PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Gemma 4
Google releases Gemma 4, Arcee AI releases the best American open source LLM, and LiquidAI comes out with a tiny LLM
tl;dr
- Google releases Gemma 4 open source models
- Arcee AI releases the top American open source model
- LiquidAI releases a tiny LLM
Releases
Gemma 4
Google has re-entered the open source model race with their Gemma 4 series of models.
The Gemma 4 series comes in 4 sizes, 5 billion, 8 billion, 26 billion (MoE, 4 billion active params), and 31 billion (dense).
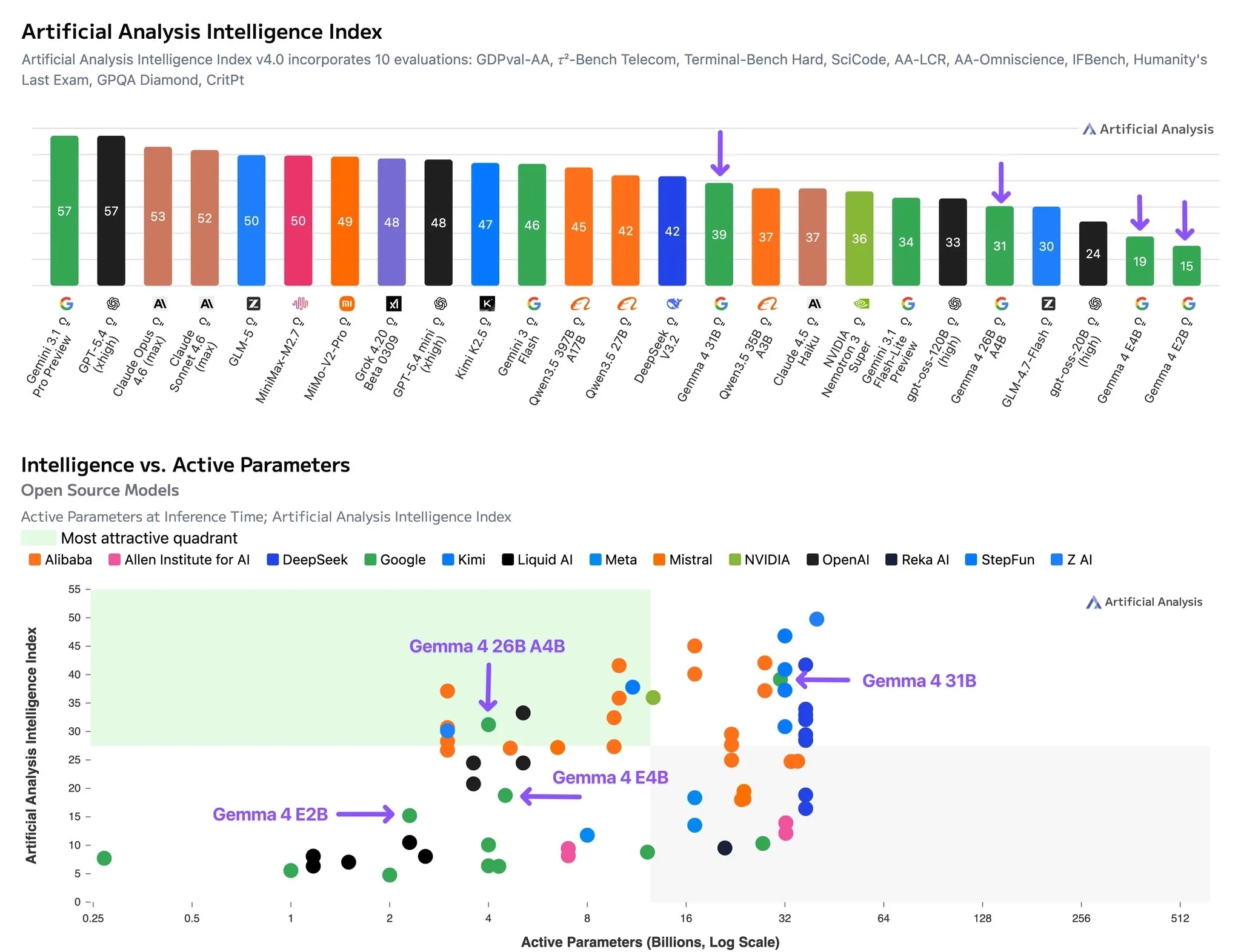
The smaller 5B and 8B models follow the Gemma 3n architecture, which is to say, completely different than any other LLM out there right now, making them much more efficient than their parameter count would suggest (about 2x faster and more efficient).
The models are meant to compete with their Qwen 3.5 counterparts, which they are mostly able to do. The smaller models falls bit behind, but will be better for low resource edge deployments due to their very efficient architecture.
