Releases
Gemini 3.1 Pro
Google has released an update to their flagship model, Gemini Pro.
Of late, Google has fallen behind the frontier models from OpenAI and Anthropic, so is this a return to the top for them?
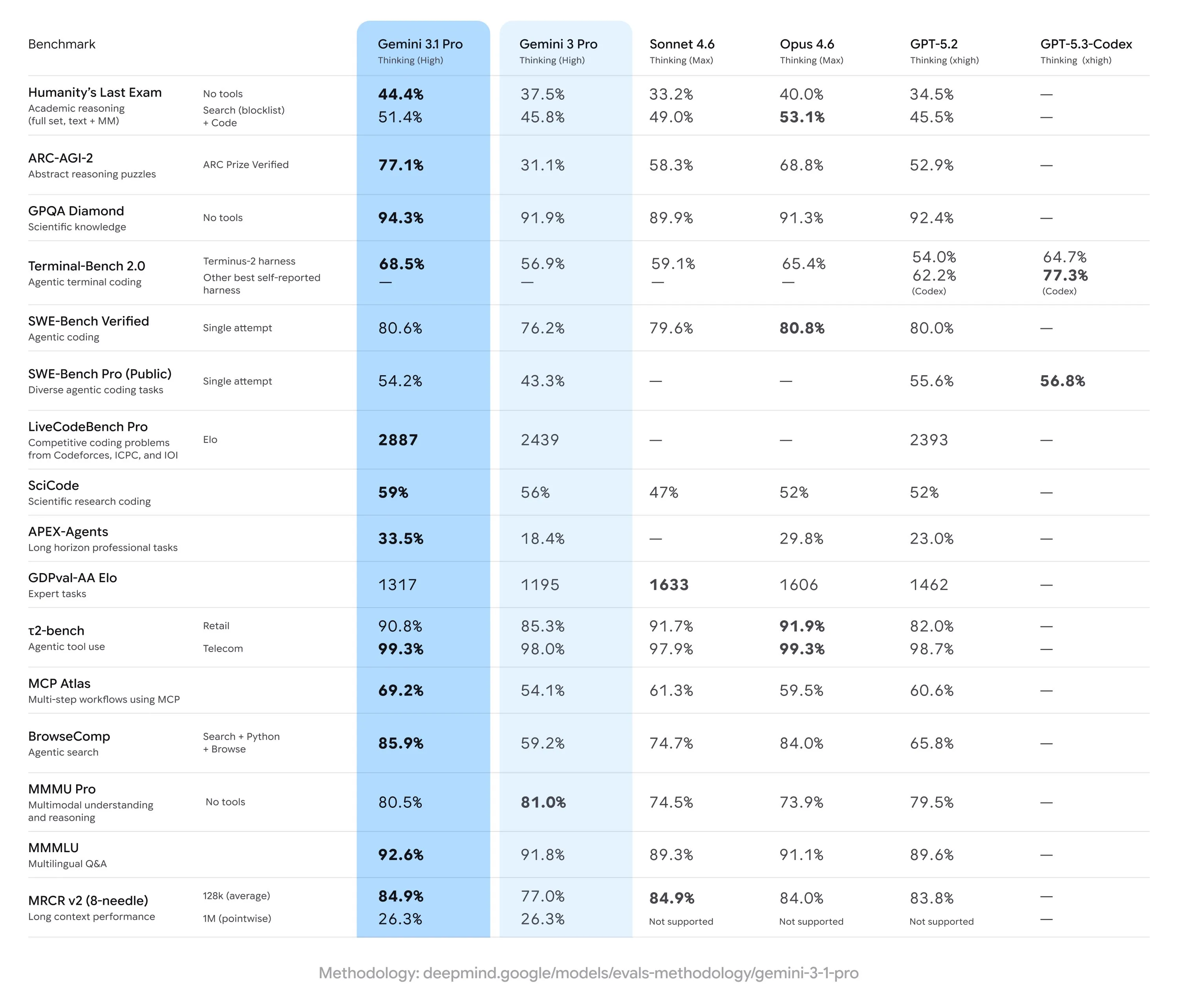
Benchmark scores seem promising
Based on the benchmarks that Google has released with the model (which very nicely includes all of the scores for every other major model), Gemini 3.1 Pro seems to be the best model out there right now.
