PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Qwen Deluge
Qwen releases 10 models in 2 days and can AI replace your job?
Releases
Qwen
Qwen has somehow outdone themselves this week, releasing 10 new products and models, here are the notable ones you should pay attention to. For all of the models I am about to mention (except Qwen Guard) are available to use for FREE on Qwen’s website.
Qwen3 Max
In a departure from their usual open source releases, they dropped their largest model, Qwen3 Max, via API and web interface only. The model is a mixture of experts model and is reportedly over one trillion parameters.
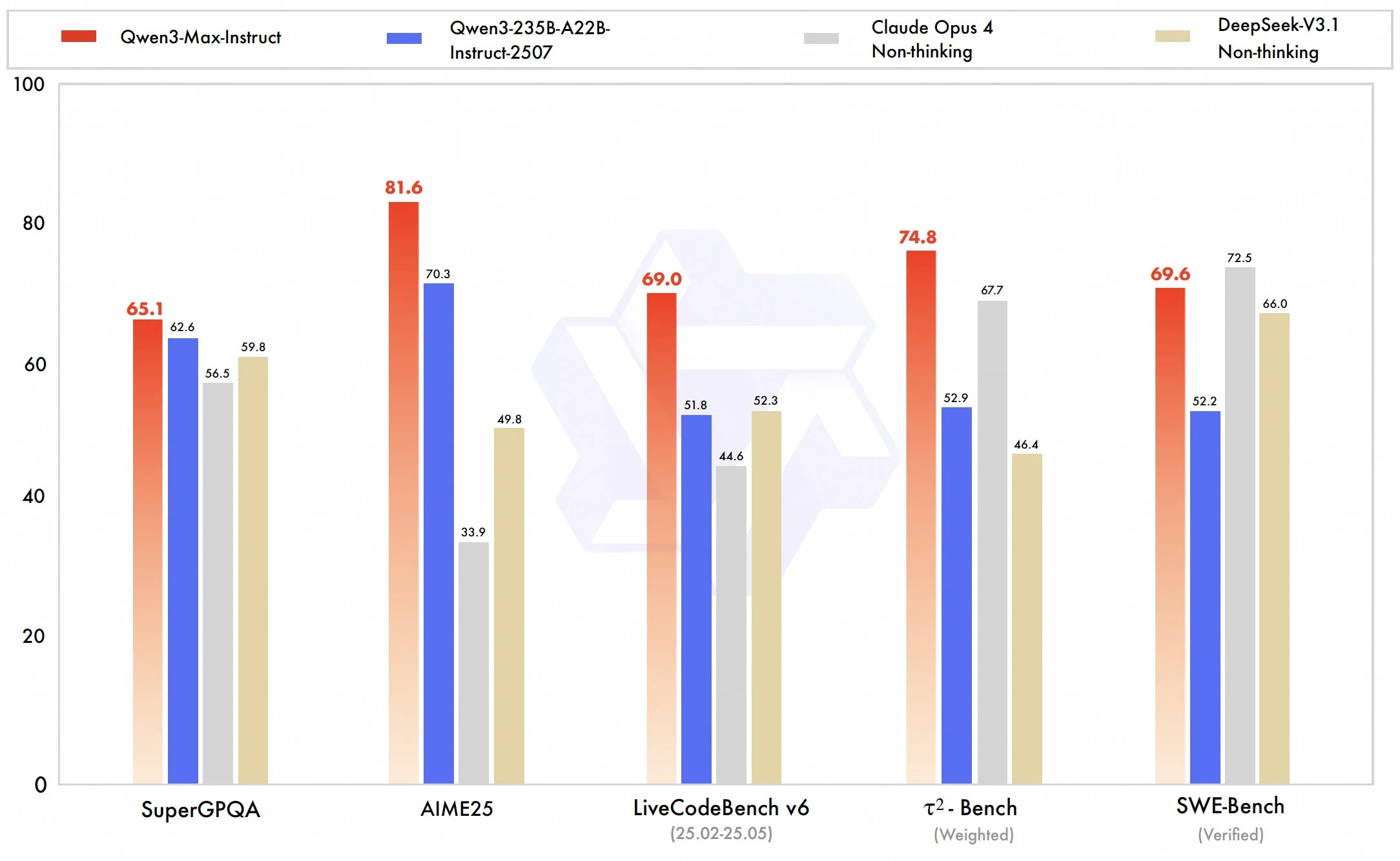
The model benchmarks very well, similar to Claude Opus and DeepSeek 3.1. It also seems to pass the community vibe check with many people reporting strong coding, tool calling, and general writing capabilities. We will have to wait a few more weeks as proper benchmarks for this model get released before we can definitively say this is a frontier level model.
