PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Free video generation for all
Veo3 is free to use, a new Wan2.2 video to video model, a Qwen Deep Research model and more!
This week’s AI news is also available in audio form (spoken by me, a human, and not an AI) on Spotify! Be sure to check it out and give it a follow if you are illiterate like me.
We also are releasing a Discord for our community which you can join using this invite link.
News
Veo3 is free to use on Youtube Shorts
Google has figured out the economics, and are now giving users free access to their powerful Veo3 model. Access is being rolled out now across the US, Canada, and a few other countries. You can access it in the Youtube Creator Studio.
”Tap the create button, then the sparkle icon in the top right corner to find our latest gen AI creation tools including Veo 3.” - Youtube Announcement Blog”
This is a great way to access the Veo3 model, as previously it had cost 15 cents per second. The model does text-to-video, image-to-video, and video-to-video generation and generates the audio for the clips as well, making it an all-in-one solution for your video creation needs.
This does come with the expected cost of seeing a lot more AI slop videos on your YouTube Shorts feed. And long term, there are concerns of this model frying people’s brains even more than regular short form content, as it gets better and is able to learn exactly what people want to see and is able to make custom videos catered directly for them.
OpenAI Codex Update
I have been using OpenAI’s Codex CLI as my main programming tool for the last few weeks now. It has been noticeably better for my coding use cases versus Claude Code with Sonnet 4 while already being a part of my ChatGPT subscription.
This week they released an update to their whole suite of Codex products, further increasing their lead in the agentic coding field.
The headliner is the release of a new model, GPT-5-Codex, which is a finetuned version of GPT-5 made specifically for use in the Codex framework. It shows strong performance increases in real world coding benchmarks, can write better documentation and comments, and can dynamically control how much or how little reasoning it does, so easy questions get answered quickly and hard questions can be thought through deeply.
