PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
GPT 5.4
Is GPT 5.4 the best model to use? Are the Qwen 3.5 models worth running at home?
tl;dr
- Is GPT 5.4 the best model to use?
- Are the Qwen 3.5 small models worth running at home?
- What is GPT 5.3 Instant?
Releases
GPT 5.4
OpenAI released an update to their GPT 5 series of models this week. GPT 5.4 is their latest reasoning model, skipping GPT 5.3 as its increased capabilities warrant a more than 0.1 version bump according to OpenAI.
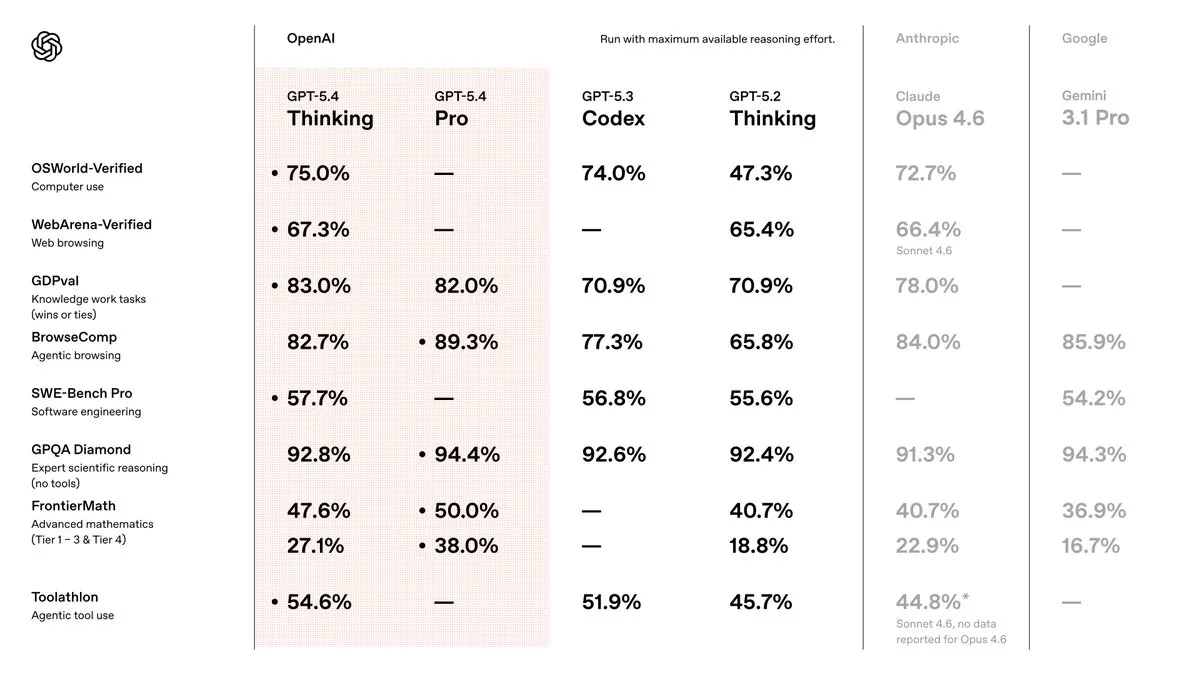
GPT 5.3 Codex was already tied with Opus 4.6 for coding use cases, but fell behind for more general day to day use cases. GPT 5.4 looks to correct these issues to be the best model to use, and outside of a couple use cases, they seem to have succeeded.
In terms of raw intelligence, and ability to get things done, GPT 5.4 is the best model out there right now. Its strong in reasoning, web browsing, agent use cases, and coding. It also has the lowest hallucination rate of any model right now as well.
The few places we see it falter are the same places where GPT has been weak and Claude has been strong: personality, writing style, and design. We can see this in benchmarks like Design Arena, where GPT 5.4 places 18th, behind Claude, Gemini, and even some of the Chinese LLMs as well.
