News
Google’s decay
Google’s AI team has been struggling as of late.
Their Gemini 3.1 Pro and Flash 3.5 models have failed to impress, taking them out of the conversation as a frontier lab.
With the rise of the Chinese AI labs, who have orders of magnitude less compute yet are still competitive if not better than the Gemini models, things have not been looking good for Google, who seem to have been unable to figure out the post training of their models.
They have even lost their spot as the multimodal kings, as OpenAI has been focusing more on these capabilities and have been able to surpass Gemini.
Because of this poor performance, they are starting to lose their superstar researchers.
The first to leave this week was Noah Shazeer.
Even if you don’t know Noam Shazeer, you do know his work.
He is arguably the most important figure in modern AI, being credited with coming up with the modern attention mechanism we use in transformers (the main breakthrough in the Attention is All you Need paper) and also being one of the creators of sparse mixture of experts models, which has allowed us to efficiently scale LLMs to their current size.
To call him the Kobe or Messi of AI undersells him, he is more like AI Jesus, without him the field would not be where it is today.
He left Google originally back in 2022 to start a startup called Character.ai, but was acquihired back to Google in 2024 for 2.7 billion dollars.
Just 18 months later, he is jumping ship again, this time heading over to OpenAI, for what I can only assume is a ridiculous amount of money.
The other major departure this week was John Jumper, the project lead for the noble prize winning AlphaFold team, announced he will be going to Anthropic.
AlphaFold will probably go down as Demis Hassabis’ and DeepMind’s greatest achievement (there’s a reason they won a Nobel prize for it), so to lose the person that led that project is another large blow to the organization.

Because of these researchers achievements, I can imagine that Google offered them the world, but because of the direction or culture of the Google DeepMind org, they decided to jump ship.
Its also interesting that they went to different competitors, showing that Anthropic and OpenAI are both considered top labs by the best in the field, and that which one is best depends on your own views; there is no definitive best that everyone is going to.
