PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
GLM 5 and MiniMax 2.5
Can GLM and MiniMax keep up with Opus? A chinese HR company releases the best small LLM, and OpenAI releases a 1,000 tokens per second model
tl;dr
- How do GLM 5 and MiniMax 2.5 compare to Opus?
- Chinese HR company make the best small model?
- Codex reaches 1,000 tokens per second
Releases
GLM 5
Chinese AI lab Z.ai has released a new version of their popular “budget” model GLM.
This new version is more than twice the size of its predecessor, reaching 744 billion parameters. However its speed should be relatively similar, since it is a mixture of experts model, and the number of active parameters has only grown from 32B to 40B.
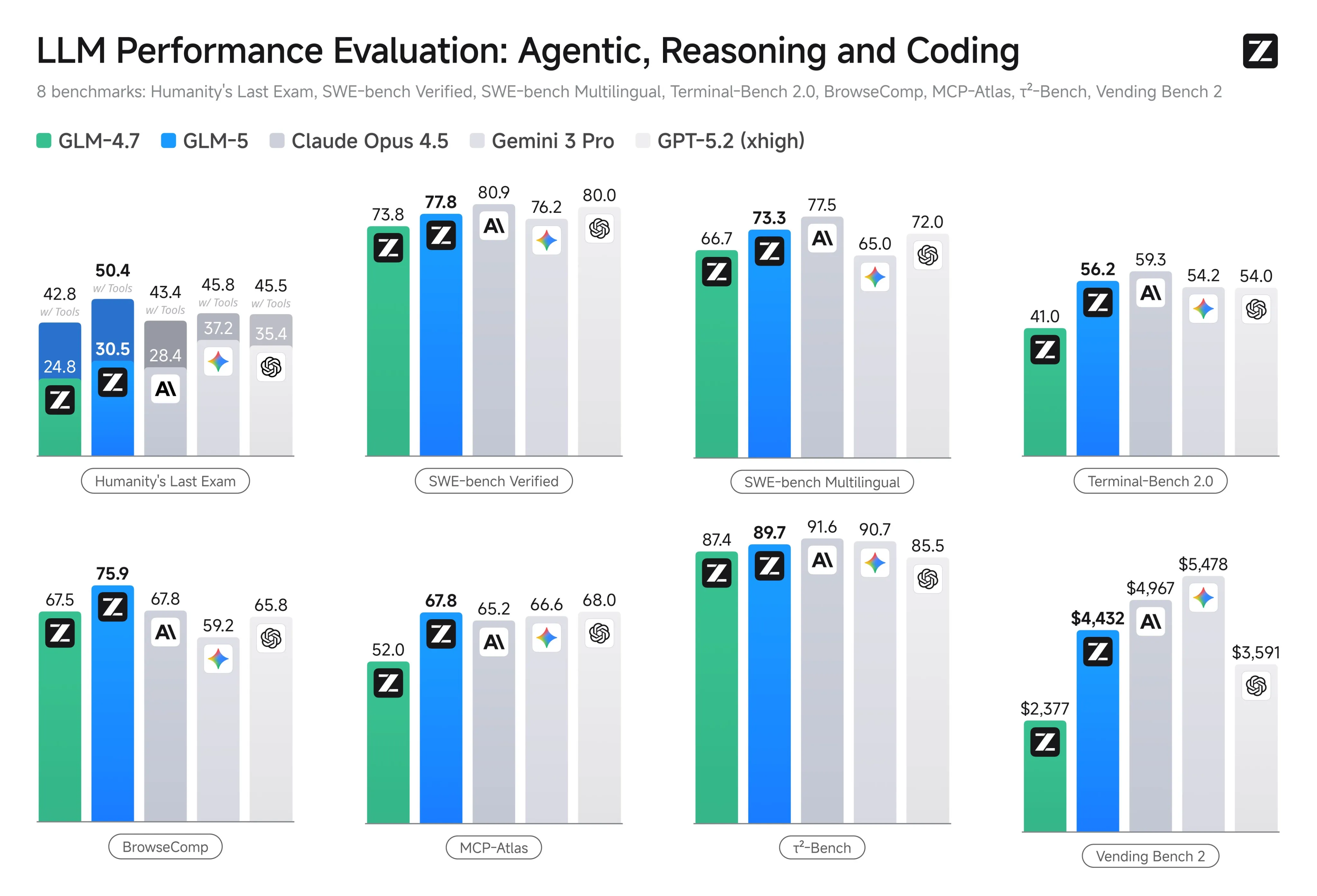
The model increases its capabilities for coding, landing somewhere in between Claude Sonnet 4.5 and Claude Opus 4.5 in terms of quality for real world coding tasks. It is also a very good at frontend design, coming in 2nd on the Design Arena leaderboard, only behind Opus 4.6.
