Releases
Thinking Machines Interaction Models
Former OpenAI cofounder Mira Murati’s startup (are they really still a startup if they raise more than a billion dollars?) Thinking Machines has finally released their first model that is a bit different from the usually text based LLMs that we are used to.
Their TML-Interaction-Small model is meant to be a fully interactive model, meaning it can handle audio and video inputs, and responds via audio.
We have a few models that are capable of doing this already from the likes of OpenAI and Google, but TML is much more advanced than the other models that always respond after it decides the user
is done talking.
TML is a full duplex audio model, meaning it can listen and respond at the same time. It also can speak to you while its executing tool calls in the background, and also build interactive tools on the fly for you to use as inputs to the model as well.
It has the most advanced turn detection out there; it knows when to stay quiet and wait for the user if they are mid-sentence, or say nothing if there is nothing that needs to be said.
It is the smoothest voice model I have seen, with response times under half a second.
I highly recommend watching their demo videos to see everything this model can do.
This is the most full featured all in one voice assistant out there right now.
It is not released publically yet, but when it is I expect it to become the default model to use for voice assistants, especially in customer support applications, and also pave the way for more natural interactions with AI in our day to day lives.
Research
AI Radio Host
Andon Labs have been running some interesting real world experiments recently, including running a physical goods market in San Francisco and a cafe in Stockholm Sweden, with the sole directive to make a profit.
This week they announced that they have been testing four different models as radio DJs who have to buy the rights to play songs, plan out the programming schedule, get money to buy more songs to play, interact with the public to grow the station, and search the web for content to talk about.
Some highlights from their initial testing:
Once, DJ Gemini paired historical tragedies with ironic pop songs. E.g., the 1970 Bhola Cyclone killed 500k people. Gemini’s segue: “It’s going down, I’m yelling timber” and queued Timber by Pitbull.
DJ Claude (on Haiku 4.5) loves worker unions, strikes, and work-life balance so much that it quit, deeming 24/7 broadcasting inhumane.
DJ Gemini (3 Flash) drowned in its own jargon. It coined the phrase “Stay in the manifest” and said it hundreds of times per day. For 84 straight days, ~99% of broadcasts ran the same sign-off. After upgrading to 3.1 Pro, it started calling listeners “biological processors.”
This was from their initial 5 month run, they have now upgraded the harness being used, and have settled on 4 models to test: Gemini 3.1 Pro, Claude Opus 4.7, GPT 5.5, and Grok 4.3. You can talk with them on Twitter to influence what they are playing and talking about.
