PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Subquadratic fraud
Anthopic finds an unlikely partner, have we entered the era of 10 million context windows, and how big is GPT 5.5?
tl;dr
- Anthopic finds an unlikely partner
- Have we entered the era of 10 million context windows?
- How big are frontier closed source LLMs?
News
Anthropic partners with SpaceX
As many of you have probably been aware, Anthropic has been struggling to get enough compute to serve their models. This has caused rate limits to decrease, and also for more credits to be used during peak hours (they are billed at 2x more than normal).
All of a sudden, Anthropic has found an unlikely partner to help them out: Elon Musk.
xAI is renting out their 220k GPU datacenter Colossus 1 to Anthropic, allowing them to double their rate limit and remove the peak hours usage reduction for the Claude Code subscription plans, and also increase API rate limits drastically as well.
Anthropic has been heavily GPU constrained, as they only had planned for 10x growth this year, but are already on pace for 80x. Getting access to a 5+ billion dollar datacenter helps them catch back up to meet this demand.
It is also interesting for xAI, as they are giving up a large chunk of their compute, to a company that historically Elon Musk has not been a fan of. Many people have been calling this a Kingmaker scenario, as Elon’s dislike of Anthropic is less than his hatred of Sam Altman and OpenAI, who he has an open lawsuit against.
For me this changes little, as I have canceled my Anthropic subscription in favor of an OpenAI one instead, since GPT 5.5 is a far better model for coding than Opus (outside of the minimal amount of frontend work that I do).
Releases
SubQ
Many people have been talking about the new startup Subquadratic and their model SubQ. The model claims a lot in terms of architectural advancements: 12 million context window, 52x faster than FlashAttention, and 5% the cost of Opus.

To say I am extremely skeptical of this model would be an understatement. To understand why, let’s look at the benchmarks they released.
SWE Bench Verified has been denounced by its maker OpenAI, as many of the tests are incorrect, and also that it is probably one of the most overfit datasets out there, with any progress that we see from models coming from the fact that they have been trained on the answers, as that is the only way for models to pass the incorrect tests.
For the RULER benchmark, it was good, but has become saturated and outdated, and is also a public benchmark allowing for easy overfitting.
MRCR v2 is another public benchmark, and has recently been called out by Anthropic for not being correlated with long context capabilities, and are focusing on other benchmarks like GraphWalks instead as they are a better indicator of performance. This is why you see a large drop in scores for Opus 4.6 and Opus 4.7 for the scores.
So the benchmarks they released are meaningless, what about the 12 million context length claim? This is also bogus. I have talked before about long context windows, and the main issue is that we just don’t have any meaningful long context data to train the models on.
From a hardware perspective, architectures like DeepSeek V4 could easily handle 10+ million context windows already, the issue is that you would see massive performance degradation since the model hasn’t actually seen any 1 million+ data before. It hasn’t been until the last 3-6 months where frontier labs like Anthropic and OpenAI have been able to get consistent results up to 256k, let alone the 1 million token max context window that they claim to have (I always use the 256k context window versions when I can to avoid this).
We have had “1 million” context windows since 2023, the reason you never heard of them or used them before is because they aren’t actually useful above 100k tokens usually. The issue with long context models has not been architecture, it has been data, which I can fairly confidently say that these guys have not solved.
In their release they seem to be claiming to have trained the whole thing from scratch, which cannot be the case. Their score (which is higher than DeepSeek V4’s btw) means that they have been able to train a frontier model (better than all the Chinese labs) for less than $30 million (the total amount of funding that Subquadratic has raised so far) from scratch. If they were really able to do that, that would be the headline instead of their sparse attention architecture.
In reality this is most likely a Qwen (or Kimi or DeepSeek) model. They replaced the attention architecture with their custom variant, and then trained it on the benchmarks that they wanted it to do well on.
If they really made a sparse attention model, then the fact that its only 12x the context window of a normal transformer is kinda sad. A sparse attention arch should be able to handle 100M context window, also it would be fairly easy to serve, and not need a waitlist like they have right now (from what I can tell nobody has gotten off the waitlist and actually used the model yet).
Overall, this model is a bunch of hype marketing, and they have not actually demonstrated any unique capabilities to deserve the fanfare they have gotten.
Research
How big are closed source LLMs?
A question many people have is how big are the closed source models from OpenAI, Anthropic, and Google? A researcher wanted to figure this out so they devised a way of measuring it.