As for Google, I don’t see them coming back from this.
Their models have been getting worse relative to the competition (and they know it), and now losing two of their most well regarded researchers will cause further exodus, similar to Meta after Llama 4 release, where they reportedly lost 80% of their AI team due to how poorly their model performed.
This is despite Google having the most compute of any of the major AI labs, which shows that your compute is only as good as the people that are using it, and that scale is not all that you need.
Releases
GLM 5.2
As one giant dies, another emerges, as Z.ai has released GLM 5.2, which is competitive with GPT 5.5 and Opus 4.8.
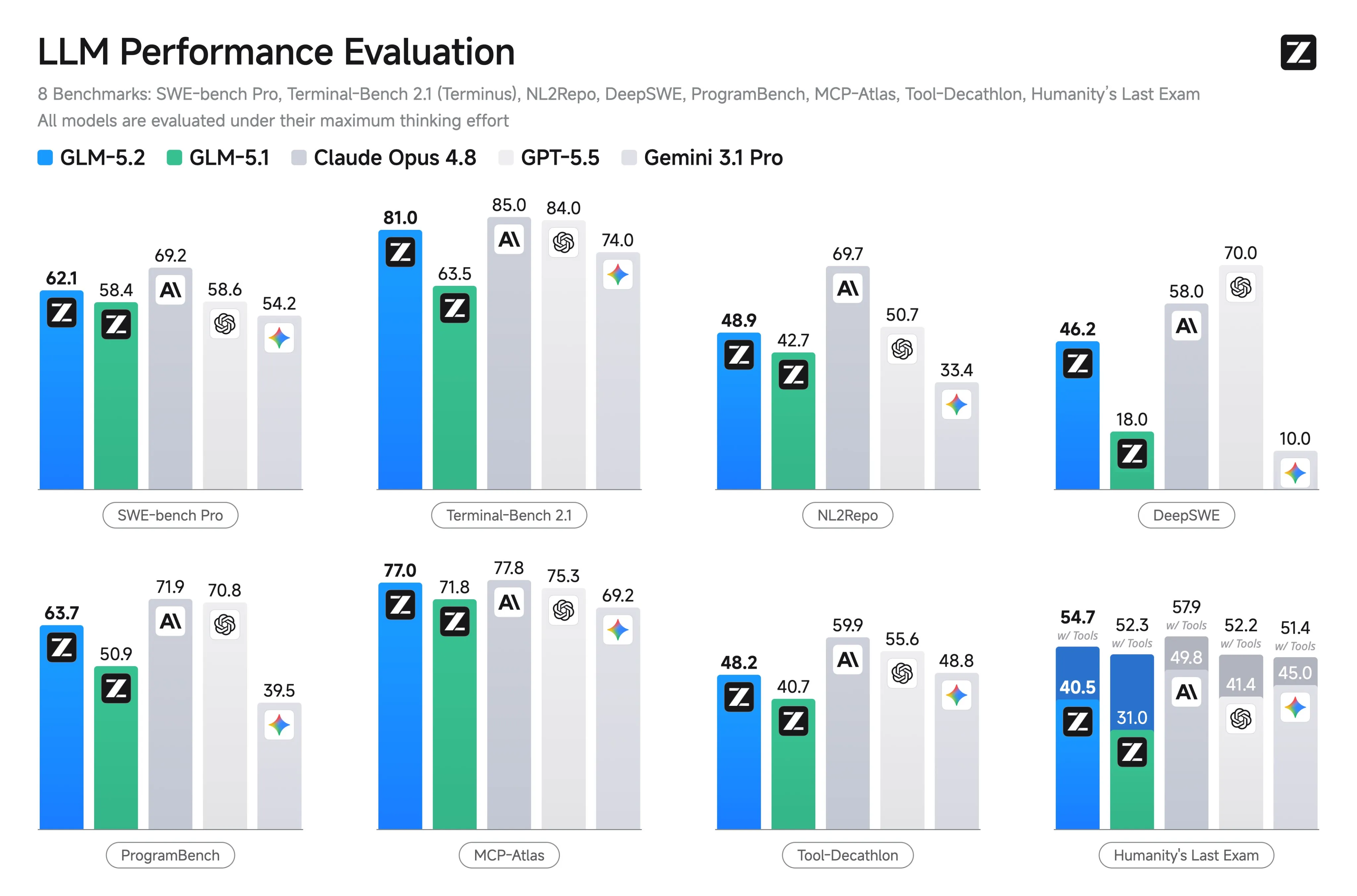
On the high signal DeepSWE benchmark, where Chinese models have struggled, we see a major improvement.
The Chinese models also tend to struggle on newer benchmarks because their models are not very general and they have not had time to overfit on the benchmarks.
Looking at the performance of GLM on benchmarks released this week, we see a different story.
On shape-rotator bench, we see GLM 5.2 outperforming Opus 4.8.
On Artificial Analysis’s new agentic long context knowledge work benchmark, GLM 5.2 is the 3rd best model, falling behind only Fable 5 and Opus 4.8, but beating GPT 5.5.
On KernelBench-Mega and hard, it gets better speedups than GPT 5.5 and every other open source model, only losing to Opus 4.8.
On some of the less concrete/ soft skills benchmarks we also see strong performance.
On Design Arena, GLM 5.2 takes first place, beating out Fable 5.
On EQ bench (creative writing and emotional intelligence) it beats all other open source models, including Kimi, which has historically been a very strong writing model.
It also passes the real world vibe check.
I have seen many people compare the model to GPT 5.5 and Opus 4.8 in terms of quality, and that it is no longer a model they fall back to when they run into rate limits with Claude or GPT, but rather it is a model you can daily drive with little intelligence penalty.
It does this while being 1/3 the price of GPT 5.5 and 1/5 the price of Opus according to Artifical Analysis.