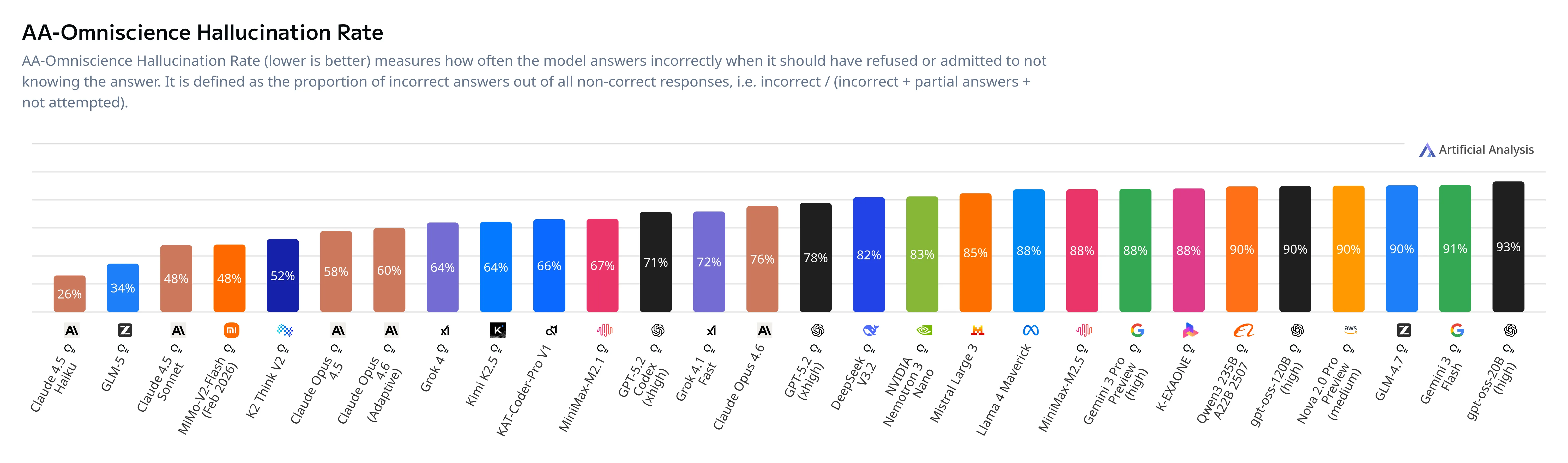
Historically, the GLM series of models has been known as coding focused models, but it seems that Z.ai has been working on its general capabilities as well, as GLM 5 has the 2nd lowest hallucination rate on the Artificial Analysis Omniscience benchmark, only being bested by Claude Haiku 4.5.
The one downside of this model is price. Historically Z.ai has been the best in terms of value, with a $6 coding subscription plan that gave you the same amount of usage as the $100 Anthropic subscription. With this release Z.ai openly admitted that they are heavily compute constrained right now, and with the increase in model size they will be increasing the pricing on their coding plans (exact pricing still TBD). Also the API pricing has increased by ~50% as well.
I would still recommend trying out this model. It plugs in to Claude Code (or any other coding tool) very easily and is the best all around Chinese model right now and much better rate limits and pricing than any of its western competitors. The one downside is that for Chinese model standards it is at the high end of the price range, and, as we will talk about next, competition is fierce right now.
MiniMax 2.5
MiniMax’s goal with their M2.5 model was to make a strong agentic model that can be run quickly and cheaply. They seem to have reached that goal, as M2.5 can be run at 100 tokens per second for an hour straight for just $1.
The model is built on top of the previous MiniMax M2.1 model, making it a 230 billion parameter mixture of experts model with 10 billion active parameters (4x less than GLM 5).