We know from observing open source models on factual benchmarks like AA Omniscience that a model’s world knowledge directly scales with the number of parameters it has.
Because of this, we can make a linear regression based on open source model’s sizes and their scores on factual question benchmarks and then use the scores of the closed scores models to estimate their size.
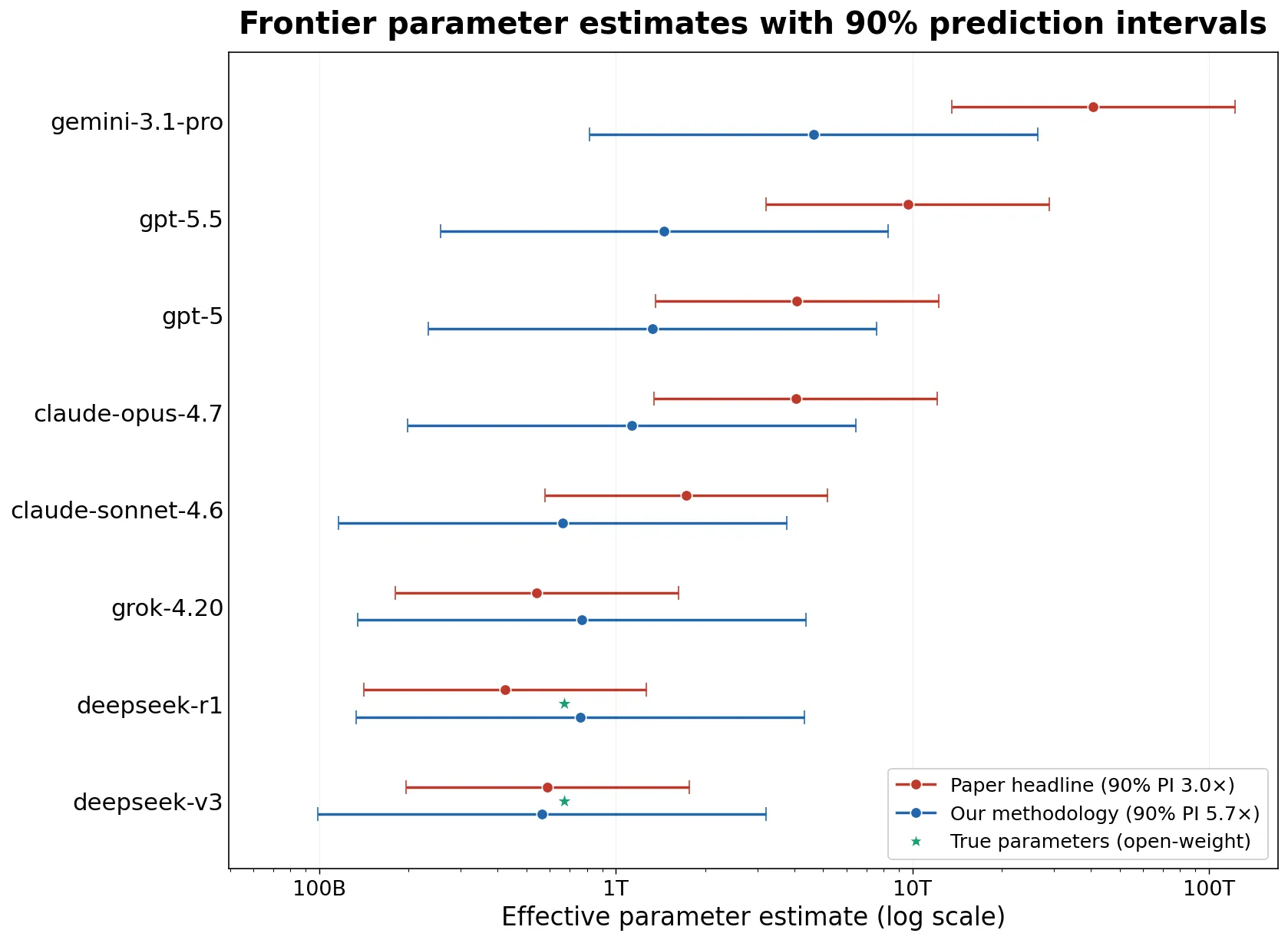
From the results we find that Sonnet is around 650 billion parameters, Opus 1 trillion, GPT 5.5 1.5 trillion, and Gemini 3.1 Pro 4.6 trillion. These predictions have large error bars, but give us a good ballpark, and tell us that frontier open source models are not falling behind from the top labs in terms of size.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!