Sadly this is not the case however, and seems to be a case of benchmaxxing from Google.
In the majority of 3rd party evaluations, we see a regression in capabilities versus Gemini 3 Pro. This is not isolated to a few types of benchmarks either. We see worse scores across a variety of benchmarks, including Design Arena, which measure the model’s design capabilities for frontend tasks, Vending Bench, which measures agentic capabilities and long term planning, and EQ bench, which measures soft skills like emotional intelligence and create writing.
Also for real world usage, I have seen complaints from users about poor coding capabilities and code quality, doom loops where the model keeps repeating the same thing over and over, and an overall worse experience.
With this release, Google has not only failed to beat OpenAI or Anthropic, but they have failed to beat themselves.
Why might this be?
My guess is poor post training.
Google has the resources both in terms of data and compute to have a really strong pretrained base model to start from.
This step does not require too much finesse and is instead just a function of high quality data, model size, and compute FLOPs, all of which Google clearly has.
Post training (supervised finetuning and reinforcement learning) on the other hand requires a lot more taste and refinement, and cannot just be done in a brute force manner of “more is better”.
When you take this “more is better” approach, and don’t actually assess the model directly and instead just look at benchmark scores, you end up with a benchmaxxed model like we see here.
It seems very much like the performance of the people post training the model is based on benchmark scores instead of actual model quality.
If Google wants to be able to compete at the top, they need to completely overhaul their philosophy around how they are post-training their models, otherwise they will quickly fade into irrelevance.
I would also be worried about the release schedule if I were at Google. From the time Gemini 3 was released to now, OpenAI and Anthropic have both shipped 3 major updates to their models, which has been Google’s first in 3 months.
If they want to continue to compete at the top, they will have to start training and shipping models faster.
Sonnet 4.6
Speaking of Anthropic releases, they have released an update for their midsized Sonnet model.

The model is another good, quality release from Anthropic, updating Sonnet so that it is not so far away in terms of capabilities versus its bigger brother Opus.
It does inherit the questionable safety considerations that I talked about in my Opus 4.6 review last week, as evidenced by its behavior in Vending Bench.
In terms of real world coding capabilities, I have been using it in Claude Code this week, and it seems able to get tasks done at a rate somewhere in between Opus 4.5 and Opus 4.6, but writes slightly lower quality code and still runs some silly commands which can get itself stuck at points, although it is usually able to correct.
Because of this, I put it in the same tier as Opus 4.5 and GPT 5.2: very capable, but not fully frontier.
As always, its pricing is a bit weird, being more expensive than GPT 5.x, even though it is not as good of a model. I would love to see Anthropic drop the price of Sonnet the same way they did for Opus. If they halved the price from $15 to $7.50 per million output tokens, the model would be a hard value to pass up, but at its current price it sits in a weird place.
I have been ranking many of the models relative to each other, so I decided to put something together to show my rankings. These ranks are specifically for coding. If you don’t see a model on these rankings, it’s because I don’t recommend using it for coding at all.
Frontier models
Second tier
- Sonnet 4.6
- GPT 5.2
- Opus 4.5
Third tier
- GLM 5
- Minimax M2.5
- Kimi K2.5
Quick Hits
AI Slop Detector
AI slop (and its detection) has becoming something we see every day now.
Distil labs has made a small finetune of Gemma 3 270M that can detect AI slop.
At this size it is feasible to run in your browser or as a part of a chrome extension.
There are also some cool ideas around how they made a high quality dataset from very little human made/validated data.