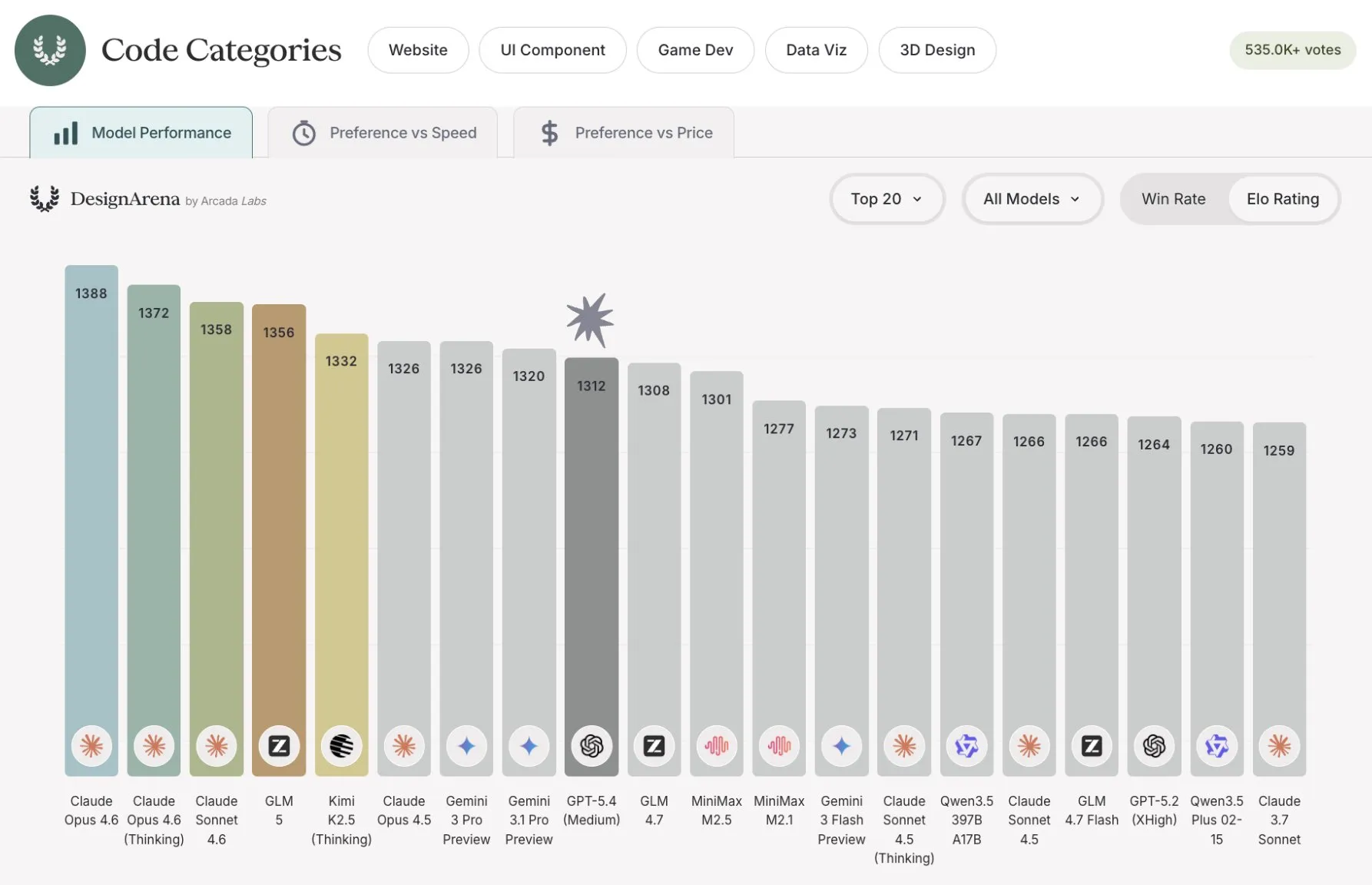
It also falters to its coding focused predecessor, GPT 5.3 Codex, as well. It has better code writing style and intent understanding (although still not as good as Claude for vibe coding), but it does not seem to have the same allergy to bugs that 5.3 had.