This is very exciting to see, and it is probably the smallest gap we have had between open and closed source models since DeepSeek R1. I expect the other Chinese labs to also catch up in the following months, which will only heat up the frontier LLM battle even more.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

From Akiitopiia on TwitterNota: Este artigo foi traduzido automaticamente com OpenAI GPT-5.5 por meio do Codex CLI; a qualidade pode estar reduzida, especialmente na terminologia técnica.
resumo
- O declínio do Google está ficando cada vez mais aparente
- O GLM 5.2 diminui a distância para o GPT 5.5 e o Claude Opus 4.8
Notícias
A decadência do Google
A equipe de IA do Google vem enfrentando dificuldades ultimamente.
Seus modelos Gemini 3.1 Pro e Flash 3.5 não conseguiram impressionar, tirando a empresa da conversa como um laboratório de fronteira.
Com a ascensão dos laboratórios chineses de IA, que têm ordens de magnitude menos capacidade computacional e ainda assim continuam competitivos, quando não melhores que os modelos Gemini, as coisas não têm parecido boas para o Google, que parece não ter conseguido entender o pós-treinamento de seus modelos.
Eles até perderam seu posto como reis do multimodal, já que a OpenAI tem se concentrado mais nessas capacidades e conseguiu superar o Gemini.
Por causa desse desempenho fraco, eles estão começando a perder seus pesquisadores superstar.
O primeiro a sair esta semana foi Noah Shazeer.
Mesmo que você não conheça Noam Shazeer, você conhece o trabalho dele.
Ele é possivelmente a figura mais importante da IA moderna, sendo creditado por ter concebido o mecanismo de atenção moderno que usamos em transformers (o principal avanço do artigo Attention is All you Need) e também por ser um dos criadores dos modelos sparse mixture of experts, que nos permitiram escalar LLMs de forma eficiente até o tamanho atual.
Cham á-lo de Kobe ou Messi da IA é subestimá-lo; ele é mais como o Jesus da IA. Sem ele, o campo não estaria onde está hoje.
Ele saiu originalmente do Google em 2022 para fundar uma startup chamada Character.ai, mas foi reacqui-contratado pelo Google em 2024 por 2,7 bilhões de dólares.
Apenas 18 meses depois, ele está abandonando o barco novamente, desta vez indo para a OpenAI, pelo que só posso presumir ser uma quantidade ridícula de dinheiro.
A outra grande saída desta semana foi John Jumper, o líder do projeto da equipe AlphaFold, vencedora do Prêmio Nobel, que anunciou que irá para a Anthropic.
O AlphaFold provavelmente ficará na história como a maior conquista de Demis Hassabis e da DeepMind (há um motivo para terem vencido um Prêmio Nobel por isso), então perder a pessoa que liderou esse projeto é outro grande golpe para a organização.
Por causa das conquistas desses pesquisadores, imagino que o Google tenha oferecido o mundo a eles, mas, por causa da direção ou da cultura da organização Google DeepMind, eles decidiram abandonar o barco.
Também é interessante que eles tenham ido para concorrentes diferentes, mostrando que Anthropic e OpenAI são ambas consideradas laboratórios de ponta pelos melhores da área, e que qual delas é a melhor depende das suas próprias visões; não há uma melhor definitiva para a qual todo mundo esteja indo.
Quanto ao Google, não vejo a empresa se recuperando disso.
Seus modelos vêm piorando em relação à concorrência (e eles sabem disso), e agora perder dois de seus pesquisadores mais respeitados causará uma evasão ainda maior, semelhante à da Meta após o lançamento do Llama 4, quando, segundo relatos, ela perdeu 80% de sua equipe de IA devido ao desempenho ruim do modelo.
Isso apesar de o Google ter a maior capacidade computacional entre todos os grandes laboratórios de IA, o que mostra que sua computação só é tão boa quanto as pessoas que a usam, e que escala não é tudo de que você precisa.
Lançamentos
GLM 5.2
Enquanto um gigante morre, outro emerge, já que a Z.ai lançou o GLM 5.2, que é competitivo com o GPT 5.5 e o Opus 4.8.