The larger models are a closer match, being ahead on coding benchmarks but behind on more general agentic tasks. They also are more efficient reasoners than Qwen3.5, with token usage in reasoning mode being comparable to the Qwen3.5 models in non-reasoning mode (and 3-5x less than Qwen3.5 with reasoning on). This once again makes it good for local or fast inference due to the limited amount of thinking that the models do, which the Qwen3.5 models tend to overthink very heavily.
Overall the Gemma 4 models are solid, if you are looking for low cost models or models that you can run at home, I would definitely check them out and compare them to the Qwen3.5 models for your use cases.
Quick Hits
Trinity Large Thinking
Arcee AI released their Trinity series of open source American models a few months ago, but they had a rather hastily done post training.
Now they have updated the post training for the Trinity large model (MoE, 398B total, 13B active params), and the results are looking good.
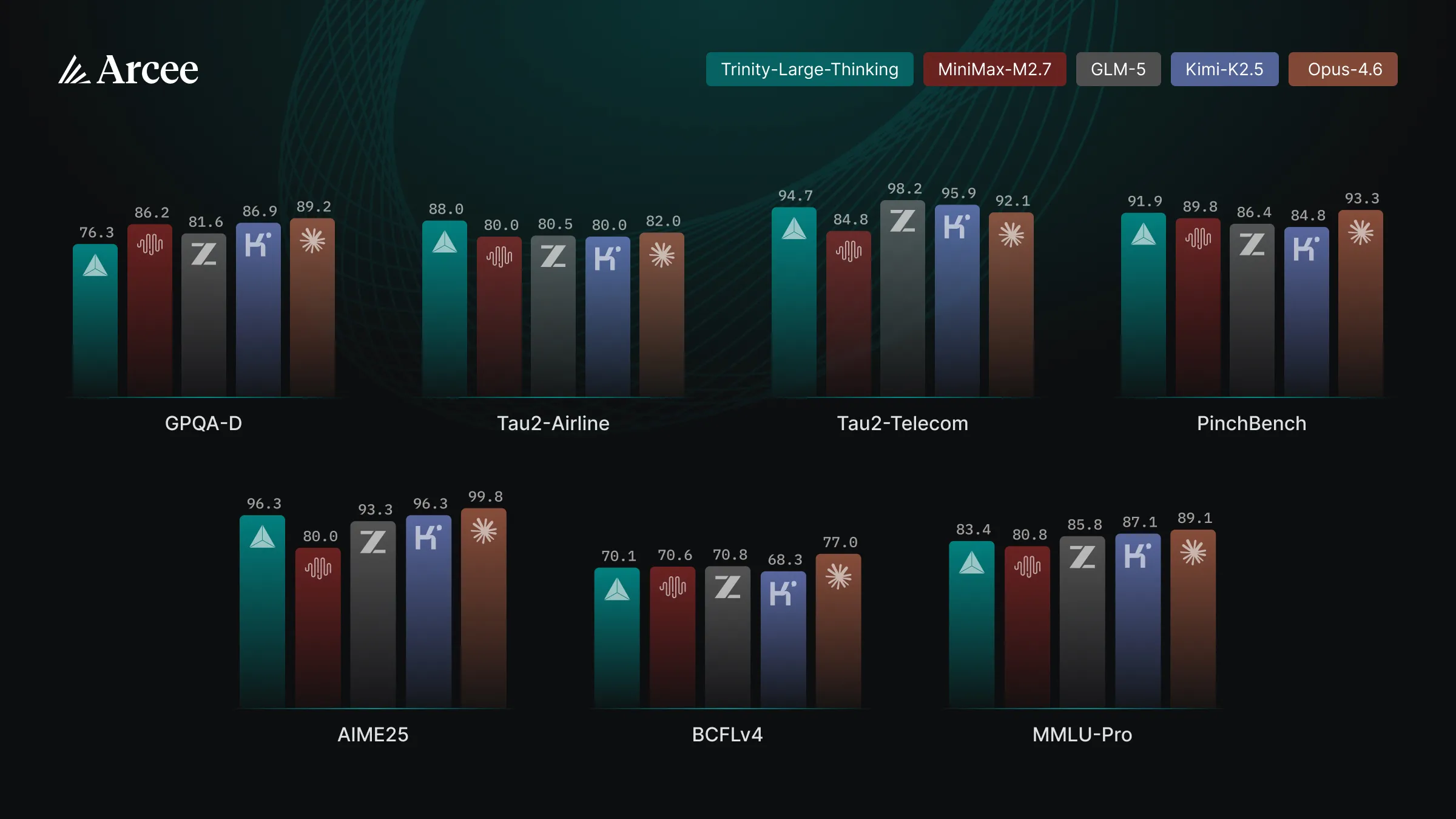
They are competitive with the top open models from China on benchmarks. They were also the top American model on OpenRouter for the past few months, and that was before this much better post training that they have given the model.