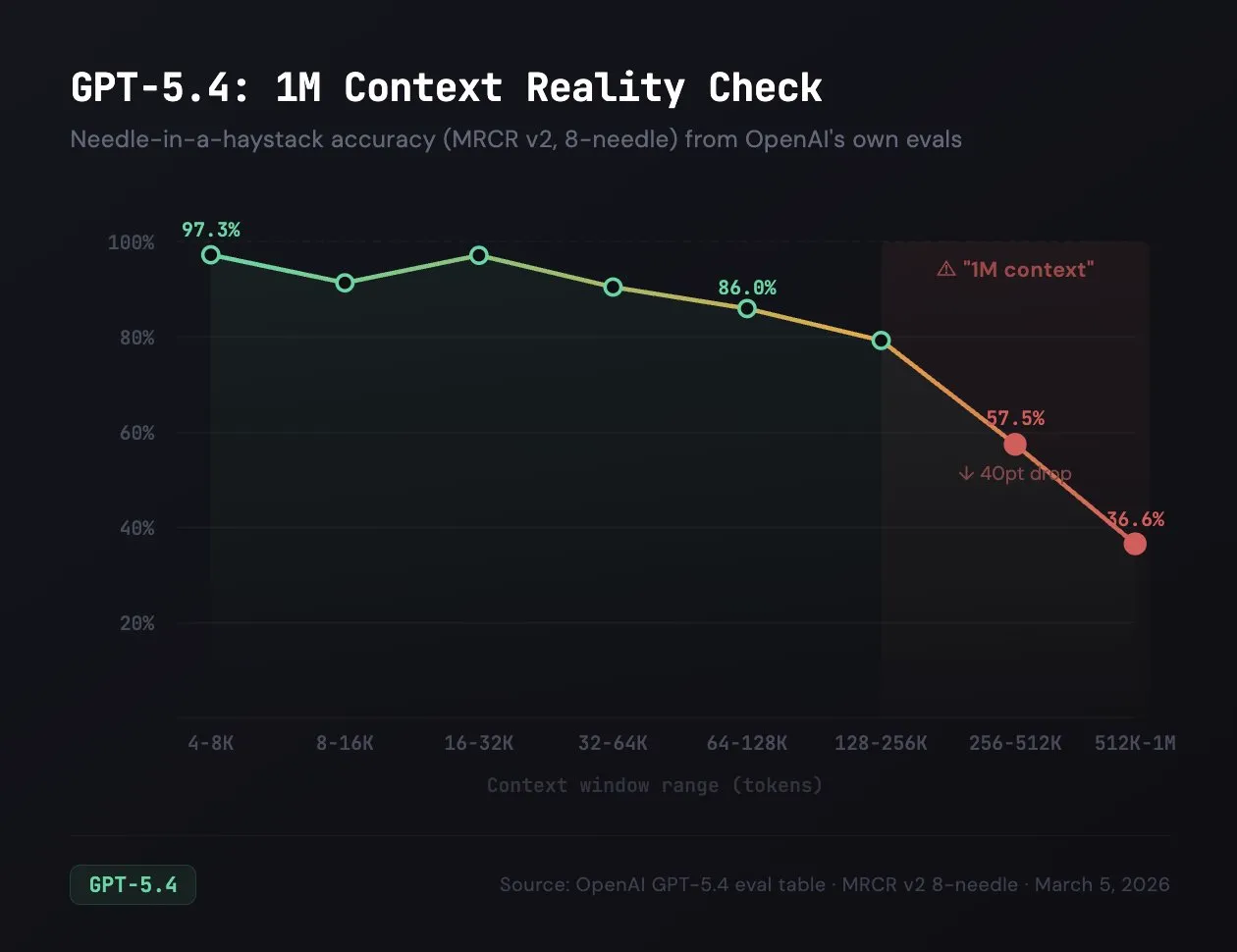
OpenAI are also releasing an experimental 1 million context length version of the model as well, roughly quadrupling the number of tokens you can feed into the model. Just because they have this feature though does not mean it is good, as even OpenAI’s benchmarks show that there is massive quality dropoff once you pass the 256k threshold. Because of this I would recommend staying away from the one million context version, especially since tokens over 256k are charged double.