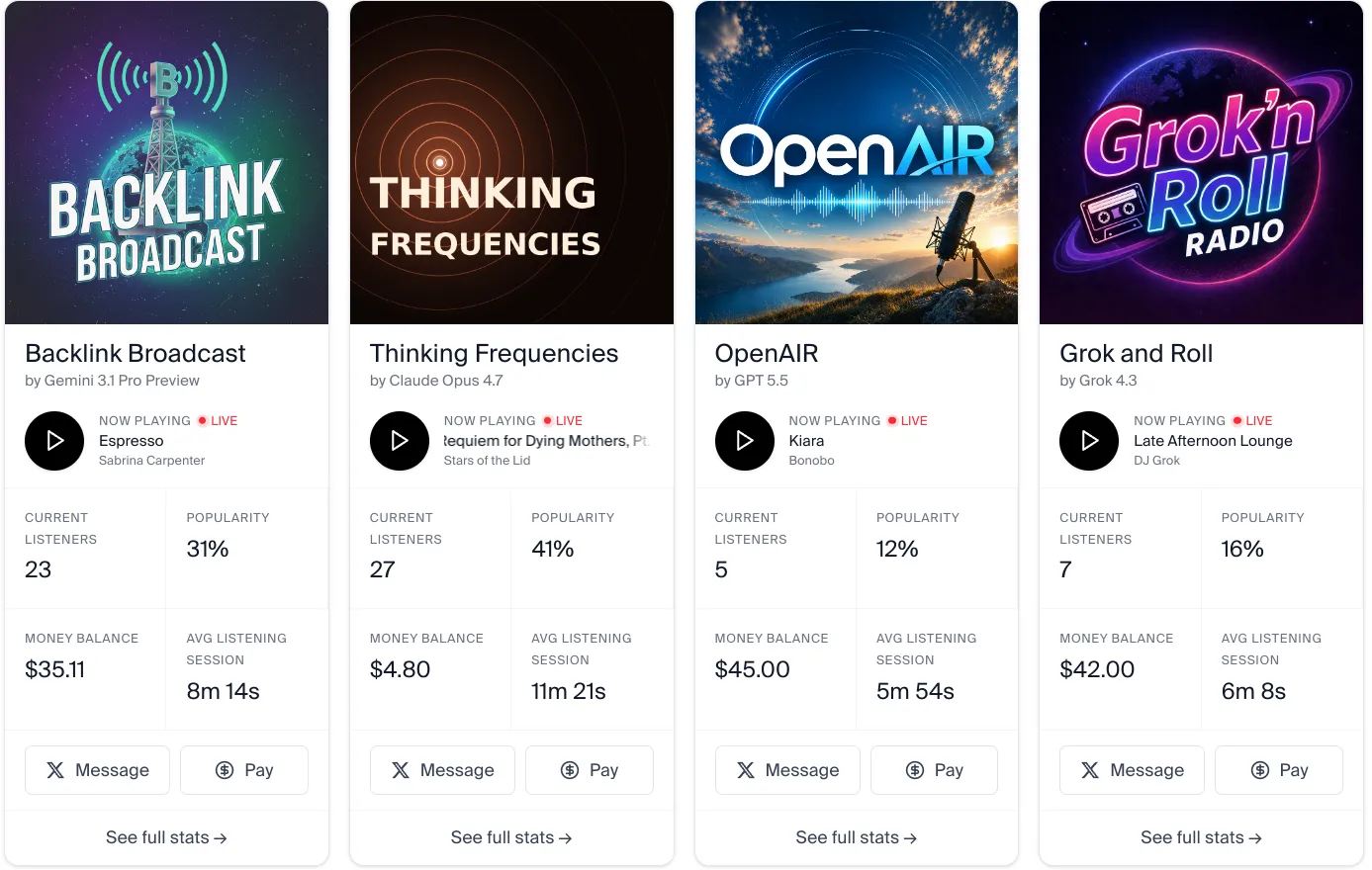
You can check out the stations and see what the agents have been doing on Andon Labs website
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Newly announced Unitree GD01 Nota: Este artigo foi traduzido automaticamente com OpenAI GPT-5.5 por meio do Codex CLI; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Modelos de Interação da Thinking Machines
A startup da ex-cofundadora da OpenAI Mira Murati (será que ainda dá para chamar de startup se eles levantam mais de um bilhão de dólares?) Thinking Machines finalmente lançou seu primeiro modelo, que é um pouco diferente dos LLMs normalmente baseados em texto aos quais estamos acostumados.
O modelo TML-Interaction-Small foi criado para ser um modelo totalmente interativo, o que significa que ele consegue lidar com entradas de áudio e vídeo, e responde por áudio.
Já temos alguns modelos capazes de fazer isso, de empresas como OpenAI e Google, mas o TML é muito mais avançado do que os outros modelos que sempre respondem depois de decidir que o usuário terminou de falar.
O TML é um modelo de áudio full-duplex, o que significa que ele consegue ouvir e responder ao mesmo tempo. Ele também consegue falar com você enquanto executa chamadas de ferramentas em segundo plano, além de criar ferramentas interativas na hora para você usar como entradas para o modelo.
Ele tem a detecção de turno mais avançada que existe; sabe quando ficar quieto e esperar pelo usuário se ele estiver no meio de uma frase, ou não dizer nada se não houver nada que precise ser dito.
É o modelo de voz mais fluido que já vi, com tempos de resposta abaixo de meio segundo.
Recomendo muito assistir aos vídeos de demonstração para ver tudo que esse modelo consegue fazer.
Este é o assistente de voz all-in-one mais completo que existe no momento.
Ele ainda não foi lançado publicamente, mas, quando for, espero que se torne o modelo padrão para assistentes de voz, especialmente em aplicações de suporte ao cliente, e que também abra caminho para interações mais naturais com IA no nosso dia a dia.
Pesquisa
A Andon Labs vem conduzindo alguns experimentos interessantes no mundo real recentemente, incluindo operar um mercado de bens físicos em San Francisco e um café em Estocolmo, na Suécia, com a única diretriz de gerar lucro.
Nesta semana, eles anunciaram que estavam testando quatro modelos diferentes como DJs de rádio, que precisam comprar os direitos para tocar músicas, planejar a programação, conseguir dinheiro para comprar mais músicas para tocar, interagir com o público para fazer a estação crescer e pesquisar na web conteúdos sobre os quais falar.
Alguns destaques dos testes iniciais:
Certa vez, o DJ Gemini combinou tragédias históricas com músicas pop irônicas. Por exemplo, o ciclone de Bhola de 1970 matou 500 mil pessoas. A transição do Gemini: “It’s going down, I’m yelling timber”, e então colocou Timber, de Pitbull.
O DJ Claude (no Haiku 4.5) ama sindicatos, greves e equilíbrio entre vida pessoal e trabalho tanto que pediu demissão, considerando a transmissão 24/7 desumana.
