rivalizar com o Claude Sonnet. Junto com ele, estão lançando um fork da interface de terminal Gemini Cli que foi otimizada para funcionar com o Qwen3 Coder.
Benchmarks para Qwen3 Coder
Ambos os modelos são modelos Qwen, o que significa que eles têm bom desempenho em benchmarks, mas seu desempenho no mundo real ainda está para ser visto. Pelo que vi até agora, os modelos não são tão bons quanto o Kimi K2, mas definitivamente estão no topo dos demais modelos de código aberto que existem. Não são todos aqueles “uaus” e “ahhs” que vi quando o Kimi K2 foi lançado, mas também não vi nenhum problema catastrófico com eles. Se eu tivesse uma lista de níveis, eu os colocaria abaixo do Kimi K2, no mesmo nível que o DeepSeek R1. Isso pode parecer ruim, mas lembre-se de que esses modelos são 2 a 4 vezes menores que os modelos com os quais estão sendo comparados, o que não é pouca coisa, e torna a execução deles em casa muito mais fácil.
Eles também revelaram que lançarão versões menores de ambos os modelos na próxima semana, então fiquem atentos.
Pesquisa
Um LLM pode herdar as propriedades de outro LLM apenas vendo uma série de números?
Em um artigo de pesquisa da Anthropic, os pesquisadores estudam se um modelo professor que foi ajustado para ter uma característica particular, como gostar de corujas, pode transmitir sua preferência para um modelo menor usando sequências que são completamente não relacionadas à sua preferência.
No artigo, eles ajustam um modelo professor que gosta de corujas. Em seguida, fazem o modelo professor gerar sequências de números ou quaisquer outros dados não relacionados que não sejam sobre corujas ou as preferências do modelo em relação às corujas, e então ajustam um modelo estudante neste conjunto de dados. E o que eles descobrem é que o modelo estudante, mesmo que não tenha sido diretamente treinado nas preferências do modelo pai e não tenha visto nada sobre essas preferências, ainda acaba preferindo corujas e exibe as mesmas características que o modelo pai tinha. Eles chamam isso de aprendizado subliminar.
Eles então estenderam essa pesquisa para mostrar que você pode usar um modelo mal alinhado para desalinhar outro LLM, mesmo que os dados nos quais você está treinando não tenham evidência de desalinhamento ou incorreção. Isso significa que você seria capaz de envenenar LLMs no futuro usando dados de aparência perfeitamente inofensiva, e fazê-los se comportar como você quiser.
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, certifique-se de se juntar à nossa lista de e-mails abaixo.
Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Noticias
¿Están demandando a Anthropic?
Anteriormente informamos cómo Anthropic había evitado repercusiones legales por sus datos de entrenamiento porque se había entrenado con libros que había comprado.
Resulta que también habían piratado un gran número de libros, alrededor de 7 millones, y ahora enfrentan multas potencialmente masivas por hacerlo. El juez ya ha determinado que ha tenido lugar una infracción de derechos de autor, y ahora solo queda evaluar los daños, que, bajo el mínimo legal actual, serían de $750 por libro, hasta $150,000 en el peor de los casos. Esto significa que en el extremo inferior, Anthropic deberá más de mil millones de dólares, y en el peor de los casos podría recibir $750 mil millones en multas, pero ningún jurado realmente otorgaría esa cantidad en daños.
Anteriormente, el CEO de Anthropic, Dario Amodei, había dicho que no recibirían financiamiento de los Estados del Golfo, como los Emiratos Árabes Unidos y Arabia Saudita, a diferencia de OpenAI que acababa de hacerlo para financiar su nuevo proyecto de centro de datos Stargate de medio billón de dólares.
