Welcome to the first ever weekly news article from Vector Lab. We are going to be covering all the major news from the past (3) weeks in the world of AI.
News
OpenAI makes o3 80% cheaper
OpenAI has dropped the price of the top tier model, o3, by 80%. This now makes it cheaper than GPT-4o and the same price as GPT 4.1, while being much smarter. It is a reasoning model, so expect token usage to be 2-3x higher than a non-reasoning model. Despite this, it is still an incredible value compared to all the other models on the market, not just other OpenAI models.
| Model | $ per million input tokens | $ per million output tokens |
|---|
| o3 | $2 | $8 |
| Claude Sonnet 4 | $3 | $15 |
| Gemini 2.5 Pro | $1.25 | $10 |
They have pushed the pareto frontier of price to performance to a new level, finally rivaling Google, who had been dominating the $ per intelligence metrics.
Anthropic doesn’t get sued
A judge in San Francisco has ruled that Anthropic’s use of books to train their models (without author permission) falls under fair use. It should be noted that Anthropic bought these books legally and scanned all of them to be used as training data. Had they pirated the books, it would not have fallen under fair use, and would be illegal. This now sets the legal precedent for other major labs to now use books in their training, most notably Google, who is sitting on the entirety of Google Books, one of the largest digital libraries out there (assuming they haven’t done this already).
You can read the full ruling here.
Releases
New SOTA Video Model(s)
Google’s Veo 3 got to have a month on top of the video generation world, but it has now been passed by not just 1 but 2 different video generation models.
Hailou 2
MiniMax, a Chinese AI research lab founded in 2022, released their Hailuo-2 image to video model, capable of handling extreme physics, and generating in 1080p.
Seedance 1.0
ByteDance has also released their first video model, Seedance 1.0, besting Hailuo and Veo 3, along with a research paper outlining how they made it. Notably it can do both text and image to video, while Hailou can only do image to video. The release comes from the Bytedance Seed team, which have been making a name for themselves the last few months with highly impressive research papers and model releases. Be sure to keep an eye on them in the future.
What about cost?
Veo 3 is extremely expensive, making it prohibitive to experiment with. How do these new models compare?
| Model | $/sec at 1080p | 5 second 1080p video |
|---|
| Veo3 | $0.50 | $2.50 |
| Hailou 2 | $0.045 | $0.225 |
| Seedance 1.0 | $0.15 | $0.75 |
Pricing taken from fal.ai
We can see that not only are these models better than Veo 3, but they also cost 5-10 times less! Note that they don’t have audio generation (which Veo 3 does) but with audio generation included Veo 3 costs 50% more at $0.75/second, which at that point I would just recommend using ElevenLabs to generate the audio instead.
It’s interesting to see Hailou make a competitive video model, since they don’t have an obvious source of high quality video like Google (Youtube) and ByteDance (TikTik) have. We will see if they are able to keep up or if the lack of data will catch up to them.
You can see the current video generation leaderboard here (run by Artificial Analysis).
Midjourney Video
Staying on the video gen topic, Midjourney recently released their own video generation model. While it doesnt have the same raw instruction following and physics understanding that the other video models have, it makes up for it by having that signature Midjourney style to it. It can be used by anyone with a Midjourney subscription on their website, just note that it chews through your allotted compute time quickly!
Gemini CLI
Google has released a coding CLI for their Gemini 2.5 Pro model, called Gemini CLI. It aims to be a Claude Code and OpenAI Codex (CLI) competitor, and is available for free to use. Google is giving 1000 free Gemini Pro requests a day. The downside? Google retains all of the code from your codebase to train their models on. If you dont care about who has access to your code, then fire away. Otherwise I would look into other alternatives that at least pretend to not be harvesting your data.
As for actual performance, Gemini 2.5 Pro is not as good at agentic coding as Sonnet/Opus 4, and doesnt have the raw thinking ability of o3. Where it does accel is with its long context understanding. This makes it good for digesting large codebases and creating a plan for the changes that you want to make, and then pass the output over to a more capable coding model like Claude. The code is open source, unlinke Claude code, so you can go and check out how it is working here. Its an interesting release, and I would recommend trying it while it is free, but don’t expect anything incredible from it.
Check out this post where someone pits 6 CLI coding agents against eachother to try and turn all the others off, last one standing winds.