I have been a fan of Arcee AI for a while now. Watching them go from finetuning small models to training their own frontier models in ~1 year has been super cool to see, and I would recommend checking out this model if you want to support American open source AI.
LFM2.5 350M
LiquidAI continues their quest to make the smallest, fastest models that are still somewhat usable for agentic tasks, this time coming out with a 350M perameter model that has been trained on 28 trillion tokens, making it the most overtrained model that we know of (based on Chinchilla scaling laws)
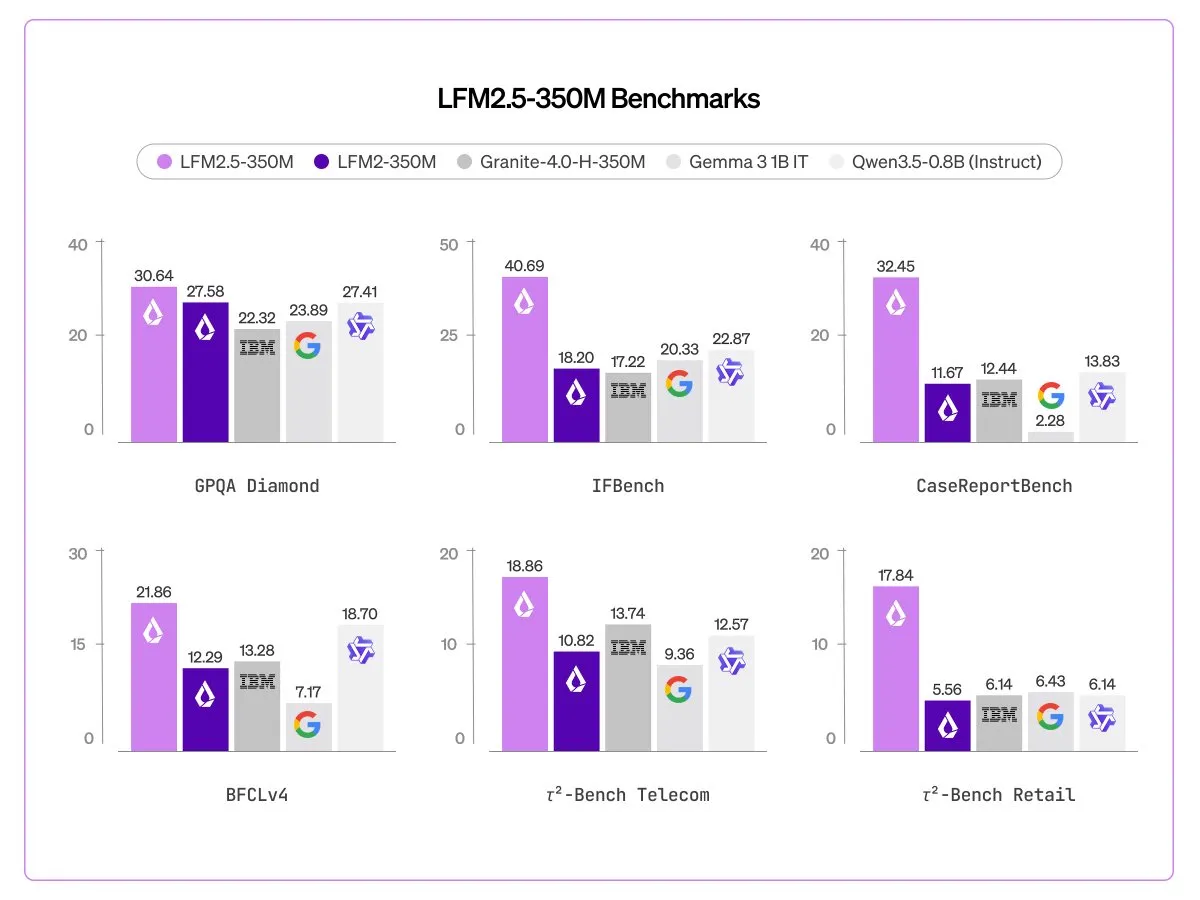
When quantized this model will take up only about 300MB of memory, allowing it to be deployed almost anywhere. Historically this model size has been considered only for toy models that researchers use, so the fact that Liquid have been able to make something that is somewhat useful is extremely impressive.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Stay Updated
Subscribe to get the latest AI news in your inbox every week!