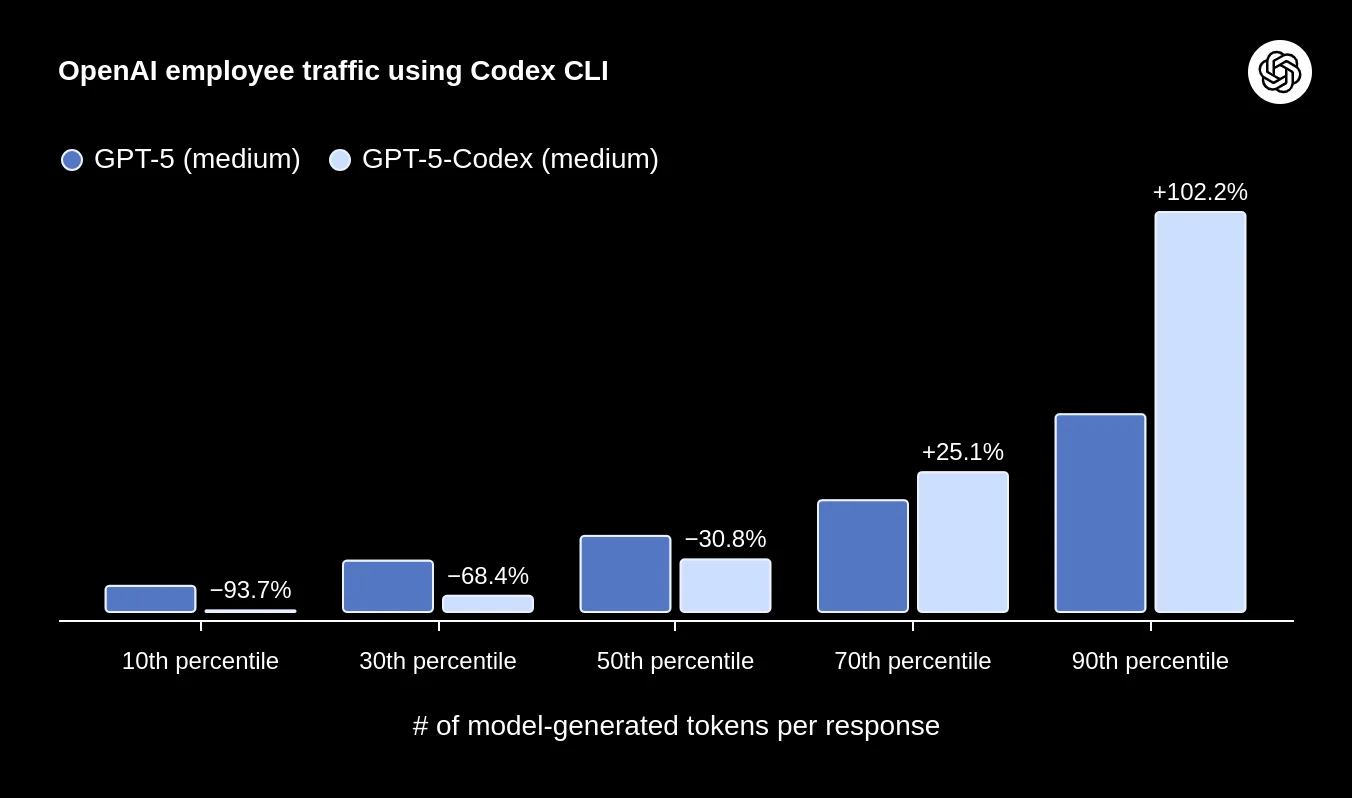
Alongside the new models, they released updates to the different Codex frameworks (CLI, IDE extension, and Cloud), allowing them to all seamlessly interact on the same project. Some additional features include automatic Github pull request code reviews, MCP and web search support, and support for image inputs.
The one caveat for using Codex is that it is not as good at handling very vague prompts compared to Claude Sonnet 4. If you want to get the most out of the model, you will want to be as specific as you can with your instructions.
Releases
Wan 2.2 Animate
The top open source video generation model Wan 2.2, has had a new variant released by the Alibaba Wan team. The model is Wan2.2 Animate, which as the name suggests, is meant for character animation based on an input video.
It has 2 modes:
- Move mode, which animates the character in the reference image with the movements in the input video.
- Mix mode, which replaces the character in the input video with the character in the input image.
The way I think of it, if you want to use the background in the reference image, use move mode, and if you want to use the background from the reference video, use mix mode.
This model is definitely the strongest in the Wan 2.2 lineup, as it is competitive, if not better, than most of the closed source models trying to do the same.
The model comes in two variants similar to the rest of the WAN 2.2 lineup, there is a dense 5 billion parameter model for low resource users and quick iteration, and then the 28 billion parameter mixture of experts model.
You should be able to run the big 28B model if you have a GPU with more than 16 GB of vram. The models work with the lightning loras made for the rest of the Wan 2.2 lineup, allowing for 10x faster generation speeds (otherwise a single video would take over 20 minutes to generate on a 3090).
If you want to see more examples of the model in action, you can check out their blog page.
Qwen (Tongyi) DeepResearch
The Qwen team has decided to take a break this week from any releases, but that did not stop their parent lab, Tongyi, from releasing a model of their own.
The model is a fine-tune of the Qwen 30B MoE model made specifically for deep research applications, called Tongyi DeepResearch.