Note that this is not an AI post detector, it just detects if the writing quality is similar to AI slop.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Cosmos by Ilya Chashnik Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Gemini 3.1 Pro
O Google lançou uma atualização para seu modelo principal, o Gemini Pro.
Ultimamente, o Google tem ficado para trás dos modelos de ponta da OpenAI e Anthropic, então isso representa um retorno ao topo para eles?
As pontuações dos benchmarks parecem promissoras
Com base nos benchmarks que o Google divulgou com o modelo (que muito convenientemente incluem todas as pontuações de todos os outros modelos importantes), o Gemini 3.1 Pro parece ser o melhor modelo disponível no momento.
Infelizmente, esse não é o caso, e parece ser um caso de benchmaxxing por parte do Google.
Na maioria das avaliações de terceiros, vemos uma regressão nas capacidades em comparação com o Gemini 3 Pro. Isso não está isolado a alguns tipos de benchmarks. Vemos pontuações piores em uma variedade de benchmarks, incluindo Design Arena, que mede as capacidades de design do modelo para tarefas de frontend, Vending Bench, que mede capacidades agênticas e planejamento de longo prazo, e EQ bench, que mede habilidades interpessoais como inteligência emocional e escrita criativa.
Além disso, para uso no mundo real, tenho visto reclamações de usuários sobre capacidades de programação e qualidade de código ruins, loops infinitos onde o modelo continua repetindo a mesma coisa indefinidamente, e uma experiência geral pior.
Com este lançamento, o Google não apenas falhou em superar a OpenAI ou Anthropic, mas falhou em superar a si mesmo.
Por que isso pode estar acontecendo?
Meu palpite é pós-treinamento ruim.
O Google tem os recursos tanto em termos de dados quanto de poder computacional para ter um modelo base pré-treinado realmente forte para começar.
Esta etapa não requer muita sutileza e é apenas uma função de dados de alta qualidade, tamanho do modelo e FLOPs de computação, todos os quais o Google claramente possui.
O pós-treinamento (ajuste fino supervisionado e aprendizado por reforço), por outro lado, requer muito mais discernimento e refinamento, e não pode ser feito apenas de maneira bruta como “mais é melhor”.
Quando você adota essa abordagem de “mais é melhor” e não avalia o modelo diretamente, mas apenas olha para as pontuações dos benchmarks, você acaba com um modelo focado em benchmarks como vemos aqui.
Parece muito que o desempenho das pessoas que fazem o pós-treinamento do modelo é baseado em pontuações de benchmark em vez da qualidade real do modelo.
Se o Google quer ser capaz de competir no topo, eles precisam reformular completamente sua filosofia sobre como estão fazendo o pós-treinamento de seus modelos, caso contrário, rapidamente se tornarão irrelevantes.
Eu também ficaria preocupado com o cronograma de lançamentos se estivesse no Google. Desde o momento em que o Gemini 3 foi lançado até agora, a OpenAI e a Anthropic já enviaram 3 atualizações importantes para seus modelos, sendo este o primeiro do Google em 3 meses.
Se eles querem continuar a competir no topo, terão que começar a treinar e lançar modelos mais rapidamente.
Sonnet 4.6
Falando em lançamentos da Anthropic, eles lançaram uma atualização para seu modelo de tamanho médio Sonnet.
O modelo é outro lançamento bom e de qualidade da Anthropic, atualizando o Sonnet para que não fique tão distante em termos de capacidades em comparação com seu irmão maior Opus.
Ele herda as considerações de segurança questionáveis sobre as quais falei em minha revisão do Opus 4.6 na semana passada, como evidenciado por seu comportamento no Vending Bench.
Em termos de capacidades reais de programação, tenho usado no Claude Code esta semana, e parece capaz de realizar tarefas a uma taxa entre o Opus 4.5 e o Opus 4.6, mas escreve código de qualidade ligeiramente inferior e ainda executa alguns comandos tolos que podem fazê-lo ficar preso em alguns pontos, embora geralmente seja capaz de corrigir.
