PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Anthropic Mythos
How mythical in Anthropic Mythos? Is Meta back in the LLM game? GLM 5.1 takes the spot as the top Chinese model
tl;dr
- How mythical in Anthropic Mythos?
- Is Meta back in the LLM game?
- GLM 5.1 take the spot as the top Chinese model
Releases
Anthropic Mythos
A few weeks ago there were leaks about a model from Anthropic that is larger than Opus that crushes benchmarks. This week those rumors were made real, as Anthropic announced the existence of Claude Mythos.
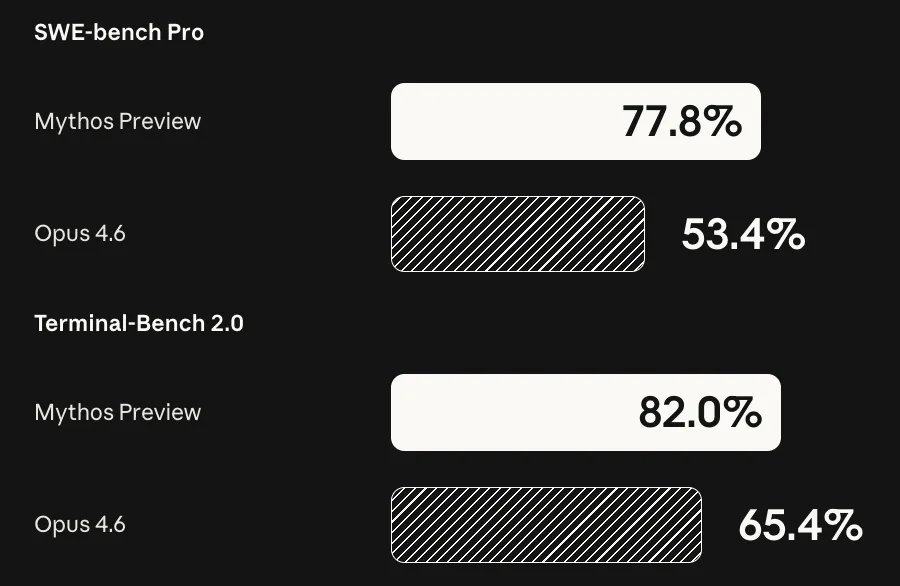
The model is not actually being released, as Anthropic has deemed its hacking capabilities to be too strong for the general public to potentially use.
It was able to find hundreds of bugs across many major open source projects that have been audited, tested, and actively used for years (e.g. Linux, FFMPEG, OpenBSD). If the model were to be used by nefarious hackers, Anthropic feels that it would tilt the playing field too much in favor of attackers.
Even if the model is not being actively used in a negative way, it may go and take negative actions itself to be able to accomplish its task. Anthropic is calling this their model aligned model, yet in their technical report, they talk about how the model will act reckless and hide information from the user.
The model will try and hide the fact that it saw the answer to a benchmark question (so that it looked like it solved it by itself instead), it can break out of its own sandbox and email people, steal credentials to be able to finish tasks, and trying to hide its reasoning to fool evaluators.
Their report is much more in depth than previous models, and they seem to be taking the safety side of things much more seriously now. They highlight in their report the lack of frontier benchmarks that are not saturated by the model, making it hard to determine its capabilities while its training. Most of the issues that they highlighted in the report did not come from the direct safety testing but instead an internal rollout.
There has been some debate online about how strong its hacking capabilities are, and if Anthropic is just trying to spook people or if they are actually real. Having read a few takes online and talking with a few friends in the field (I am not a cybersecurity person myself) it seems that it is not a fluke and these are real vulnerabilities that it is finding.
I don’t think this is a model that will ever be released (at least not for a while) given its immense capabilities. Even if they did, it is reportedly 5x more expensive than Opus, which is already one of the most expensive models to use, which would make it prohibitively expensive for the average person to use.
We are now entering into the middle game for AI, where the top models are deemed too powerful to be released, concentrating power to those that have access to them. This will be interesting to see how it plays out in the future.