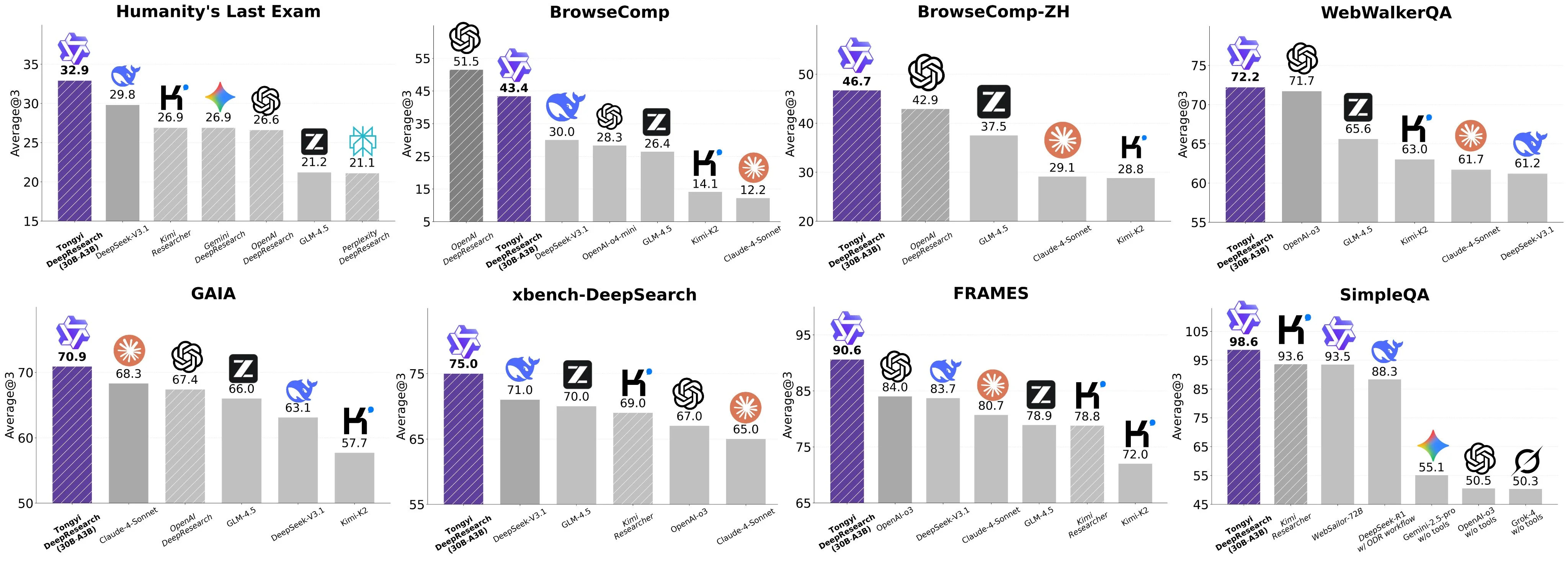
The model benchmarks well, but almost too well, as some users on Twitter have reported that they’ve been unable to reproduce the model’s very high scores across some of the benchmarks.
That being said, for its size, it is still a very strong model, even if it is only half as good as the reported benchmarks claim that it is.
I plan on integrating it into my local AI setup, and will hopefully have more to say about its real world performance in the coming weeks. Also look out for Qwen3-VL coming out next week as well.
A pair of image understanding models
We got not just one but two small image understanding LLM releases this week.
Moondream 3 Preview
Moondream 3-Preview is a 9 billion parameter MoE model with 2 billion active parameters that has state of the art visual understanding and reasoning capabilities.
It is a hybrid reasoning model capable of doing visually grounded reasoning where the model references objects in spatial positions in the image while it’s doing its reasoning.
The model has both point and detect (draw bounding box) functionality built into it by default that you can use.

The team behind Moondream is very detail-oriented. So I suspect very little overfitting on benchmarks and that it actually does have state-of-the-art performance that matches the much larger closed models.
You can try it out for free with no account on their playground.
Isaac 0.1
The second is from the former meta chameleon team which have left informed their own company Perception AI. They have released a model called Isaac 0.1 which is a 2 billion parameter open weights model that performs equally if not better than Gemini 2.5 Flash on spatial intelligence and visual reasoning benchmarks.