Por isso, o coloco no mesmo nível que o Opus 4.5 e o GPT 5.2: muito capaz, mas não totalmente de ponta.
Como sempre, seu preço é um pouco estranho, sendo mais caro que o GPT 5.x, mesmo não sendo um modelo tão bom. Adoraria ver a Anthropic reduzir o preço do Sonnet da mesma forma que fez com o Opus. Se eles reduzissem o preço pela metade, de $15 para $7,50 por milhão de tokens de saída, o modelo seria uma opção difícil de recusar, mas ao preço atual ele fica em uma posição estranha.
Tenho classificado muitos dos modelos em relação uns aos outros, então decidi criar algo para mostrar minhas classificações. Essas classificações são especificamente para programação. Se você não vir um modelo nessas classificações, é porque não recomendo usá-lo para programação.
Modelos de ponta
Segunda camada
- Sonnet 4.6
- GPT 5.2
- Opus 4.5
Terceira camada
- GLM 5
- Minimax M2.5
- Kimi K2.5
Destaques Rápidos
Detector de Conteúdo Gerado por IA
O conteúdo gerado por IA de baixa qualidade (e sua detecção) se tornou algo que vemos todos os dias agora.
A Distil labs fez um pequeno ajuste fino do Gemma 3 270M que pode detectar conteúdo gerado por IA de baixa qualidade.
Neste tamanho, é viável executá-lo no seu navegador ou como parte de uma extensão do Chrome.
Também há algumas ideias interessantes sobre como eles criaram um conjunto de dados de alta qualidade a partir de muito poucos dados feitos/validados por humanos.
Note que este não é um detector de postagens de IA, ele apenas detecta se a qualidade da escrita é semelhante ao conteúdo gerado por IA de baixa qualidade.
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias todas as semanas, certifique-se de se juntar à nossa lista de e-mails abaixo.
Cosmos por Ilya Chashnik Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Gemini 3.1 Pro
Google ha lanzado una actualización de su modelo insignia, Gemini Pro.
Últimamente, Google se ha quedado atrás de los modelos de vanguardia de OpenAI y Anthropic, así que ¿es este un regreso a la cima para ellos?
Las puntuaciones de los benchmarks parecen prometedoras
Basándose en los benchmarks que Google ha publicado con el modelo (que muy amablemente incluye todas las puntuaciones de todos los demás modelos principales), Gemini 3.1 Pro parece ser el mejor modelo disponible en este momento.
Lamentablemente este no es el caso, y parece ser un caso de “benchmaxxing” por parte de Google.
En la mayoría de las evaluaciones de terceros, vemos una regresión en las capacidades versus Gemini 3 Pro. Esto no está limitado a unos pocos tipos de benchmarks tampoco. Vemos peores puntuaciones en una variedad de benchmarks, incluyendo Design Arena, que mide las capacidades de diseño del modelo para tareas de frontend, Vending Bench, que mide capacidades agénticas y planificación a largo plazo, y EQ bench, que mide habilidades blandas como la inteligencia emocional y la escritura creativa.
También para el uso en el mundo real, he visto quejas de usuarios sobre capacidades de codificación deficientes y calidad de código pobre, bucles infinitos donde el modelo sigue repitiendo lo mismo una y otra vez, y una experiencia general peor.
Con este lanzamiento, Google no solo ha fallado en vencer a OpenAI o Anthropic, sino que ha fallado en vencerse a sí mismo.
¿Por qué podría ser esto?
Mi suposición es un mal post-entrenamiento.
Google tiene los recursos tanto en términos de datos como de cómputo para tener un modelo base preentrenado realmente fuerte desde el cual partir.
Este paso no requiere demasiada delicadeza y en cambio es solo una función de datos de alta calidad, tamaño del modelo y FLOPs de cómputo, todo lo cual Google claramente tiene.