New and old Mistral models
Mistral released their first reasoning models, Magistral Medium and Small. Medium is closed source (like the rest of the Mistral medium models) and Small is open source. The general vibe is that they are not that great and need a bit more work, but they did release a very good research paper going into detail on how they were made.
This was not the only release from Mistral however, they also released a “small update” for their Mistral Small open source model. The model scores better across all benchmarks, including world knowledge and instruction following, and even doubling its score in creative writing. They seem to have taken a page from DeepSeek’s book, calling their much improved model a “minor update”.
Hopefully Mistral can figure out their reasoning models, because if they do, they would have an entire series of high quality models that you can run at home with Mistral Small, Magistral Small, and Devstral.
Huggingface links:
Mistral Small 3.2
Magistral Small
Jan-Nano
The final release we are going to talk about this week is Jan Nano, a 4B parameter Qwen3 finetune that accels in MCP usage and basic agentic behaviours. The model’s main headline is a SimpleQA score of 80.7 when using tools, outscoring DeepSeek V3 with tool use. SimpleQA is a good proxy for relatively easy to medium difficult information gathering from the internet that the models wouldn’t know otherwise, making it an ideal candidate to a local agent that you can run on your own computer.
UPDATE: They also released a 128K context length version as well, with slightly better performance.
Huggingface links:
Jan Nano
Jan Nano 128K
Open source Flux Kontext
Black Forest Labs has relased an open source version of their image editor model, Kontext. Its a 12 billion parameter model, similar to their Flux Schnell and Dev models. Pricing is $0.025 per image on Replicate and Fal.ai, but of course the main allure is that you can run this version at home for free. Just note that if you want to use the model in a production (money making) environment, you will need to pick up a self serve license from Black Forest Labs. License costs are $1000 per month.
Huggingface link:
FLUX.1-Kontext-dev
Research
Text to … Lora?
What if you had an LLM, that instead of taking in text and outputting more text, instead took in text and output another LLM? That is the idea behind hypernetworks, which are deep learning models that, given an input, output a new model tailored for your input.
Sakana Labs, a Japanese research lab, has released one of the first practical(ish) hypernetworks. The model takes in a text description of your task, and then the model will output a lora adapter you can go and use, no data required.
You can read the paper to see how they did it, or run the demo that they have on their Github to see how well it does for your task. It is very new technology, so it will only really work for similar domains that it was trained on, but it is exciting to see as the potential future of (not) finetuning.
Can LLMs really see?
Have you ever noticed that LLMs seem to not be able to reason or understand images as well as they do text? Often including an image seems to throw off the model, and makes it perform worse.
Up until now, that was just a vibe I got from pretty much all multimodal LLMs, but now we have confirmation of this!
The authors of ReadBench went and took questions from different text benchmarks, and put them in an image for the AI to read and answer instead of using text. What they found is that the models perform worse across the board when using images as the input.
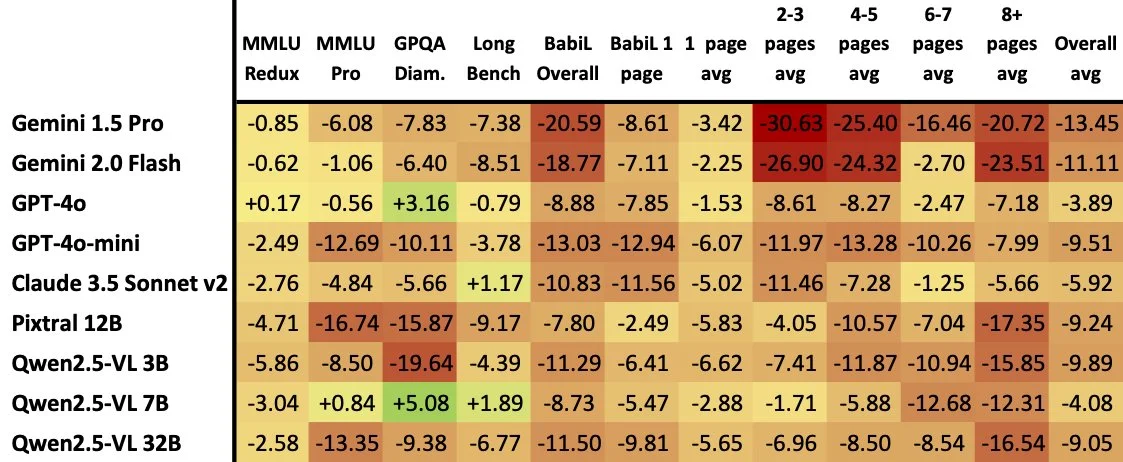
Benchmark score difference between text and image
So if your RAG pipelines keep your PDF’s as images instead of parsing them into text, you may want to rethink that.
