PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Anthropic vs Department of War
Anthropic goes to battle against the DoW, Google releases Nano Banana 2, and Qwen releases the medium sized Qwen 3.5 models
tl;dr
News
Anthropic VS DoW
Anthropic, along most of the major US AI labs, have had deals with the US government to deploy their AI models for use in different departments, including for classified use cases.
After finding out one of their models (a fine tuned version of Sonnet 4.5) was used to help capture Venezuelan president Nicolas Maduro, Anthropic wanted assurances from the government that Claude was not being used for any use cases that Anthropic did not want it being used for; specifically, making autonomous weapons (the models are not good enough to do this yet) and mass surveillance of American citizens.
In response, the Department of War (DoW) (previously the Department of Defense) said that they should be allowed “all lawful use”, but Anthropic held firm in they demands. Because they did not give in to the governments demands, Anthropic has now been labeled as a supply chain risk, which means that Claude cannot be used by the Department of War or for any DoW contracts.
After this happened, OpenAI signed a contract with the DoW themselves. Sam Altman claimed that the same ideals that Anthropic had were upheld by OpenAI as well, and that the DoW agreed with these terms. This is contradicted by the DoW UnderSecretary, who says that OpenAI gave them the “all lawful use” clause that they wanted, with “mutually agreed upon safety mechanisms”, which Anthropic was also offered but turned down.
The situation is still developing as I write this, so I will reserve any opinions until everything that has and will happen is clear.
Releases
Nano Banana 2
Into more lighthearted news, Google has released a new version of their popular Nano Banana image generation (and editing) model.
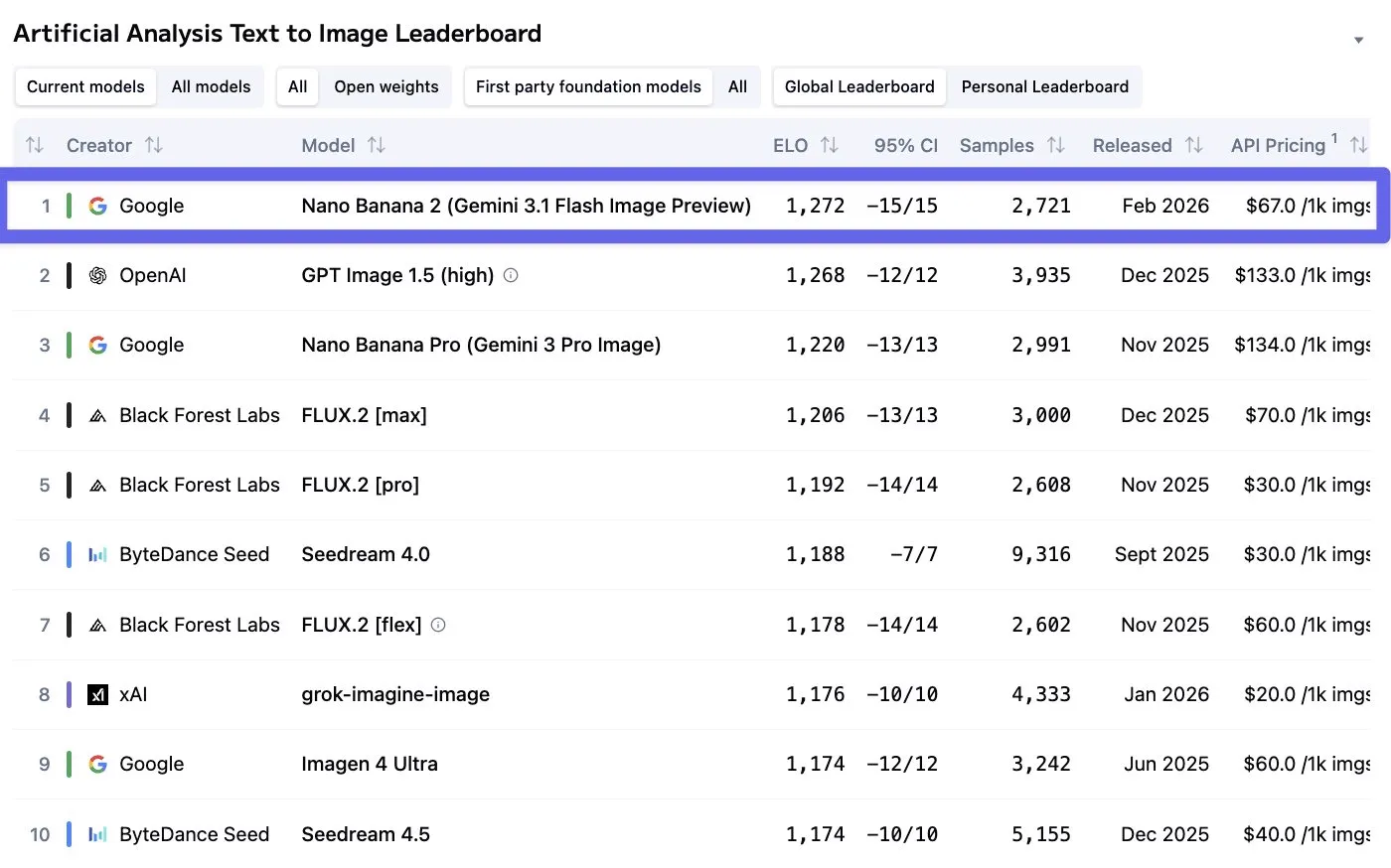
Not only is the quality measurably increased, it also has gotten cheaper and faster as well, as it is built on the (unreleased) Gemini 3.1 Flash model. Pricing has roughly halved to $0.15 per 4K image, and speeds are around 50% faster now as well. The model also now supports more extreme aspect ratios, like 4:1 and 8:1, allowing you to make some very wide (or tall) images.