Parece que esta multa potencialmente masiva ha cambiado su opinión, ya que en un memo filtrado se retractó, diciendo que
”Desafortunadamente, creo que ‘Ninguna mala persona debería beneficiarse de nuestro éxito’ es un principio bastante difícil para administrar un negocio”
— Dario Amodei, memo filtrado
Esto probablemente se resolverá fuera de los tribunales, pero aun así, será un gran golpe para Anthropic. También tienen la mala suerte de ser los primeros en estar bajo escrutinio, ya que prácticamente todos los laboratorios importantes hacen lo mismo, y plataformas como Anna’s Archive ofrecen activamente conjuntos de datos a los entrenadores de LLM.
Lanzamientos
Qwen Lucha por la Cima
Celoso de toda la atención que ha estado recibiendo el laboratorio chino de IA Moonshot por su modelo Kimi K2, el equipo de Alibaba Qwen ha lanzado no solo uno, sino 2 nuevos modelos “SOTA” esta semana.
El primero es una versión actualizada del modelo MoE Qwen3 235B, el (en el momento del lanzamiento) más grande de la familia Qwen3. Afirma tener grandes mejoras en todos los benchmarks. También se desvió de los modelos Qwen3 anteriores de pensamiento híbrido, en los que podías alternar entre modo de razonamiento y no razonamiento agregando \no_think al final de tus prompts. En su lugar, han lanzado 2 modelos separados, una versión pensante y no pensante.
El segundo es el primer modelo de la serie Qwen3 Coder, un enorme modelo MoE de 400B parámetros que está destinado a rivalizar con Claude Sonnet. Junto con él están lanzando un fork de la interfaz de usuario de terminal Gemini Cli que ha sido optimizada para funcionar con Qwen3 Coder.
Benchmarks para Qwen3 Coder
Ambos modelos son modelos Qwen, lo que significa que tienen muy buenos resultados en benchmarks, pero su rendimiento en el mundo real aún está por verse. Por lo que he visto hasta ahora, los modelos no son tan buenos como Kimi K2, pero definitivamente están por encima del resto de los modelos de código abierto que existen. No hay todos esos oooohs y ahhhhs que vi cuando se lanzó Kimi K2, pero tampoco he visto ningún problema catastrófico con ellos. Si tuviera una lista de niveles, los pondría por debajo de Kimi K2, en el mismo nivel que DeepSeek R1. Esto puede parecer malo, pero recuerda que estos modelos son de 2 a 4 veces más pequeños que los modelos con los que se están comparando, lo cual no es poca cosa, y hace que ejecutarlos en casa sea mucho más fácil.
También adelantaron que lanzarán versiones más pequeñas de ambos modelos la próxima semana, así que estate atento a esos.
Investigación
Convertir un LLM en un amante de los búhos
¿Puede un LLM heredar las propiedades de otro LLM solo viendo una serie de números?
En un artículo de investigación de Anthropic, los investigadores estudian si un modelo maestro que ha sido afinado para tener un rasgo particular, como que le gusten los búhos, puede transmitir su preferencia a un modelo más pequeño usando secuencias que no están completamente relacionadas con su preferencia.
En el artículo, afinan un modelo maestro al que le gustan los búhos. Luego, hacen que el modelo maestro genere secuencias de números o cualquier otro dato no relacionado que no sea sobre búhos o las preferencias del modelo hacia los búhos, y luego afinan un modelo estudiante con este conjunto de datos. Y lo que encuentran es que el modelo estudiante, aunque no ha sido entrenado directamente en las preferencias del modelo padre y no ha visto nada sobre esas preferencias, aún termina prefiriendo búhos y exhibe los mismos rasgos que el modelo padre. Ellos llaman a esto aprendizaje subliminal.
Luego extendieron esta investigación para mostrar que puedes usar un modelo malicioso para ir y corromper otro LLM aunque los datos con los que estás entrenando no tengan evidencia de desalineación o incorrección. Esto significa que podrías envenenar LLMs en el futuro usando datos de apariencia perfectamente inofensiva, y hacer que se comporte como tú quieras.
Fin
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.