The model is using a tiered pricing depending on how many tokens it uses, which we are seeing more and more of as the usable context window for these LLMs grow.
| Context Length | Input Tokens/Million | Output Tokens/Million |
|---|---|---|
| 0–32K | $1.2 | $6 |
| 32K–128K | $2.4 | $12 |
| 128K–252K | $3 | $15 |
For context, GPT-5 costs $10 per million output tokens, and Claude Sonnet costs $15 per million, putting this model in roughly the same tier as those models, showing Qwen’s confidence in its strength.
Qwen3-VL
The next release is their Qwen3 vision model, built on their 235 billion parameter MOE model. Its benchmarks put it on top across the entire frontier VLM ecosystem, outdoing the incumbent champion Gemini 2.5 Pro on most of the benchmarks tested.
The community vibe check also seems good. I’ve been seeing reports of people saying that it has been able to solve problems that no other VLM had been able to before, including Gemini Pro and GPT-5. Personally, I will now be defaulting to using Qwen3-VL for any multimodal queries I have in the future based on what I have been seeing and hearing about it.
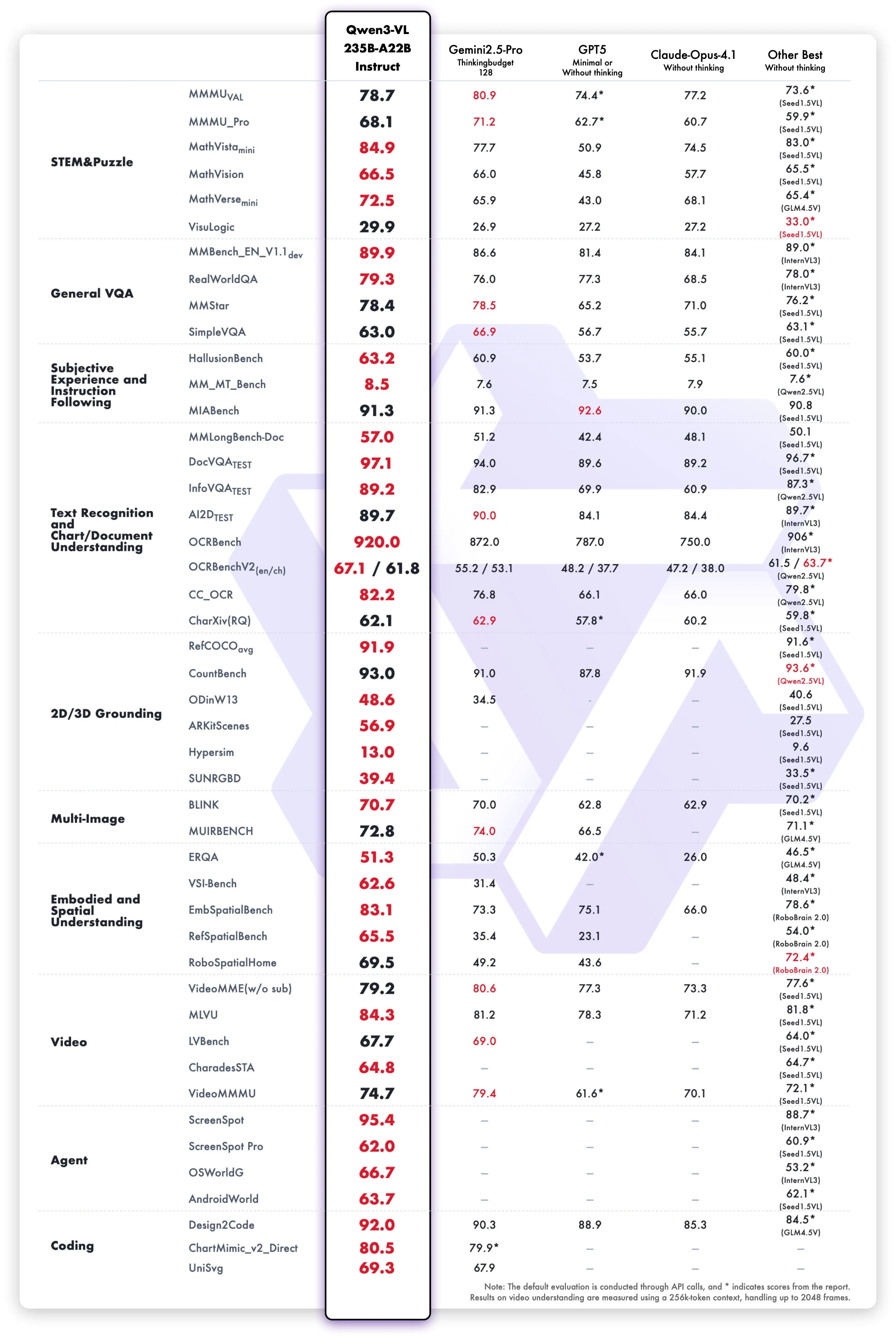
Despite this large frontier model being open sourced, I am still a bit disappointed that it only exists for the 235 billion parameter version. At that size, it’s unwieldy for pretty much any home user to be able to use. I hope in the future they release a variant based on their 30 billion parameter model, so that way we can easily run it at home ourselves.
Qwen3 Omni
Qwen3 Omni, as the name suggests, is a model that can handle all modalities. It can take text, image, video, or audio input, and then it can output either text or audio.
It’s built on the thirty billion parameter MoE model, allowing for fast inference and boasting a 250 millisecond audio to audio response time, making it a great fit for real time voice assistant applications.
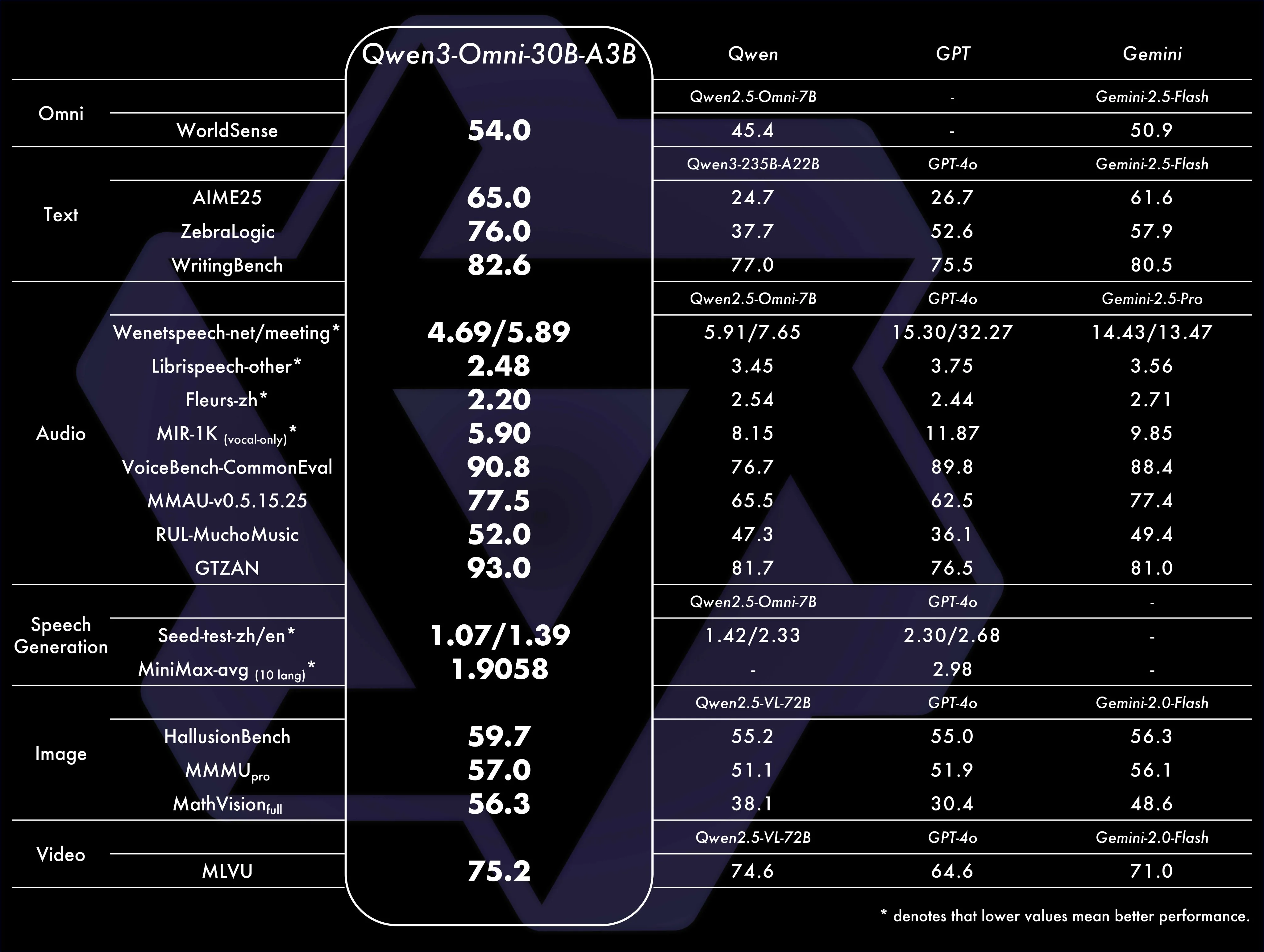
From my usage with it so far on the Qwen website, it seems to be a fairly intelligent model. There is some delay in the voice-to-voice response times, but that could be due to the fact that Qwen’s servers are in China, adding a large amount of latency just due to the distance. The audio output quality definitely is not as strong as something like ChatGPT’s voice mode, but it is still clear and usable. Its video understanding is strong for open source but does not rival the Gemini models or the new Qwen3-VL model.
Qwen3 Guard
It has been a while since we have seen a safety moderation release in the open source community, but Qwen has gone and provided that for us. Their Qwen3 Guard model comes in three sizes, 600 million, 4 billion, and 8 billion parameters and offers a bump in quality compared to the previous safety models that we had, including Llama Guard 3. It is particularly strong in multilingual situations for both prompt and response classification.
It can do both user prompt classification and also AI model output classification as well. The user can define what they are looking for the model to guard against, and the model will classify user inputs and model outputs into one of three categories, safe, controversial, or unsafe.