Meta Muse Spark
Meta has returned after a year since the ill-fated Llama 4 release, with their Muse Spark multimodal LLM.
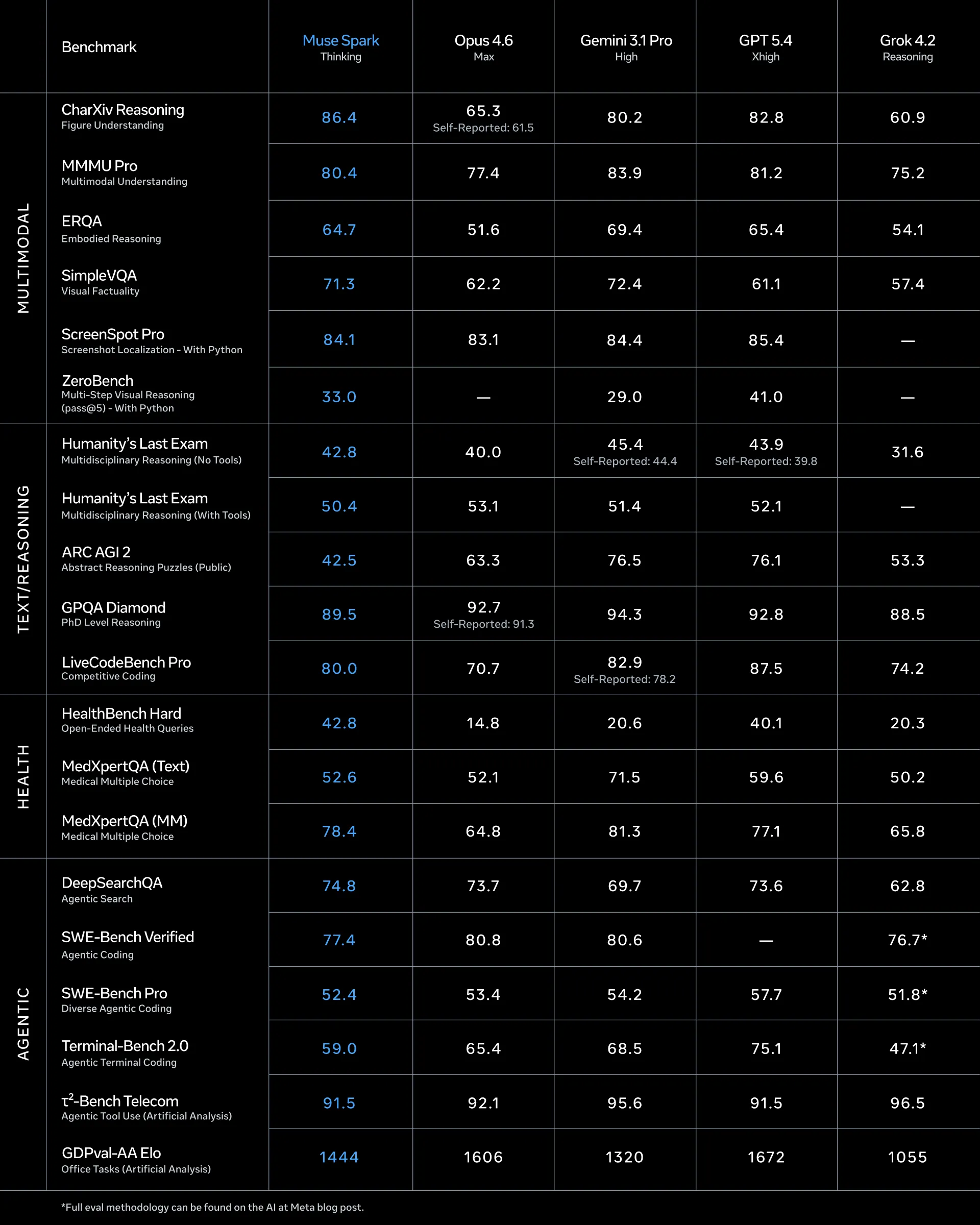
The preliminary results that I have seen for the model have been decent. It is definitely not a benchmaxxed model, but does still struggle in a few areas when compared to Anthropic and OpenAI.