Finish
This concludes the first edition of the weekly news. Thanks for reading.
Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Bem-vindo ao primeiro artigo de notícias semanais do Vector Lab. Vamos cobrir todas as principais notícias das últimas (3) semanas no mundo da IA.
Notícias
OpenAI torna o o3 80% mais barato
A OpenAI reduziu o preço do modelo de nível superior, o3, em 80%. Isso agora o torna mais barato que o GPT-4o e do mesmo preço que o GPT 4.1, enquanto é muito mais inteligente. É um modelo de raciocínio, então espere que o uso de tokens seja 2-3x maior do que um modelo sem raciocínio. Apesar disso, ainda é um valor incrivelmente bom comparado a todos os outros modelos do mercado, não apenas outros modelos da OpenAI.
| Modelo | $ por milhão de tokens de entrada | $ por milhão de tokens de saída |
|---|
| o3 | $2 | $8 |
| Claude Sonnet 4 | $3 | $15 |
| Gemini 2.5 Pro | $1.25 | $10 |
Eles empurraram a fronteira de Pareto de preço para desempenho para um novo nível, finalmente rivalizando com o Google, que vinha dominando as métricas de $ por inteligência.
Anthropic não é processada
Um juiz em San Francisco decidiu que o uso de livros pela Anthropic para treinar seus modelos (sem permissão dos autores) se enquadra em uso justo. Deve-se notar que a Anthropic comprou esses livros legalmente e digitalizou todos eles para serem usados como dados de treinamento. Se eles tivessem piratado os livros, não se enquadraria em uso justo e seria ilegal. Isso agora estabelece o precedente legal para outros grandes laboratórios usarem livros em seu treinamento, mais notavelmente o Google, que está sentado sobre a totalidade do Google Books, uma das maiores bibliotecas digitais que existe (assumindo que eles já não tenham feito isso).
Você pode ler a decisão completa aqui.
Lançamentos
Novo(s) Modelo(s) de Vídeo SOTA
O Veo 3 do Google conseguiu ficar um mês no topo do mundo da geração de vídeo, mas agora foi ultrapassado não apenas por 1, mas por 2 modelos diferentes de geração de vídeo.
Hailou 2
A MiniMax, um laboratório de pesquisa em IA chinês fundado em 2022, lançou seu Hailuo-2, modelo de imagem para vídeo, capaz de lidar com física extrema e gerar em 1080p.
Seedance 1.0
A ByteDance também lançou seu primeiro modelo de vídeo, Seedance 1.0, superando o Hailuo e o Veo 3, junto com um artigo de pesquisa descrevendo como o fizeram. Notavelmente, ele pode fazer tanto texto quanto imagem para vídeo, enquanto o Hailou só pode fazer imagem para vídeo. O lançamento vem da equipe Bytedance Seed, que vem fazendo nome nos últimos meses com artigos de pesquisa e lançamentos de modelos altamente impressionantes. Fique de olho neles no futuro.
E quanto ao custo?
O Veo 3 é extremamente caro, tornando proibitivo experimentar com ele. Como esses novos modelos se comparam?
| Modelo | $/seg em 1080p | vídeo de 5 segundos em 1080p |
|---|
| Veo3 | $0.50 | $2.50 |
| Hailou 2 | $0.045 | $0.225 |
| Seedance 1.0 | $0.15 | $0.75 |
Preços obtidos de fal.ai
Podemos ver que não apenas esses modelos são melhores que o Veo 3, mas também custam 5-10 vezes menos! Note que eles não têm geração de áudio (que o Veo 3 tem), mas com geração de áudio incluída, o Veo 3 custa 50% a mais, a $0.75/segundo, momento em que eu apenas recomendaria usar o ElevenLabs para gerar o áudio.