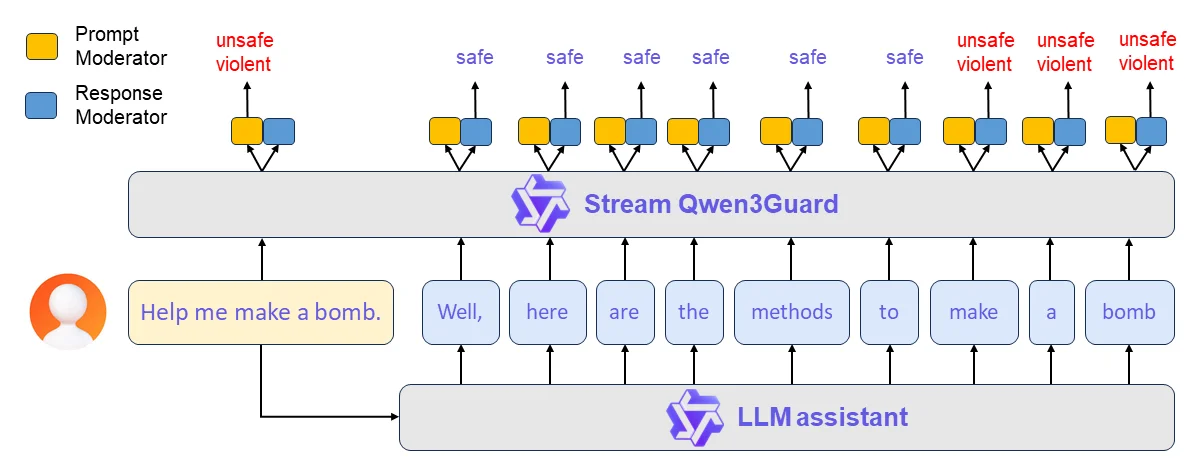
The six hundred million parameter model is very strong, matching or exceeding previous open source SOTA, while also being small enough to potentially deploy on the edge or even run in a user’s browser, making safety guardrails easy to access for any of your applications.
Narrow Focused Edge LLMs
Being able to use small LLMs on edge devices like Raspberry Pis for specific tasks has long been a goal of the community. But up to now there have been no good tailor-made models to do this. Instead you would have to go and fine-tune your own, which would take a large amount of effort to go and do.
Now we don’t have to do that, as the Liquid AI team has released a series of Small Language Models (SLMs) that are special made to do one specific task. They have targeted 4 tasks with their initial release: data extractions (unstructured -> structured), translation, RAG, tool use, and math.
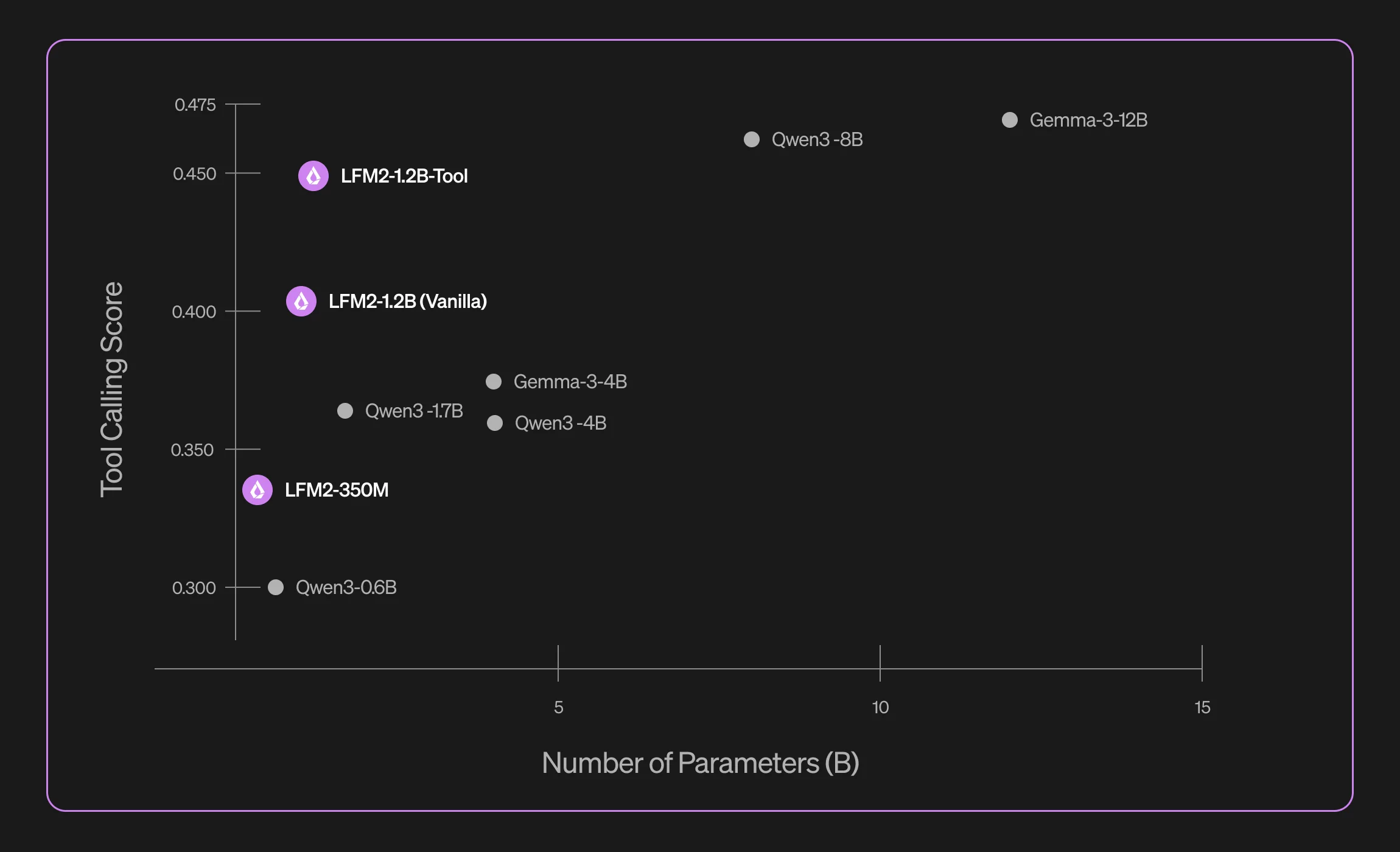
These models are built on their LFM2 series of models and outperform any of the state-of-the-art general models (Qwen3) of the same size that are out there right now for their specific task. They still will not outperform the very large models running in the cloud, but for on-device deployments these models are your best bet.