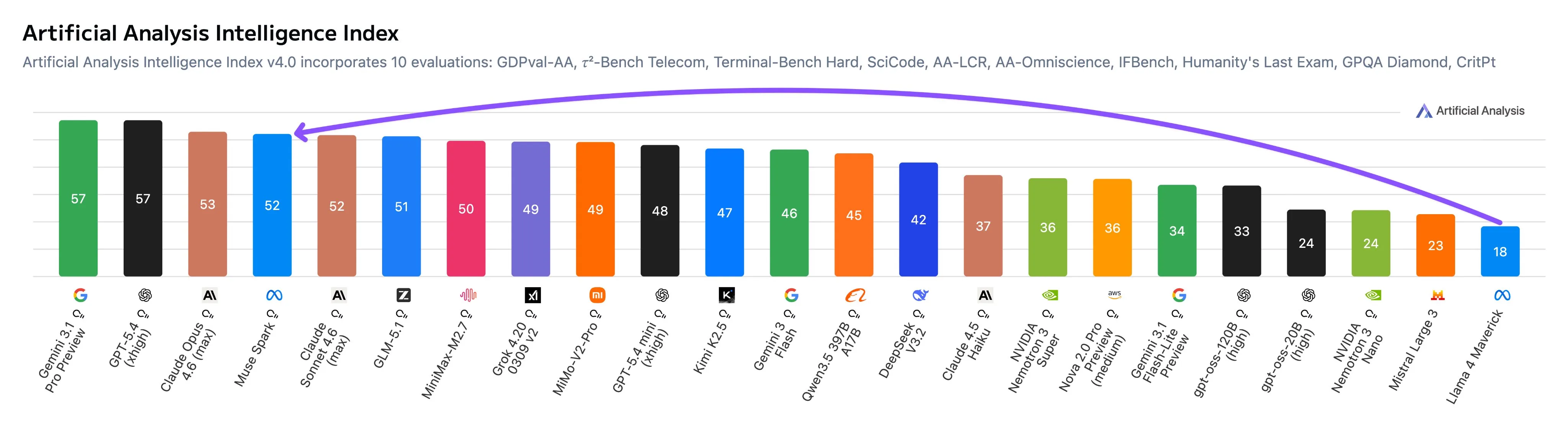
Looking at the breakdown of the Artificial Analysis results, the model does well for general use cases, but struggles in agentic tasks and even more so in coding when compared to other frontier models.
Right now the model has only been made available to a few 3rd parties (like Artificial Analysis) to benchmark, and also on the Meta AI app for consumers. Once API support gets added we will see what the 3rd party benchmarks say.
The model will be closed source it appears, so gone are the days of Meta being a leader in the open source space. This is good to see more competition from a big lab, as Gemini and Grok have been falling behind Anthropic and OpenAI quite a bit lately. The Meta Super Intelligence team was able to make this model in only 9 months, so I look forward to see what they end up making once they have more time to cook.
GLM 5.1
Z.ai has officially released an update to their GLM 5 model. They soft launched it a few weeks ago on their coding plan, but have officially open sourced it and released benchmarks for it this week.