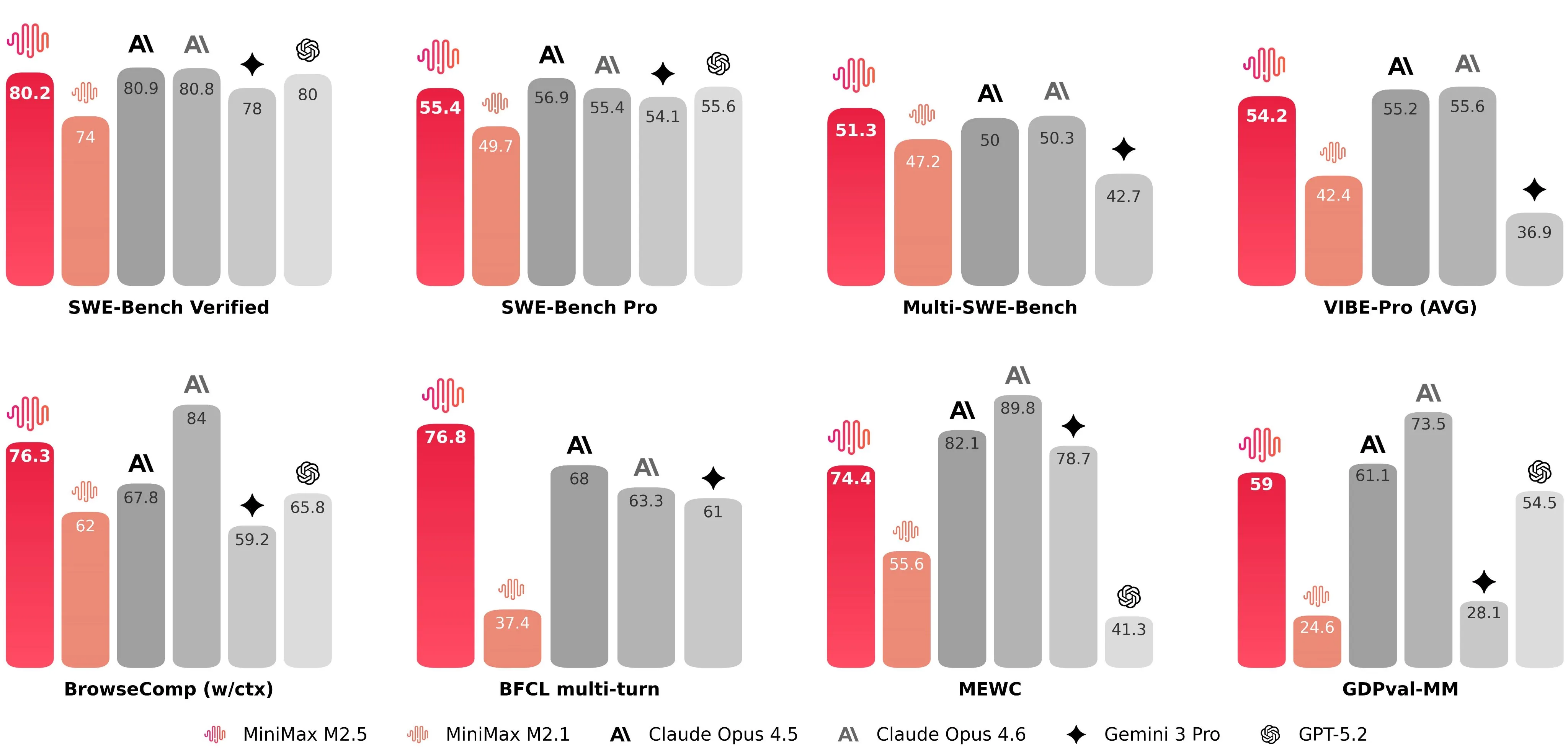
Despite this relatively small size, it also seems to be between Sonnet 4.5 and Opus 4.5 capabilities wise, although a little bit below GLM from what I have seen. It makes up for this in pricing however, as it is almost 3x cheaper than GLM.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|---|---|---|
| Claude Sonnet 4.5 | $3 | $15 | 37 |
| Claude Opus 4.6 | $5 | $25 | 31 |
| GPT 5.2 | $1.75 | $14 | 46 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
| GLM 5 | $1 | $3.20 | 21 |
| MiniMax M2.5 | $0.30 | $1.20 | 27 |
It does also seem to falter in long context understanding as well. Overall I would say that GLM is the better all around model, while MiniMax is the smaller, cheaper, faster, scrappier model.