No benchmark de alto sinal DeepSWE, no qual os modelos chineses têm tido dificuldades, vemos uma grande melhora.
Os modelos chineses também tendem a ter dificuldades em benchmarks mais recentes porque seus modelos não são muito gerais e eles não tiveram tempo para fazer overfit nos benchmarks.
Olhando para o desempenho do GLM em benchmarks lançados esta semana, vemos uma história diferente.
No shape-rotator bench, vemos o GLM 5.2 superando o Opus 4.8.
No novo benchmark de trabalho de conhecimento agêntico em contexto longo da Artificial Analysis, o GLM 5.2 é o 3º melhor modelo, ficando atrás apenas do Fable 5 e do Opus 4.8, mas superando o GPT 5.5.
No KernelBench-Mega e hard, ele obtém acelerações melhores que o GPT 5.5 e todos os outros modelos de código aberto, perdendo apenas para o Opus 4.8.
Em alguns dos benchmarks menos concretos/de habilidades mais subjetivas, também vemos um desempenho forte.
No Design Arena, o GLM 5.2 fica em primeiro lugar, superando o Fable 5.
No EQ bench (escrita criativa e inteligência emocional), ele supera todos os outros modelos de código aberto, incluindo o Kimi, que historicamente tem sido um modelo de escrita muito forte.
Ele também passa no teste de uso real.
Vi muitas pessoas compararem o modelo ao GPT 5.5 e ao Opus 4.8 em termos de qualidade, e dizerem que ele já não é mais um modelo ao qual recorrem quando atingem limites de taxa no Claude ou no GPT, mas sim um modelo que você pode usar no dia a dia com pouca perda de inteligência.
Ele faz isso custando 1/3 do preço do GPT 5.5 e 1/5 do preço do Opus, de acordo com a Artifical Analysis.
Isso é muito empolgante de ver, e provavelmente é a menor distância que tivemos entre modelos de código aberto e de código fechado desde o DeepSeek R1. Espero que os outros laboratórios chineses também alcancem esse nível nos próximos meses, o que só vai esquentar ainda mais a batalha dos LLMs de fronteira.
Final
Espero que você tenha gostado das notícias desta semana. Se quiser receber as notícias toda semana, não deixe de entrar na nossa lista de e-mails abaixo.
De Akiitopiia no TwitterNota: Este artículo fue traducido automáticamente con OpenAI GPT-5.5 mediante Codex CLI; la calidad puede verse degradada, especialmente en la terminología técnica.
Noticias
La decadencia de Google
El equipo de IA de Google ha estado teniendo dificultades últimamente.
Sus modelos Gemini 3.1 Pro y Flash 3.5 no han logrado impresionar, sacándolos de la conversación como laboratorio de frontera.
Con el auge de los laboratorios chinos de IA, que tienen órdenes de magnitud menos cómputo y aun así siguen siendo competitivos, si no mejores que los modelos Gemini, las cosas no han pintado bien para Google, que parece no haber sido capaz de resolver el post-entrenamiento de sus modelos.
Incluso han perdido su puesto como reyes multimodales, ya que OpenAI se ha centrado más en estas capacidades y ha logrado superar a Gemini.
Debido a este bajo rendimiento, están empezando a perder a sus investigadores estrella.
El primero en irse esta semana fue Noah Shazeer.
Aunque no conozcas a Noam Shazeer, sí conoces su trabajo.
Probablemente sea la figura más importante de la IA moderna, ya que se le atribuye haber ideado el mecanismo de atención moderno que usamos en los transformers (el avance principal del artículo Attention is All you Need) y también ser uno de los creadores de los modelos sparse mixture of experts, lo que nos ha permitido escalar eficientemente los LLMs hasta su tamaño actual.
Llamarlo el Kobe o el Messi de la IA se queda corto; es más bien el Jesús de la IA. Sin él, el campo no estaría donde está hoy.
Originalmente dejó Google en 2022 para fundar una startup llamada Character.ai, pero Google lo readquirió mediante acquihire en 2024 por 2.700 millones de dólares.