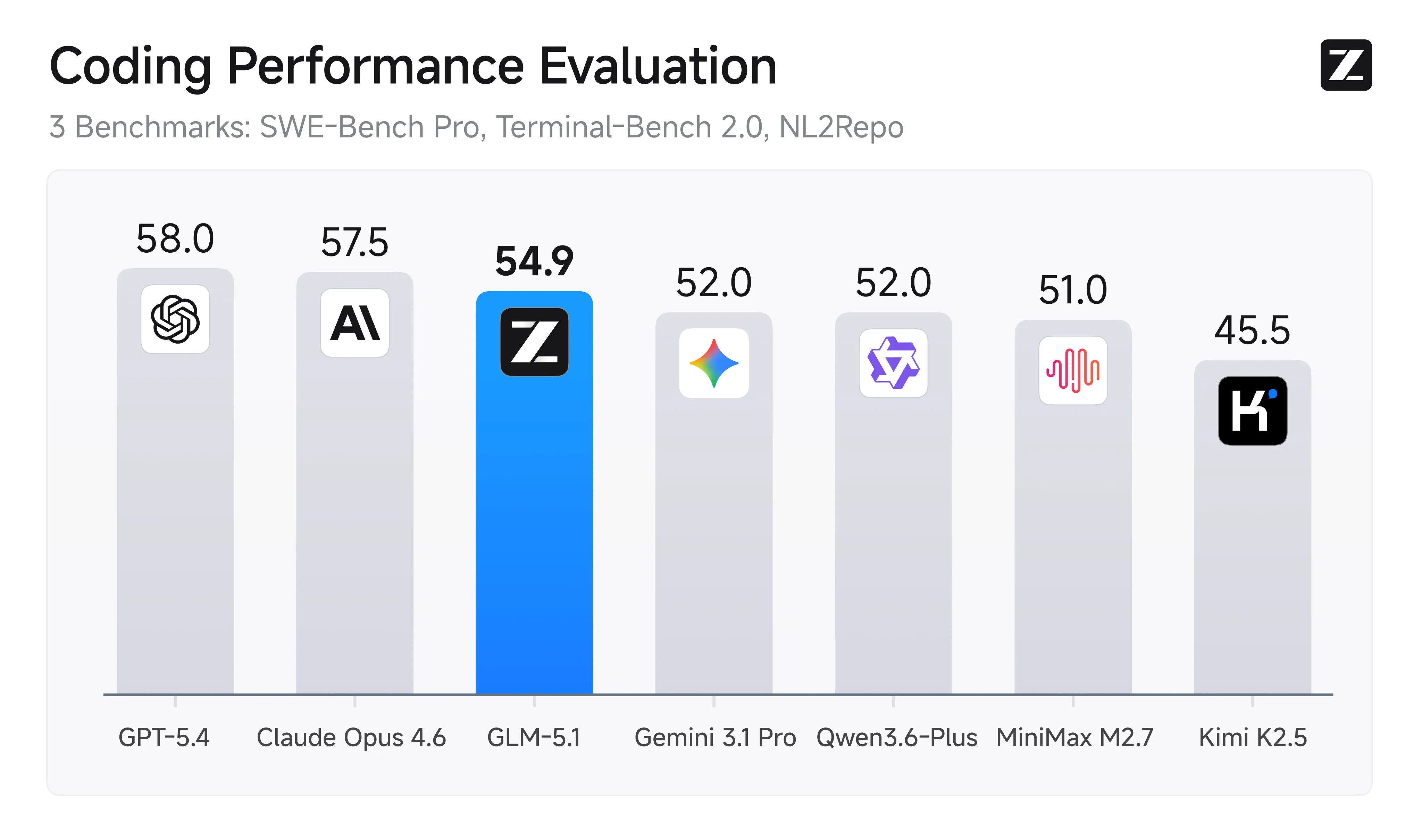
The model is a straight upgrade from the previous version, being better at prompt understanding, large scale agentic coding sessions, and frontend design. For frontend specifically is tied for the top of the Design Arena with Claude.
In my personal coding use, I use GPT for backend, DB, and research work, while I use Claude for planning and frontend. Now with GLM 5.1, I am moving my frontend tasks to it, and it still continues to be my go to for small, easy tasks, given its low price and high rate limits with their coding plan.