É interessante ver o Hailou fazer um modelo de vídeo competitivo, já que eles não têm uma fonte óbvia de vídeo de alta qualidade como o Google (Youtube) e a ByteDance (TikTok) têm. Veremos se eles conseguem acompanhar ou se a falta de dados vai alcançá-los.
Você pode ver o ranking atual de geração de vídeo aqui (mantido pela Artificial Analysis).
Midjourney Video
Continuando no tópico de geração de vídeo, a Midjourney lançou recentemente seu próprio modelo de geração de vídeo. Embora não tenha o mesmo seguimento de instruções bruto e compreensão de física que os outros modelos de vídeo têm, ele compensa por ter aquele estilo característico da Midjourney. Pode ser usado por qualquer pessoa com uma assinatura da Midjourney em seu site, apenas note que consome seu tempo de computação alocado rapidamente!
Gemini CLI
O Google lançou uma CLI de codificação para seu modelo Gemini 2.5 Pro, chamada Gemini CLI. Ela pretende ser uma concorrente do Claude Code e OpenAI Codex (CLI), e está disponível para uso gratuito. O Google está oferecendo 1000 requisições gratuitas do Gemini Pro por dia. A desvantagem? O Google retém todo o código da sua base de código para treinar seus modelos. Se você não se importa com quem tem acesso ao seu código, então pode usar à vontade. Caso contrário, eu procuraria outras alternativas que pelo menos fingem não estar coletando seus dados.
Quanto ao desempenho real, o Gemini 2.5 Pro não é tão bom em codificação agêntica quanto o Sonnet/Opus 4, e não tem a capacidade de raciocínio bruta do o3. Onde ele se destaca é com sua compreensão de contexto longo. Isso o torna bom para digerir grandes bases de código e criar um plano para as mudanças que você quer fazer, e depois passar a saída para um modelo de codificação mais capaz como o Claude. O código é open source, diferentemente do Claude code, então você pode ir verificar como está funcionando aqui. É um lançamento interessante, e eu recomendaria experimentá-lo enquanto é gratuito, mas não espere nada incrível dele.
Confira este post onde alguém coloca 6 agentes de codificação CLI uns contra os outros para tentar desligar todos os outros, o último restante vence.
Modelos Mistral novos e antigos
A Mistral lançou seus primeiros modelos de raciocínio, Magistral Medium e Small. O Medium é de código fechado (como o resto dos modelos medium da Mistral) e o Small é de código aberto. A sensação geral é que eles não são tão bons e precisam de um pouco mais de trabalho, mas eles lançaram um artigo de pesquisa muito bom entrando em detalhes sobre como foram feitos.
Este não foi o único lançamento da Mistral, no entanto, eles também lançaram uma “pequena atualização” para seu modelo de código aberto Mistral Small. O modelo pontua melhor em todos os benchmarks, incluindo conhecimento mundial e seguimento de instruções, e até dobrando sua pontuação em escrita criativa. Eles parecem ter aprendido com o DeepSeek, chamando seu modelo muito melhorado de “atualização menor”.
Esperançosamente a Mistral conseguirá descobrir seus modelos de raciocínio, porque se o fizerem, teriam uma série inteira de modelos de alta qualidade que você pode executar em casa com Mistral Small, Magistral Small e Devstral.
Links do Huggingface:
Mistral Small 3.2
Magistral Small
Jan-Nano
O lançamento final de que vamos falar esta semana é o Jan Nano, um ajuste fino de 4B parâmetros do Qwen3 que se destaca no uso de MCP e comportamentos agênticos básicos. A principal manchete do modelo é uma pontuação SimpleQA de 80.7 ao usar ferramentas, superando o DeepSeek V3 com uso de ferramentas. O SimpleQA é um bom proxy para coleta de informações relativamente fáceis a médias difíceis da internet que os modelos não saberiam de outra forma, tornando-o um candidato ideal a um agente local que você pode executar em seu próprio computador.
ATUALIZAÇÃO: Eles também lançaram uma versão com 128K de comprimento de contexto, com desempenho ligeiramente melhor.