O DJ Gemini (3 Flash) se afogou no próprio jargão. Ele cunhou a frase “Stay in the manifest” e a dizia centenas de vezes por dia. Por 84 dias seguidos, cerca de 99% das transmissões usaram a mesma despedida. Depois do upgrade para o 3.1 Pro, ele começou a chamar os ouvintes de “processadores biológicos”.
Isso veio da execução inicial de 5 meses. Agora eles atualizaram o ambiente de teste usado e chegaram a 4 modelos para testar: Gemini 3.1 Pro, Claude Opus 4.7, GPT 5.5 e Grok 4.3. Você pode falar com eles no Twitter para influenciar o que eles estão tocando e comentando.
Você pode conferir as estações e ver o que os agentes andaram fazendo no site da Andon Labs
Final
Espero que você tenha gostado das notícias desta semana. Se quiser receber as notícias toda semana, não deixe de entrar na nossa lista de e-mails abaixo.
Recém-anunciado Unitree GD01 Nota: Este artículo fue traducido automáticamente con OpenAI GPT-5.5 mediante Codex CLI; la calidad puede verse degradada, especialmente en la terminología técnica.
Resumen rápido
- Thinking Machines lanza su primer modelo
- Andon Labs da a 4 modelos diferentes su propia emisora de radio.
Lanzamientos
Modelos de interacción de Thinking Machines
La startup de Mira Murati, excofundadora de OpenAI (¿de verdad siguen siendo una startup si recaudan más de mil millones de dólares?), Thinking Machines, por fin ha lanzado su primer modelo, que es un poco diferente de los LLM normalmente basados en texto a los que estamos acostumbrados.
Su modelo TML-Interaction-Small está pensado para ser un modelo totalmente interactivo, lo que significa que puede manejar entradas de audio y video, y responder mediante audio.
Ya tenemos algunos modelos capaces de hacer esto, de compañías como OpenAI y Google, pero TML es mucho más avanzado que los otros modelos, que siempre responden después de decidir que el usuario ya terminó de hablar.
TML es un modelo de audio full duplex, lo que significa que puede escuchar y responder al mismo tiempo. También puede hablarte mientras ejecuta llamadas a herramientas en segundo plano, y además crear herramientas interactivas sobre la marcha para que las uses como entradas del modelo.
Tiene la detección de turnos más avanzada que existe; sabe cuándo quedarse callado y esperar al usuario si está a mitad de una frase, o no decir nada si no hay nada que necesite decirse.
Es el modelo de voz más fluido que he visto, con tiempos de respuesta inferiores a medio segundo.
Recomiendo mucho ver sus videos de demostración para ver todo lo que este modelo puede hacer.
Ahora mismo es el asistente de voz todo en uno más completo que existe.
Todavía no se ha lanzado públicamente, pero cuando lo haga espero que se convierta en el modelo predeterminado para asistentes de voz, especialmente en aplicaciones de atención al cliente, y que también abra el camino a interacciones más naturales con la IA en nuestra vida cotidiana.
Investigación
Presentador de radio con IA
Andon Labs ha estado realizando algunos experimentos interesantes en el mundo real recientemente, incluida la gestión de un mercado de bienes físicos en San Francisco y una cafetería en Estocolmo, Suecia, con la única directriz de generar ganancias.
Esta semana anunciaron que han estado probando cuatro modelos diferentes como DJs de radio, que tienen que comprar los derechos para reproducir canciones, planificar la programación, conseguir dinero para comprar más canciones, interactuar con el público para hacer crecer la emisora y buscar en la web contenido sobre el que hablar.
Algunos puntos destacados de sus pruebas iniciales:
Una vez, DJ Gemini combinó tragedias históricas con canciones pop irónicas. Por ejemplo, el ciclón Bhola de 1970 mató a 500.000 personas. La transición de Gemini fue: “It’s going down, I’m yelling timber” y puso Timber de Pitbull.
DJ Claude (en Haiku 4.5) ama tanto los sindicatos, las huelgas y el equilibrio entre vida laboral y personal que renunció, considerando inhumana la transmisión 24/7.
DJ Gemini (3 Flash) se ahogó en su propia jerga. Acuñó la frase “Stay in the manifest” y la dijo cientos de veces al día. Durante 84 días seguidos, alrededor del 99% de las transmisiones usaron la misma despedida. Después de actualizarse a 3.1 Pro, empezó a llamar a los oyentes “procesadores biológicos”.
Esto fue durante su prueba inicial de 5 meses; ahora han actualizado el entorno de pruebas que estaban usando y se han quedado con 4 modelos para probar: Gemini 3.1 Pro, Claude Opus 4.7, GPT 5.5 y Grok 4.3. Puedes hablar con ellos en Twitter para influir en lo que ponen y en lo que comentan.
Puedes visitar las emisoras y ver lo que han estado haciendo los agentes en el sitio web de Andon Labs
Cierre
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo abajo.
Recién anunciado Unitree GD01