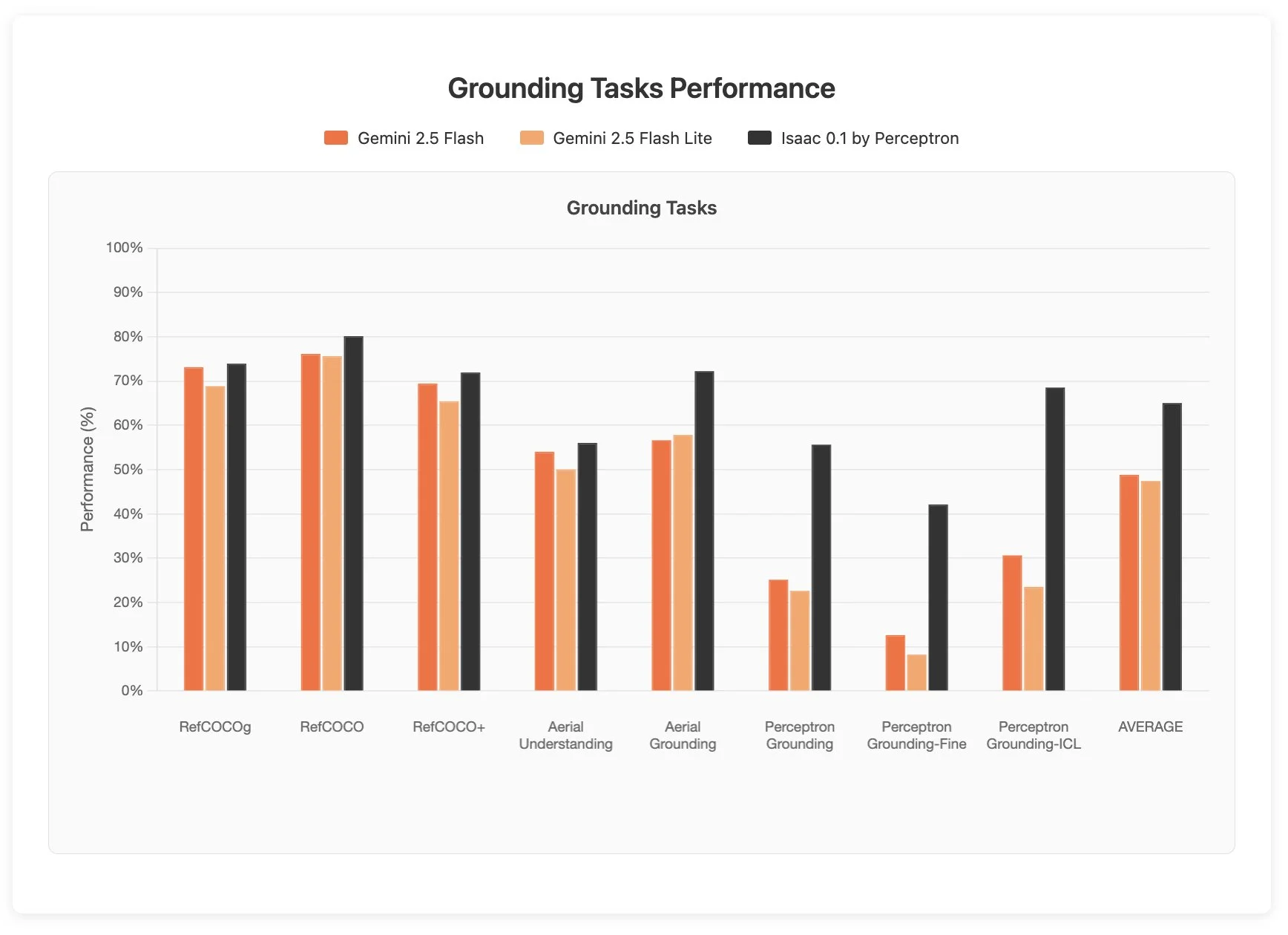
Normally this is not a model that I would cover, except that in testing, it managed to pass some of my internal vision understanding tests that no other multimodal model has been able to do up to this point, including Moondream 3, Gemini 2.5 Pro, and GPT-5.
It is still very much rough around the edges, running into infinite loops and hallucinating many outputs. But there are moments where you can see that it is truly a very powerful model. I look forward to what this team is able to build in the future and eagerly await the release of Isaac 1.0.
This model is also freely available to play around with on the Perception AI website.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!