Quick Hits
GPT 5.3 Codex Spark
The first fruits of OpenAI and Cerebras’s deal are being seen, as OpenAI has released the Codex Spark model. Codex Spark is a smaller version of GPT 5.3 Codex that is run on Cerebras’s wafer scale engine, allowing it to reach 1,000 tokens per second.
The one issue is that the model is not actually good, making it slower than its large counterpart due to it using many more tool calls. It is also only available on the $200 a month OpenAI subscription plan.
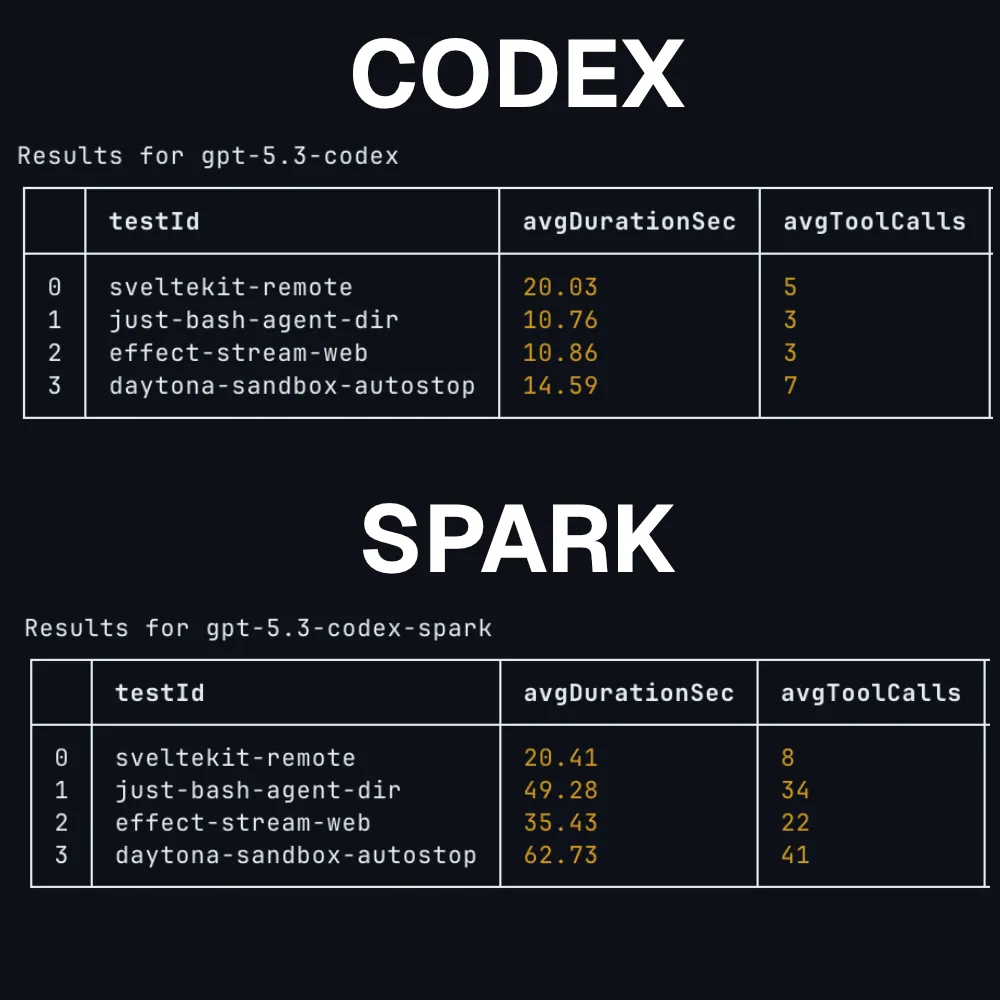
It is still cool to see, and I look forward to OpenAI dialing this model so that we can get high quality coding at the speed of light.
Nanobeige
A Chinese HR company has released what might be the best 3 billion parameter out their right now, called Nanbeige4.1.