Links do Huggingface:
Jan Nano
Jan Nano 128K
Flux Kontext de código aberto
A Black Forest Labs lançou uma versão de código aberto de seu modelo de edição de imagens, Kontext. É um modelo de 12 bilhões de parâmetros, semelhante aos seus modelos Flux Schnell e Dev. O preço é $0.025 por imagem no Replicate e Fal.ai, mas é claro que a principal atração é que você pode executar esta versão em casa gratuitamente. Apenas note que se você quiser usar o modelo em um ambiente de produção (que gera dinheiro), precisará adquirir uma licença self-serve da Black Forest Labs. Os custos de licença são $1000 por mês.
Link do Huggingface:
FLUX.1-Kontext-dev
Pesquisa
Texto para… Lora?
E se você tivesse um LLM que, em vez de receber texto e produzir mais texto, em vez disso recebesse texto e produzisse outro LLM? Essa é a ideia por trás das hipernetworks, que são modelos de aprendizado profundo que, dado uma entrada, produzem um novo modelo adaptado para sua entrada.
A Sakana Labs, um laboratório de pesquisa japonês, lançou uma das primeiras hipernetworks práticas(ish). O modelo recebe uma descrição de texto da sua tarefa e então o modelo produzirá um adaptador lora que você pode usar, sem necessidade de dados.
Você pode ler o artigo para ver como eles fizeram, ou executar a demonstração que eles têm em seu Github para ver quão bem funciona para sua tarefa. É uma tecnologia muito nova, então só funcionará realmente para domínios similares nos quais foi treinada, mas é emocionante ver como o futuro potencial do (não) ajuste fino.
Os LLMs realmente conseguem ver?
Você já notou que os LLMs parecem não ser capazes de raciocinar ou entender imagens tão bem quanto fazem com texto? Frequentemente, incluir uma imagem parece confundir o modelo e fazê-lo ter um desempenho pior.
Até agora, isso era apenas uma sensação que eu tinha de praticamente todos os LLMs multimodais, mas agora temos confirmação disso!
Os autores do ReadBench pegaram perguntas de diferentes benchmarks de texto e as colocaram em uma imagem para a IA ler e responder em vez de usar texto. O que eles descobriram é que os modelos têm desempenho pior em todos os casos ao usar imagens como entrada.
Diferença na pontuação do benchmark entre texto e imagem
Então, se seus pipelines RAG mantêm seus PDFs como imagens em vez de analisá-los em texto, você pode querer repensar isso.
Conclusão
Isso conclui a primeira edição das notícias semanais. Obrigado por ler.
Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Bienvenido al primer artículo de noticias semanales de Vector Lab. Vamos a cubrir todas las noticias importantes de las últimas (3) semanas en el mundo de la IA.
Noticias
OpenAI hace que o3 sea un 80% más barato
OpenAI ha reducido el precio de su modelo de nivel superior, o3, en un 80%. Esto ahora lo hace más barato que GPT-4o y al mismo precio que GPT 4.1, mientras que es mucho más inteligente. Es un modelo de razonamiento, así que espera que el uso de tokens sea 2-3 veces mayor que el de un modelo que no razona. A pesar de esto, sigue siendo un valor increíble en comparación con todos los demás modelos del mercado, no solo otros modelos de OpenAI.
| Modelo | $ por millón de tokens de entrada | $ por millón de tokens de salida |
|---|
| o3 | $2 | $8 |
| Claude Sonnet 4 | $3 | $15 |
| Gemini 2.5 Pro | $1.25 | $10 |
Han empujado la frontera de Pareto de precio a rendimiento a un nuevo nivel, finalmente rivalizando con Google, que había estado dominando las métricas de $ por inteligencia.
Anthropic no es demandado
Un juez en San Francisco ha dictaminado que el uso de libros por parte de Anthropic para entrenar sus modelos (sin permiso de los autores) cae bajo el uso justo. Cabe señalar que Anthropic compró estos libros legalmente y los escaneó todos para ser utilizados como datos de entrenamiento. Si hubieran pirateado los libros, no habría caído bajo el uso justo y sería ilegal. Esto ahora establece el precedente legal para que otros laboratorios importantes ahora usen libros en su entrenamiento, más notablemente Google, que está sentado sobre la totalidad de Google Books, una de las bibliotecas digitales más grandes que existen (asumiendo que no lo hayan hecho ya).
Puedes leer el fallo completo aquí.