Solo 18 meses después, vuelve a abandonar el barco, esta vez rumbo a OpenAI, por lo que solo puedo asumir que es una cantidad ridícula de dinero.
La otra gran salida de esta semana fue John Jumper, el líder del proyecto del equipo de AlphaFold ganador del premio Nobel, quien anunció que se irá a Anthropic.
AlphaFold probablemente pasará a la historia como el mayor logro de Demis Hassabis y DeepMind (hay una razón por la que ganaron un Nobel por ello), así que perder a la persona que lideró ese proyecto es otro gran golpe para la organización.
Debido a los logros de estos investigadores, imagino que Google les ofreció el mundo, pero por la dirección o la cultura de la organización Google DeepMind decidieron abandonar el barco.
También es interesante que se fueran a competidores diferentes, lo que muestra que Anthropic y OpenAI son considerados laboratorios de primer nivel por los mejores del campo, y que cuál es el mejor depende de tus propias opiniones; no hay un mejor definitivo al que todo el mundo vaya.
En cuanto a Google, no los veo recuperándose de esto.
Sus modelos han ido empeorando en relación con la competencia (y ellos lo saben), y ahora perder a dos de sus investigadores más respetados provocará un éxodo aún mayor, similar a Meta tras el lanzamiento de Llama 4, cuando supuestamente perdieron el 80% de su equipo de IA debido a lo mal que rindió su modelo.
Todo esto a pesar de que Google tiene más cómputo que cualquiera de los grandes laboratorios de IA, lo que muestra que tu cómputo solo es tan bueno como las personas que lo usan, y que escalar no es todo lo que necesitas.
Lanzamientos
GLM 5.2
Mientras un gigante muere, otro emerge, ya que Z.ai ha lanzado GLM 5.2, que es competitivo con GPT 5.5 y Opus 4.8.
En el benchmark de alta señal DeepSWE, donde los modelos chinos han tenido dificultades, vemos una mejora importante.
Los modelos chinos también tienden a sufrir en benchmarks más nuevos porque sus modelos no son muy generales y no han tenido tiempo de sobreajustarse a los benchmarks.
Al observar el rendimiento de GLM en benchmarks publicados esta semana, vemos una historia diferente.
En shape-rotator bench, vemos que GLM 5.2 supera a Opus 4.8.
En el nuevo benchmark de trabajo de conocimiento agéntico de contexto largo de Artificial Analysis, GLM 5.2 es el tercer mejor modelo, quedando solo por detrás de Fable 5 y Opus 4.8, pero superando a GPT 5.5.
En KernelBench-Mega y hard, consigue mejores aceleraciones que GPT 5.5 y que cualquier otro modelo open source, perdiendo solo ante Opus 4.8.
En algunos de los benchmarks menos concretos/de habilidades blandas también vemos un rendimiento sólido.
En Design Arena, GLM 5.2 queda en primer lugar, superando a Fable 5.
En EQ bench (escritura creativa e inteligencia emocional), supera a todos los demás modelos open source, incluido Kimi, que históricamente ha sido un modelo de escritura muy fuerte.
También pasa la prueba de sensaciones en el mundo real.
He visto a muchas personas comparar el modelo con GPT 5.5 y Opus 4.8 en términos de calidad, y decir que ya no es un modelo al que recurren cuando se topan con límites de tasa en Claude o GPT, sino un modelo que puedes usar a diario con poca penalización de inteligencia.
Logra esto costando 1/3 del precio de GPT 5.5 y 1/5 del precio de Opus según Artifical Analysis.
Esto es muy emocionante de ver, y probablemente sea la brecha más pequeña que hemos tenido entre modelos open source y cerrados desde DeepSeek R1. Espero que los otros laboratorios chinos también se pongan al día en los próximos meses, lo que no hará más que intensificar aún más la batalla de los LLMs de frontera.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo abajo.
De Akiitopiia en Twitter