Speaking of pricing, that is another thing that has changed. Due to “increased model capabilities”, OpenAI has decided to raise the prices for the model similar to what they did for GPT 5.2.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|---|---|---|
| GPT 5.4 | $2.50 | $15 | 50 |
| GPT 5.2 | $1.75 | $14 | 46 |
| GPT 5 | $1.25 | $10 | 46 |
| Claude Sonnet 4.6 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| Gemini 3.1 Pro | $2 | $12 | 80 |
| Gemini 3 Flash | $0.50 | $3 | 80 |
| GLM 5 | $1 | $3.20 | 21 |
| MiniMax M2.5 | $0.30 | $1.20 | 27 |
This means that since the original GPT 5 release, input token pricing has doubled and output pricing has gone up 50%. They are still much cheaper than Opus, but are now priced similarly to Sonnet, opening the door a bit for Anthropic to compete.
Overall GPT 5.4 is a very strong model, and I highly recommend checking it out for regular day to day tasks, agentic uses, and for coding.
Qwen 3.5 Small
Qwen released the models for its final size in its new Qwen 3.5 lineup, being the Qwen 3.5 small models. We are getting 4 different models, with sizes 0.8B, 2B, 4B, and 9 billion parameters, all of which are regular non-mixture-of-experts models.
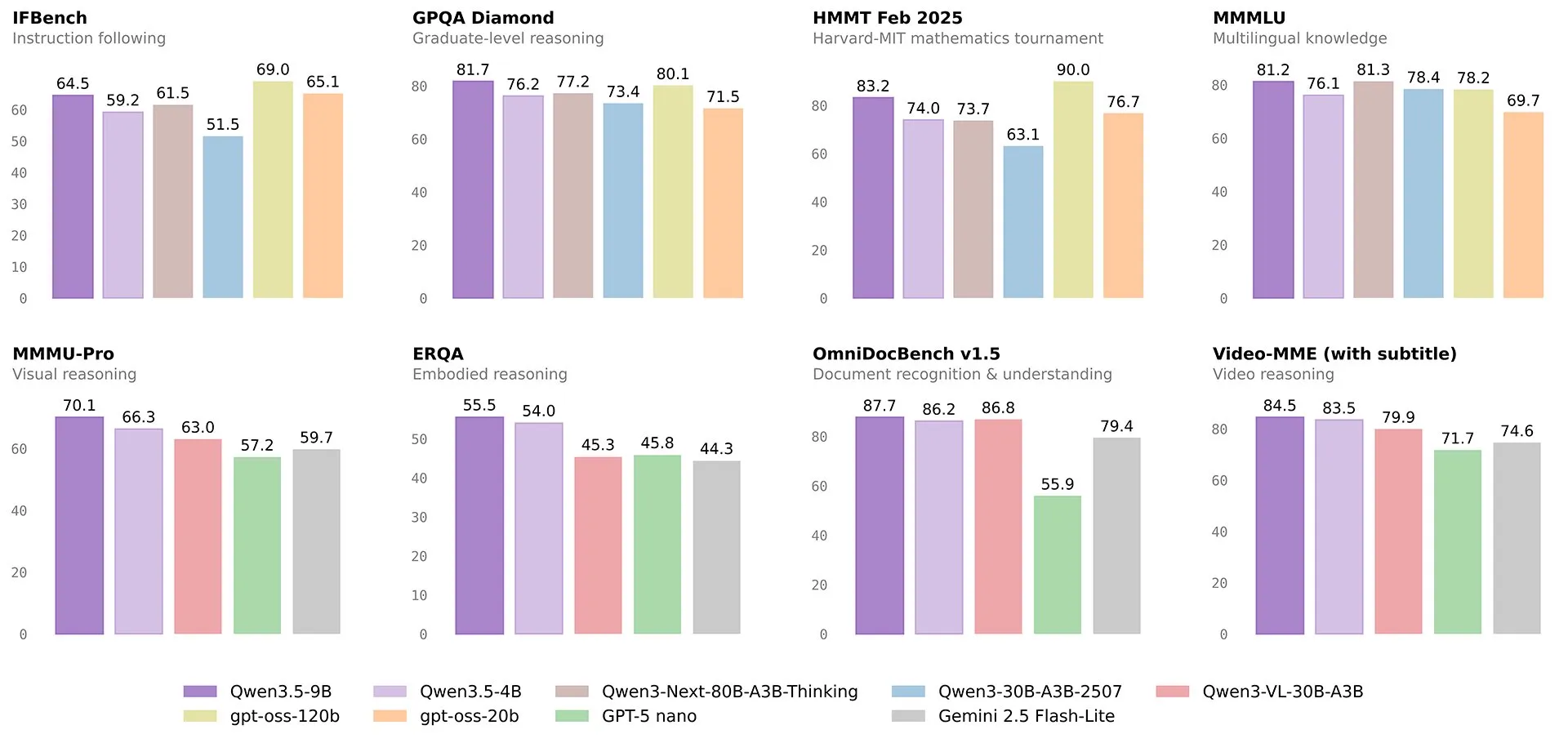
Like all of the other models in the Qwen 3.5 lineup, they are hybrid reasoning models (you can turn reasoning on and off) and also naively support multimodal inputs.
They have been drawing comparisons to GPT 4o (a trillion+ param model that was state of the art 2 years ago), specifically about how they are straight up better than it across most intelligence benchmarks, while also being far stronger agentic models as well.