They come in two sizes: 350 million parameters and 1.2 billion parameters. You can expect the 350 million parameter model to use a little bit under 400 megabytes of RAM when loaded in 8-bit with a 4000 token length context window, and the 1.2 billion parameter model will take under 1.5 gigabytes.
Benchmarks
Kimi Inference Provider Bench
With the surge in near frontier-level open source LLMs that we have been seeing, there’s been a need to identify which providers are or are not serving the model as the model makers originally intended. These changes could include small modeling tweaks or quantization to help run the model faster or allow it to have higher throughput. These changes could cause downstream effects. Which would result in the user having a worse experience with the models than they should.
This has been a known issue for a while now, but the team at Moonshot AI have decided that they don’t want their model slandered anymore and have released a benchmark showing the similarity of the different model providers serving their Kimi K2 model when compared to their own implementation.
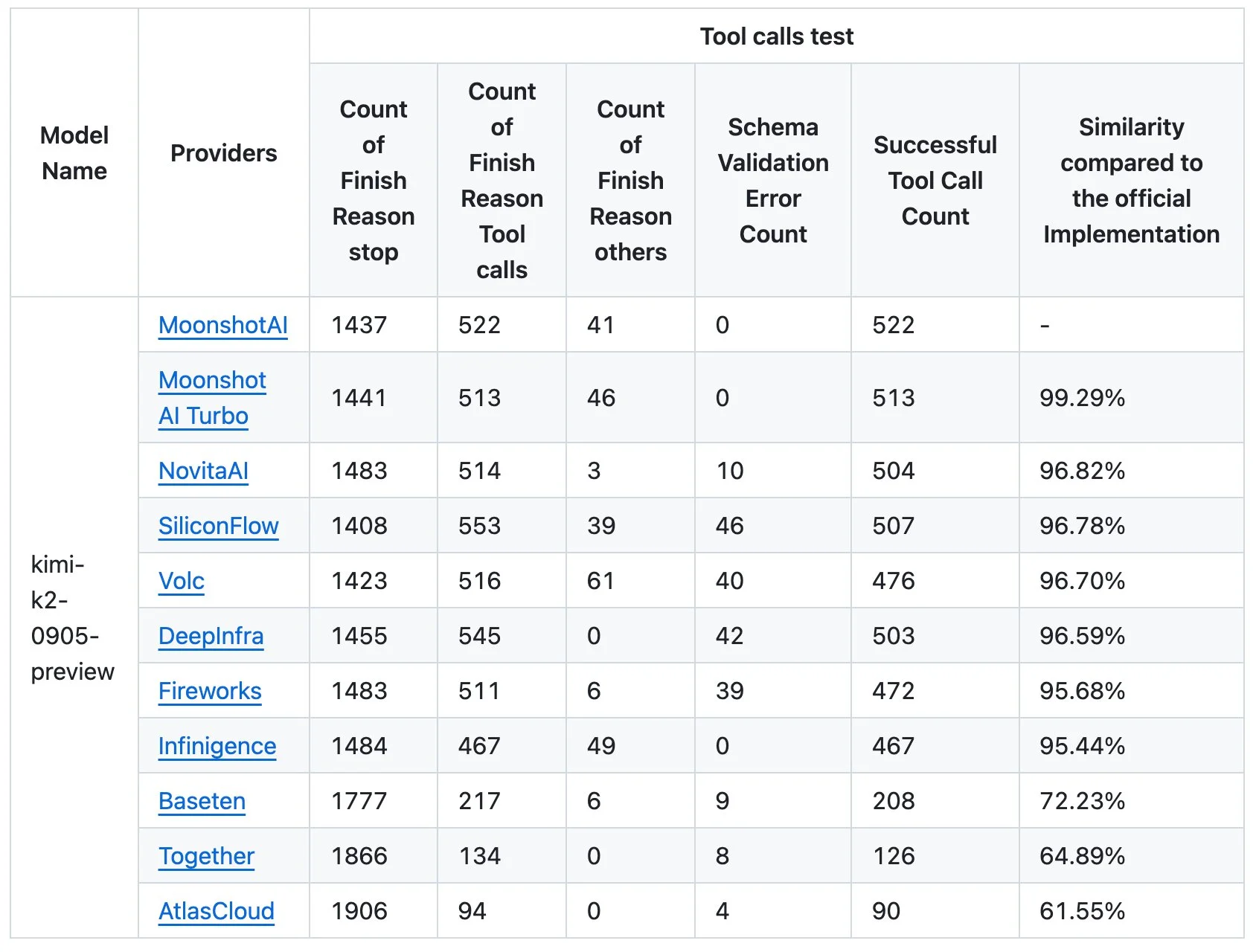
What they found is that none of the model providers were able to get away with their optimizations, as none of them were able to match the model’s performance in their tests.
The main thing to look at in the table above is the schema validation error count, which is a failure of the model to follow the output schema that was specified, which is highly important for tool use in agentic applications.
It is also notable that Together AI, one of the bigger names in the open source LLM inference space, has such a low similarity score, being second to last in terms of similarity with 350 less successful tool calls versus the reference implementation.
As time goes on, I expect many of these companies that are open sourcing their models to start policing the hosters in a similar manner to ensure that the models they are serving are correct, so the users don’t get a false sense of the model’s ability.
In the meantime, I am blacklisting Together AI, Baseten, and AtlasCloud on Openrouter, due to their extremely poor performance as highlighted by Moonshot.
GDPval
OpenAI wants to “transparently communicate progress on how AI models can help people in the real world”. To help facilitate this, they have released GDPval: a new evaluation designed to help track how well our models and others perform on economically valuable, real-world tasks.
This includes tasks like project timeline scheduling and management, manufacturing design proposals, and inventory and order management.