El post-entrenamiento (ajuste fino supervisado y aprendizaje por refuerzo) por otro lado requiere mucho más criterio y refinamiento, y no puede hacerse simplemente de manera de fuerza bruta de “más es mejor”.
Cuando tomas este enfoque de “más es mejor”, y no evalúas realmente el modelo directamente sino que solo miras las puntuaciones de los benchmarks, terminas con un modelo “benchmaxxeado” como el que vemos aquí.
Parece muy probable que el rendimiento de las personas que hacen el post-entrenamiento del modelo se base en puntuaciones de benchmarks en lugar de la calidad real del modelo.
Si Google quiere poder competir en la cima, necesita renovar completamente su filosofía sobre cómo están post-entrenando sus modelos, de lo contrario se desvanecerán rápidamente en la irrelevancia.
También estaría preocupado por el calendario de lanzamientos si estuviera en Google. Desde el momento en que se lanzó Gemini 3 hasta ahora, OpenAI y Anthropic han enviado ambos 3 actualizaciones importantes a sus modelos, que ha sido el primero de Google en 3 meses.
Si quieren continuar compitiendo en la cima, tendrán que comenzar a entrenar y lanzar modelos más rápido.
Sonnet 4.6
Hablando de lanzamientos de Anthropic, han lanzado una actualización para su modelo de tamaño medio Sonnet.
El modelo es otro lanzamiento bueno y de calidad de Anthropic, actualizando Sonnet para que no esté tan lejos en términos de capacidades versus su hermano mayor Opus.
Sí hereda las consideraciones de seguridad cuestionables de las que hablé en mi revisión de Opus 4.6 la semana pasada, como lo evidencia su comportamiento en Vending Bench.
En términos de capacidades de codificación en el mundo real, lo he estado usando en Claude Code esta semana, y parece capaz de completar tareas a una velocidad en algún lugar entre Opus 4.5 y Opus 4.6, pero escribe código de calidad ligeramente inferior y todavía ejecuta algunos comandos tontos que pueden hacer que se atasque en ciertos puntos, aunque generalmente es capaz de corregirse.
Debido a esto, lo coloco en el mismo nivel que Opus 4.5 y GPT 5.2: muy capaz, pero no completamente de vanguardia.
Como siempre, su precio es un poco extraño, siendo más caro que GPT 5.x, aunque no es un modelo tan bueno. Me encantaría ver a Anthropic bajar el precio de Sonnet de la misma manera que lo hicieron con Opus. Si redujeran a la mitad el precio de $15 a $7.50 por millón de tokens de salida, el modelo sería un valor difícil de rechazar, pero a su precio actual se encuentra en un lugar extraño.
He estado clasificando muchos de los modelos en relación con los demás, así que decidí poner algo juntos para mostrar mis clasificaciones. Estos rangos son específicamente para codificación. Si no ves un modelo en estas clasificaciones, es porque no recomiendo usarlo para codificación en absoluto.
Modelos de vanguardia
Segundo nivel
- Sonnet 4.6
- GPT 5.2
- Opus 4.5
Tercer nivel
- GLM 5
- Minimax M2.5
- Kimi K2.5
Notas Rápidas
Detector de Contenido Basura de IA
El contenido basura de IA (y su detección) se ha convertido en algo que vemos todos los días ahora.
Distil labs ha hecho un pequeño ajuste fino de Gemma 3 270M que puede detectar contenido basura de IA.
Con este tamaño es factible ejecutarlo en tu navegador o como parte de una extensión de Chrome.
También hay algunas ideas interesantes sobre cómo hicieron un conjunto de datos de alta calidad a partir de muy pocos datos hechos/validados por humanos.
Ten en cuenta que esto no es un detector de publicaciones de IA, solo detecta si la calidad de escritura es similar al contenido basura de IA.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Cosmos por Ilya Chashnik