The somewhat awkward thing for them however, is that they are not actually the best small model out there right now. That title is still given to Nanbeige, which on benchmarks that have been released in the previous 2 weeks (they can’t overfit on benchmarks that were not released yet) it handily beats the new Qwen 4B and 9B models, all while its only 3B params itself.
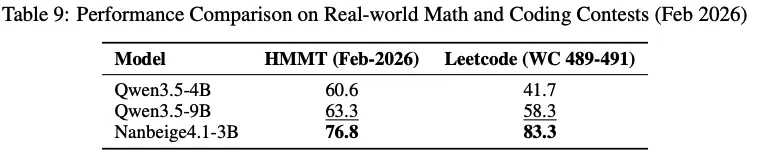
That is not to say that the Qwen models are useless. NanBeige tends to think for a long time before answering even simple queries (with no way of turning reasoning off) and also does not have multimodal support.
So if you enjoy running models at home (or on your phone) I would still check out these new small Qwen 3.5 models.
Quick Hits
GPT 5.3 Instant
In a perplexing turn of events, OpenAI released both GPT 5.4 and 5.3 this week.
This is because it is their instant model, which is primarily seen if you are on the ChatGPT free plan. This is the non reasoning model for the GPT 5 family (previously called minimal reasoning), and has historically been far worse than its contemplative brothers.
With this release, I think OpenAI is trying to show that this model is completely separate from their GPT 5.4 model, and not just a lower reasoning level, but rather an entirely different (smaller) model.
The model is nothing to write home about, whenever you see ChatGPT acting stupid, it is usually the instant model. This release seems to improve the personality and writing style of the model a bit, and they also claim that they have lowered the hallucination rate of the model (with no benchmarks to back this up).
For the benchmarks they do release, there is little to no change from previous versions of the model.
Because of this, I implore you to use GPT 5.4 whenever you can and to avoid the instant model for all but your simplest queries.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!