Qwen 3.5 Medium Models
Qwen started the release of their 3.5 series of models last week, releasing the largest model in the family, a 400 billion parameter model. It was not very interesting or notably good however, so we did not cover it. This week though, they released the medium sized models in the family, and they are much more interesting. We have 3 new open source models, being Qwen3.5-35B-A3B, Qwen3.5-122B-A10B, Qwen3.5-27B, and a closed source model, which is Qwen3.5-Flash, which is the 35B model with longer context length and some built in tools.
For the model naming, the A3B and A10B means that the models are mixture of experts models, with 3 billion and 10 billion parameters respectively. This means that they will run as fast as a 3 (or 10) billion parameter model while having the intelligence of a 35 (or 122) billion parameter model (roughly).
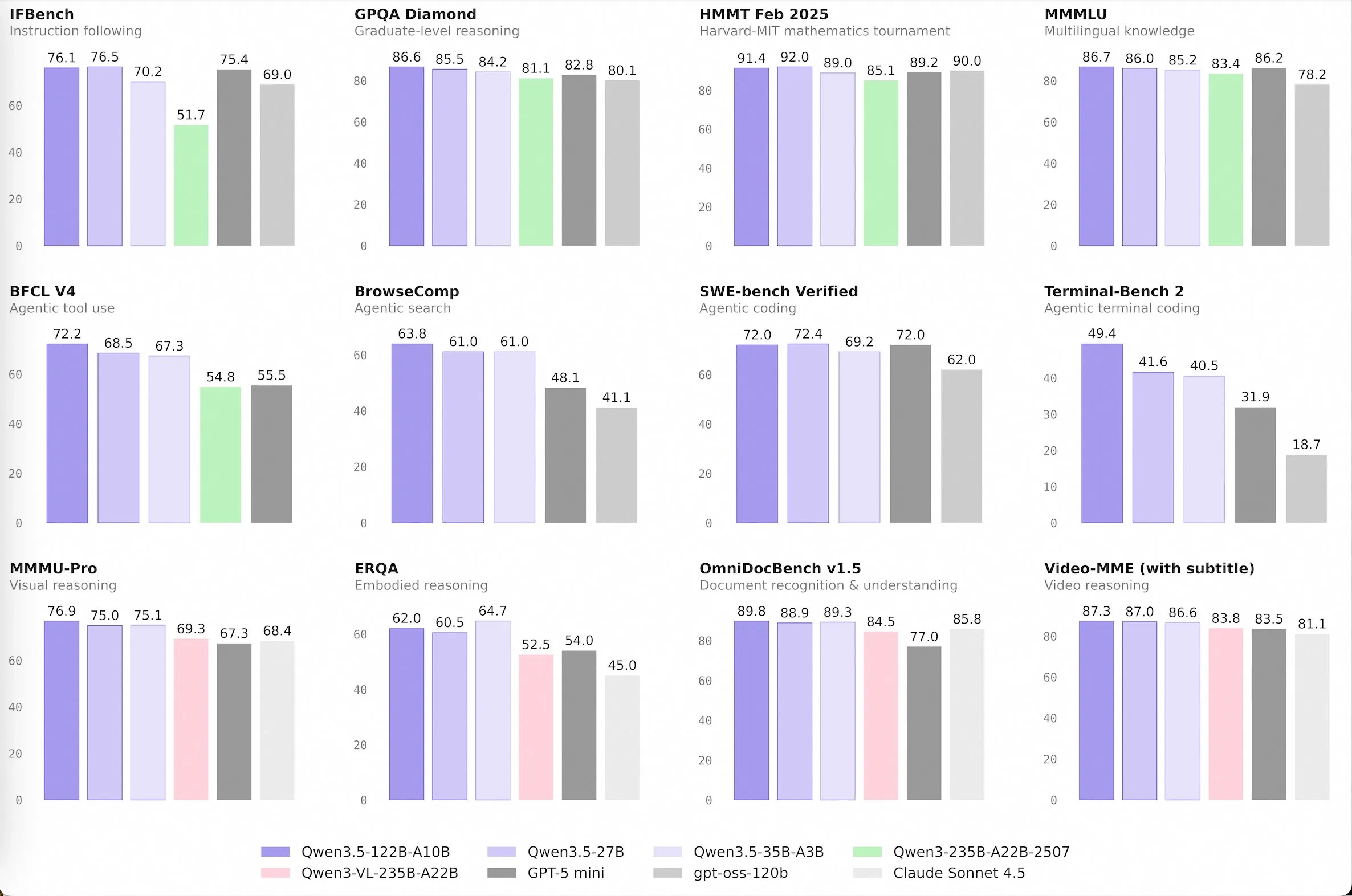
The standout of these models is the 35B-A3B model. This size is fairly easy to run at home, if you have a Mac with at least 24GB of memory or a PC with a GPU and >24GB of CPU + GPU memory you can run it.
For its size, it is the best model out there right now, beating the likes of GLM 4.7 Flash and NanBeige, and even outclassing models 5-10x larger like GPT-oss 120B and the old Qwen 3 flagship 235B model.
Normally, the Qwen models are text only models, and then the Qwen team makes a finetune of them a few months later to add in multimodal capabilities. This is not the case this time however, as all of the Qwen 3.5 models support image (and video) inputs.
The dense 27 billion parameter model seems even smarter, the issue is that because it is not a MoE model it is 5-10x slower to run, especially on compute constrained devices. It is noticeably better at difficult agentic applications, like coding.
If you like running local models and have decent hardware, I would highly recommend checking out some of these models. If you are not compute middle class, worry not, as Qwen should be releasing the small models in the next week or two.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!