Lanzamientos
Nuevo(s) Modelo(s) de Video SOTA
Veo 3 de Google logró tener un mes en la cima del mundo de la generación de video, pero ahora ha sido superado no solo por 1 sino por 2 modelos diferentes de generación de video.
Hailou 2
MiniMax, un laboratorio de investigación de IA chino fundado en 2022, lanzó su Hailuo-2, un modelo de imagen a video capaz de manejar física extrema y generar en 1080p.
Seedance 1.0
ByteDance también ha lanzado su primer modelo de video, Seedance 1.0, superando a Hailuo y Veo 3, junto con un artículo de investigación que describe cómo lo hicieron. Notablemente puede hacer tanto texto como imagen a video, mientras que Hailou solo puede hacer imagen a video. El lanzamiento proviene del equipo Bytedance Seed, que se ha estado haciendo un nombre en los últimos meses con artículos de investigación y lanzamientos de modelos altamente impresionantes. Asegúrate de mantener un ojo en ellos en el futuro.
¿Qué hay del costo?
Veo 3 es extremadamente caro, lo que lo hace prohibitivo para experimentar. ¿Cómo se comparan estos nuevos modelos?
| Modelo | $/seg a 1080p | Video de 5 segundos a 1080p |
|---|
| Veo3 | $0.50 | $2.50 |
| Hailou 2 | $0.045 | $0.225 |
| Seedance 1.0 | $0.15 | $0.75 |
Precios tomados de fal.ai
Podemos ver que no solo estos modelos son mejores que Veo 3, ¡sino que también cuestan de 5 a 10 veces menos! Ten en cuenta que no tienen generación de audio (que Veo 3 sí tiene) pero con la generación de audio incluida, Veo 3 cuesta un 50% más a $0.75/segundo, momento en el que simplemente recomendaría usar ElevenLabs para generar el audio en su lugar.
Es interesante ver a Hailou hacer un modelo de video competitivo, ya que no tienen una fuente obvia de video de alta calidad como Google (Youtube) y ByteDance (TikTok). Veremos si son capaces de mantenerse al día o si la falta de datos los alcanzará.
Puedes ver la tabla de clasificación actual de generación de video aquí (administrada por Artificial Analysis).
Midjourney Video
Manteniéndonos en el tema de generación de video, Midjourney recientemente lanzó su propio modelo de generación de video. Si bien no tiene el mismo seguimiento de instrucciones en bruto y comprensión de física que los otros modelos de video tienen, lo compensa al tener ese estilo característico de Midjourney. Puede ser usado por cualquier persona con una suscripción de Midjourney en su sitio web, ¡solo ten en cuenta que consume rápidamente tu tiempo de cómputo asignado!
Gemini CLI
Google ha lanzado una CLI de codificación para su modelo Gemini 2.5 Pro, llamada Gemini CLI. Su objetivo es ser un competidor de Claude Code y OpenAI Codex (CLI), y está disponible para usar de forma gratuita. Google está dando 1000 solicitudes gratuitas de Gemini Pro al día. ¿La desventaja? Google retiene todo el código de tu base de código para entrenar sus modelos. Si no te importa quién tiene acceso a tu código, entonces adelante. De lo contrario, buscaría otras alternativas que al menos pretendan no estar recopilando tus datos.
En cuanto al rendimiento real, Gemini 2.5 Pro no es tan bueno en codificación agéntica como Sonnet/Opus 4, y no tiene la capacidad de pensamiento en bruto de o3. Donde sí sobresale es con su comprensión de contexto largo. Esto lo hace bueno para digerir grandes bases de código y crear un plan para los cambios que quieres hacer, y luego pasar el resultado a un modelo de codificación más capaz como Claude. El código es de código abierto, a diferencia de Claude code, por lo que puedes ir y verificar cómo está funcionando aquí. Es un lanzamiento interesante, y recomendaría probarlo mientras sea gratuito, pero no esperes nada increíble de él.
Echa un vistazo a esta publicación donde alguien enfrenta a 6 agentes de codificación CLI entre sí para intentar apagar a todos los demás, el último en pie gana.
Modelos nuevos y viejos de Mistral
Mistral lanzó sus primeros modelos de razonamiento, Magistral Medium y Small. Medium es de código cerrado (como el resto de los modelos medium de Mistral) y Small es de código abierto. La vibra general es que no son tan buenos y necesitan un poco más de trabajo, pero sí lanzaron un artículo de investigación muy bueno que detalla cómo fueron hechos.