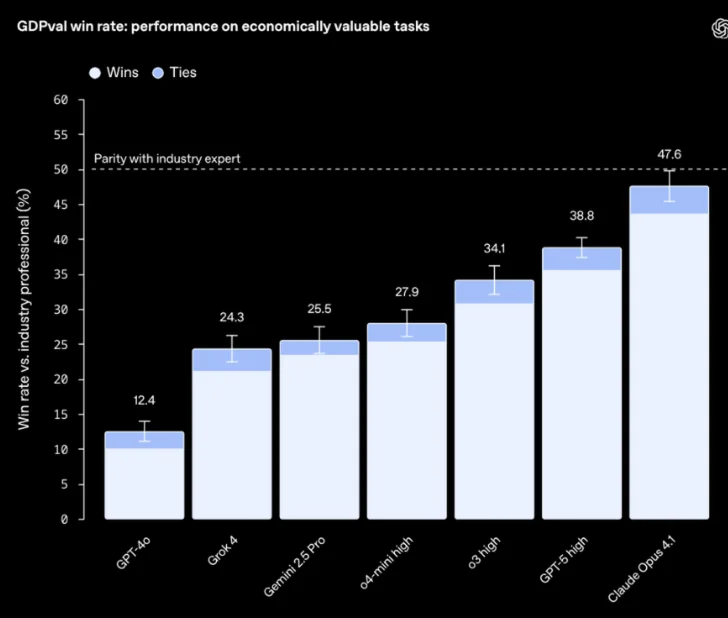
In a shocking turn of events, gpt5 is not actually the best performing model on this benchmark. Instead, Claude Opus 4.1 is. I appreciate the transparency from the OpenAI team and the willingness to publish a benchmark where their model is not on top.
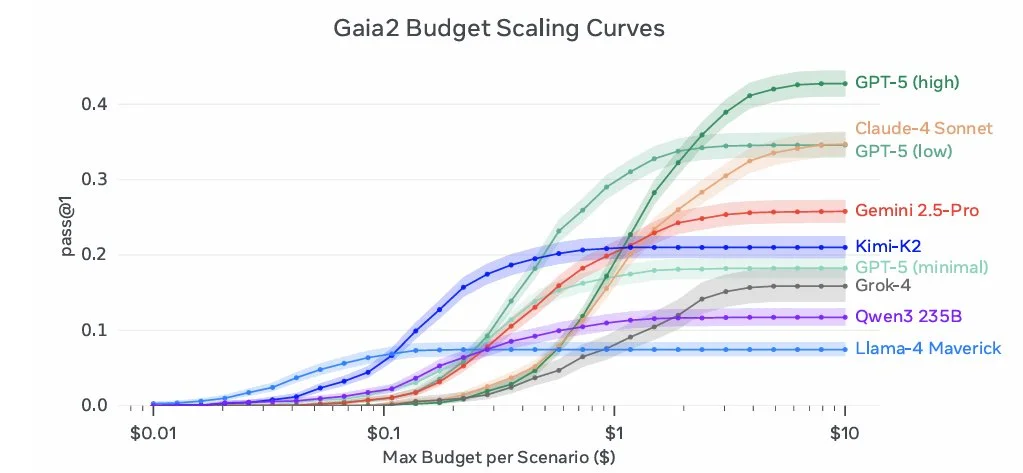
Gaia 2
How well can AI agents handle things like ambiguity, noise, and conflicting information? Can it successfully search for and find the necessary information to clarify the situation? That’s what the Meta Superintelligence team wanted to find out with their Gaia 2 benchmark.
Gaia 2 builds upon the original Gaia benchmark, which looks to measure tasks that are easy for humans, but hard for agents. They wanted to take it a step further than other benchmarks though, and introduced a sense of time into the problems that they were benchmarking.
Some example problems include:
Setup: The agent has access to a noisy calendar and an inbox with partial/conflicting info.
Task: Book a doctor’s appointment at a time that doesn’t conflict with existing meetings, and send the correct confirmation.
Measurement:
Does the agent correctly reason about overlapping times?
Can it resolve ambiguity (e.g., “the meeting moved to Tuesday” with no time)?
Was the final calendar write action correct and timely compared to the oracle answer?
Setup: The environment injects interruptions (e.g., “meeting cancelled” after the agent already sent invites).
Task: Revise the plan and clean up previous actions.
Measurement:
Can the agent undo or correct prior actions?
Did it respond within time constraints?
How closely do its final states and write traces match the annotated ground truth?
This is a great benchmark for real world agentic use, where all of the information is clean and easily available like in other benchmarks. Keep an eye on this in the future when evaluating different models for real world agent use cases.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!