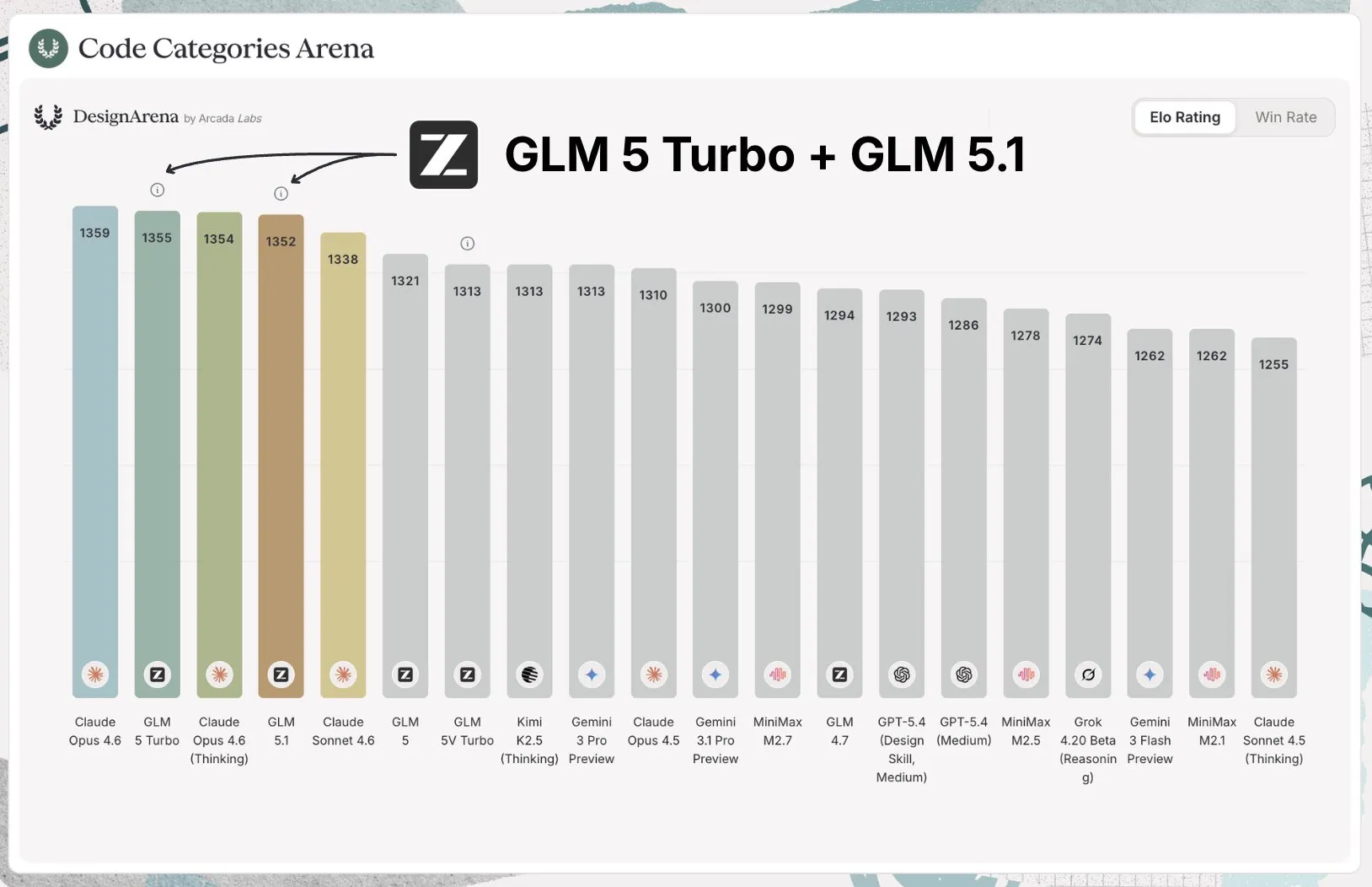
The model (like most Chinese models) is overfit a bit on more general benchmarks, but for coding it is definitely as good as the benchmarks entail. Because of this, I am moving it up to be the first non OpenAI or Anthropic model in the second tier for my coding model tier list.
Frontier models
- GPT 5.4
- GPT 5.3 Codex
- Opus 4.6
Second tier
- Sonnet 4.6
- GPT 5.2
- Opus 4.5
- GLM 5.1
Third tier
- Minimax M2.7
- GLM 5
- Kimi K2.5
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Stay Updated
Subscribe to get the latest AI news in your inbox every week!