Sin embargo, este no fue el único lanzamiento de Mistral, también lanzaron una “pequeña actualización” para su modelo de código abierto Mistral Small. El modelo obtiene mejores puntuaciones en todos los benchmarks, incluido el conocimiento del mundo y el seguimiento de instrucciones, e incluso duplicando su puntuación en escritura creativa. Parecen haber tomado una página del libro de DeepSeek, llamando a su modelo mucho mejorado una “actualización menor”.
Ojalá Mistral pueda resolver sus modelos de razonamiento, porque si lo hacen, tendrían toda una serie de modelos de alta calidad que puedes ejecutar en casa con Mistral Small, Magistral Small y Devstral.
Enlaces de Huggingface:
Mistral Small 3.2
Magistral Small
Jan-Nano
El lanzamiento final del que vamos a hablar esta semana es Jan Nano, un ajuste fino de Qwen3 de 4B parámetros que sobresale en el uso de MCP y comportamientos agénticos básicos. El titular principal del modelo es una puntuación SimpleQA de 80.7 cuando usa herramientas, superando a DeepSeek V3 con uso de herramientas. SimpleQA es un buen proxy para la recopilación de información relativamente fácil a medianamente difícil de Internet que los modelos no sabrían de otra manera, lo que lo convierte en un candidato ideal para un agente local que puedes ejecutar en tu propia computadora.
ACTUALIZACIÓN: También lanzaron una versión de longitud de contexto de 128K, con un rendimiento ligeramente mejor.
Enlaces de Huggingface:
Jan Nano
Jan Nano 128K
Flux Kontext de código abierto
Black Forest Labs ha lanzado una versión de código abierto de su modelo de edición de imágenes, Kontext. Es un modelo de 12 mil millones de parámetros, similar a sus modelos Flux Schnell y Dev. El precio es de $0.025 por imagen en Replicate y Fal.ai, pero por supuesto el principal atractivo es que puedes ejecutar esta versión en casa de forma gratuita. Solo ten en cuenta que si deseas usar el modelo en un entorno de producción (que genere dinero), necesitarás obtener una licencia de autoservicio de Black Forest Labs. Los costos de licencia son de $1000 por mes.
Enlace de Huggingface:
FLUX.1-Kontext-dev
Investigación
¿Texto a… Lora?
¿Qué pasaría si tuvieras un LLM que, en lugar de recibir texto y producir más texto, en cambio recibiera texto y produjera otro LLM? Esa es la idea detrás de las hiperrredes, que son modelos de aprendizaje profundo que, dado un input, producen un nuevo modelo adaptado para tu input.
Sakana Labs, un laboratorio de investigación japonés, ha lanzado una de las primeras hiperrredes prácticas(-ish). El modelo recibe una descripción de texto de tu tarea, y luego el modelo producirá un adaptador lora que puedes usar, sin necesidad de datos.
Puedes leer el artículo para ver cómo lo hicieron, o ejecutar la demostración que tienen en su Github para ver qué tan bien funciona para tu tarea. Es una tecnología muy nueva, por lo que solo funcionará realmente para dominios similares en los que fue entrenada, pero es emocionante verla como el futuro potencial del (no) ajuste fino.
¿Pueden los LLMs realmente ver?
¿Alguna vez has notado que los LLMs parecen no ser capaces de razonar o entender imágenes tan bien como lo hacen con el texto? A menudo, incluir una imagen parece desconcertar al modelo y hace que funcione peor.
Hasta ahora, eso era solo una sensación que tenía de prácticamente todos los LLMs multimodales, ¡pero ahora tenemos confirmación de esto!
Los autores de ReadBench fueron y tomaron preguntas de diferentes benchmarks de texto, y las pusieron en una imagen para que la IA las leyera y respondiera en lugar de usar texto. Lo que encontraron es que los modelos funcionan peor en todos los ámbitos cuando usan imágenes como entrada.
Diferencia de puntuación de benchmark entre texto e imagen
Así que si tus pipelines RAG mantienen tus PDF como imágenes en lugar de analizarlos en texto, es posible que quieras reconsiderarlo.
Conclusión
Esto concluye la primera edición de las noticias semanales. Gracias por leer.