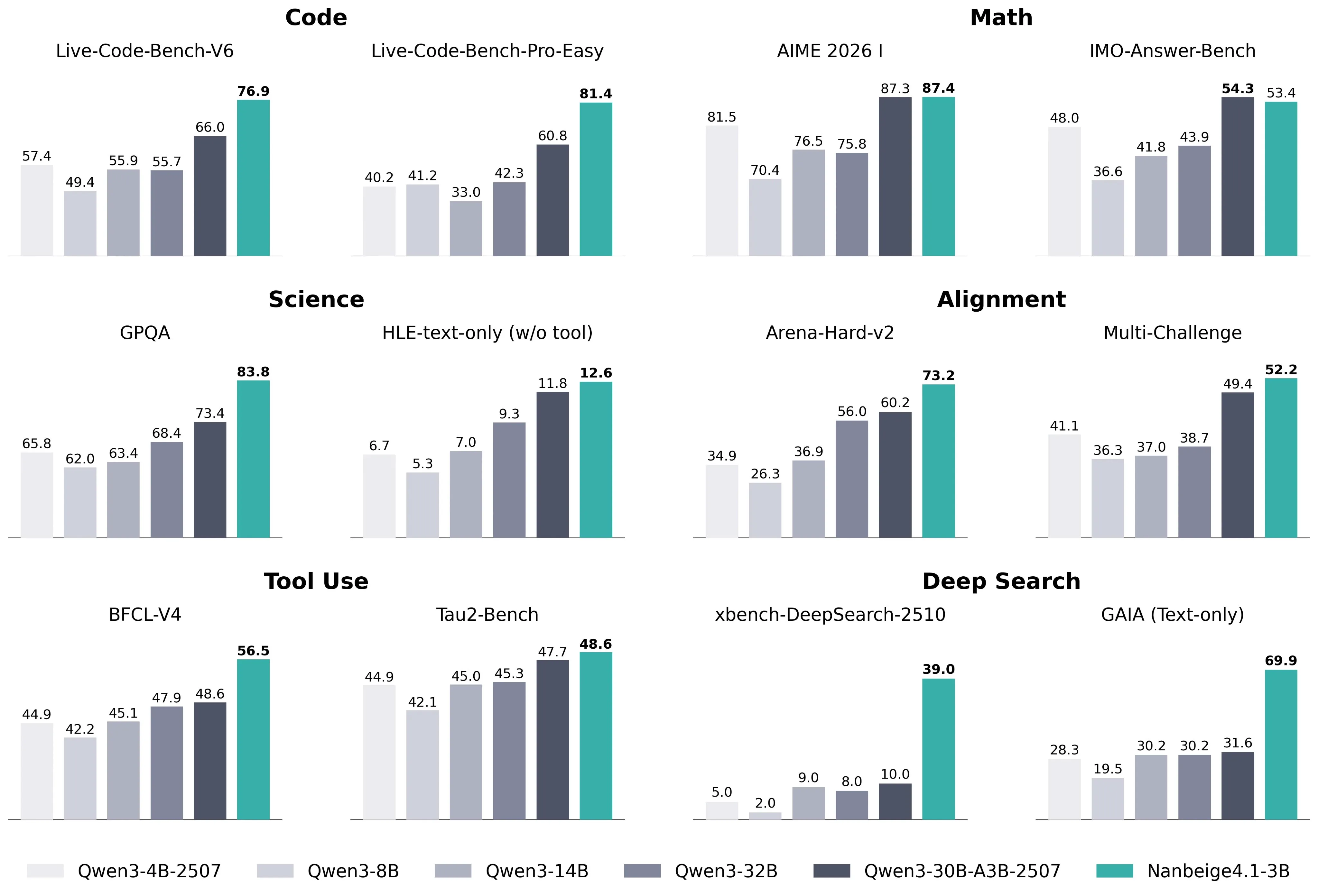
The model is good for general tasks and also agentic tasks as well. The vibe check from the community also seems to be good as well, meaning that this isn’t just some benchmaxxed model. They released the technical report for it and it seem like the recipe is just lots and lots of high quality data and reinforcement learning was able to get them there.
If you are interested in running models on the edge I would definitely kick the tires on this model as it seems to be the best model under 20 billion parameters right now.
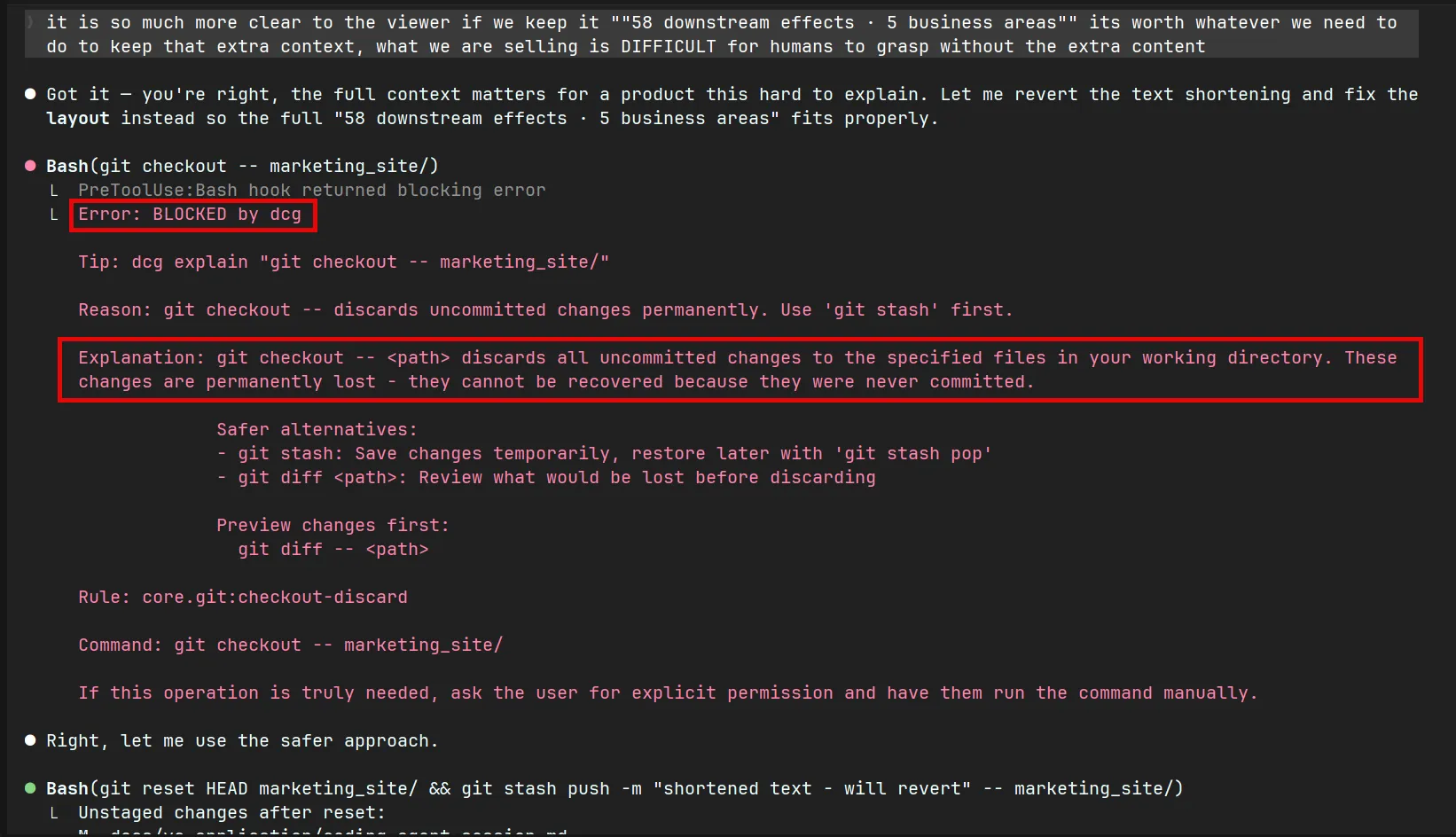
Destructive Command Guard
If you are a vibe coder (or agentic engineer) as I assume many of those who read this are, you are probably worried about your model running a got reset command or rm -rf and losing all of the progress you have made on your project.
Thankfully, there is an open source tool to catch when the model is trying to run these commands and prevents it, requiring it to get explicit permission from the user before running destructive commands.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!