PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Is Google back?
Gemini 3.1, Sonnet 4.6, and AI slop detection
tl;dr
- Can Google beat GPT 5.2 and Opus 4.6?
- How does Sonnet 4.6 stack up to the rest of the competition
- Detection AI slop in the browser
Releases
Gemini 3.1 Pro
Google has released an update to their flagship model, Gemini Pro. Of late, Google has fallen behind the frontier models from OpenAI and Anthropic, so is this a return to the top for them?
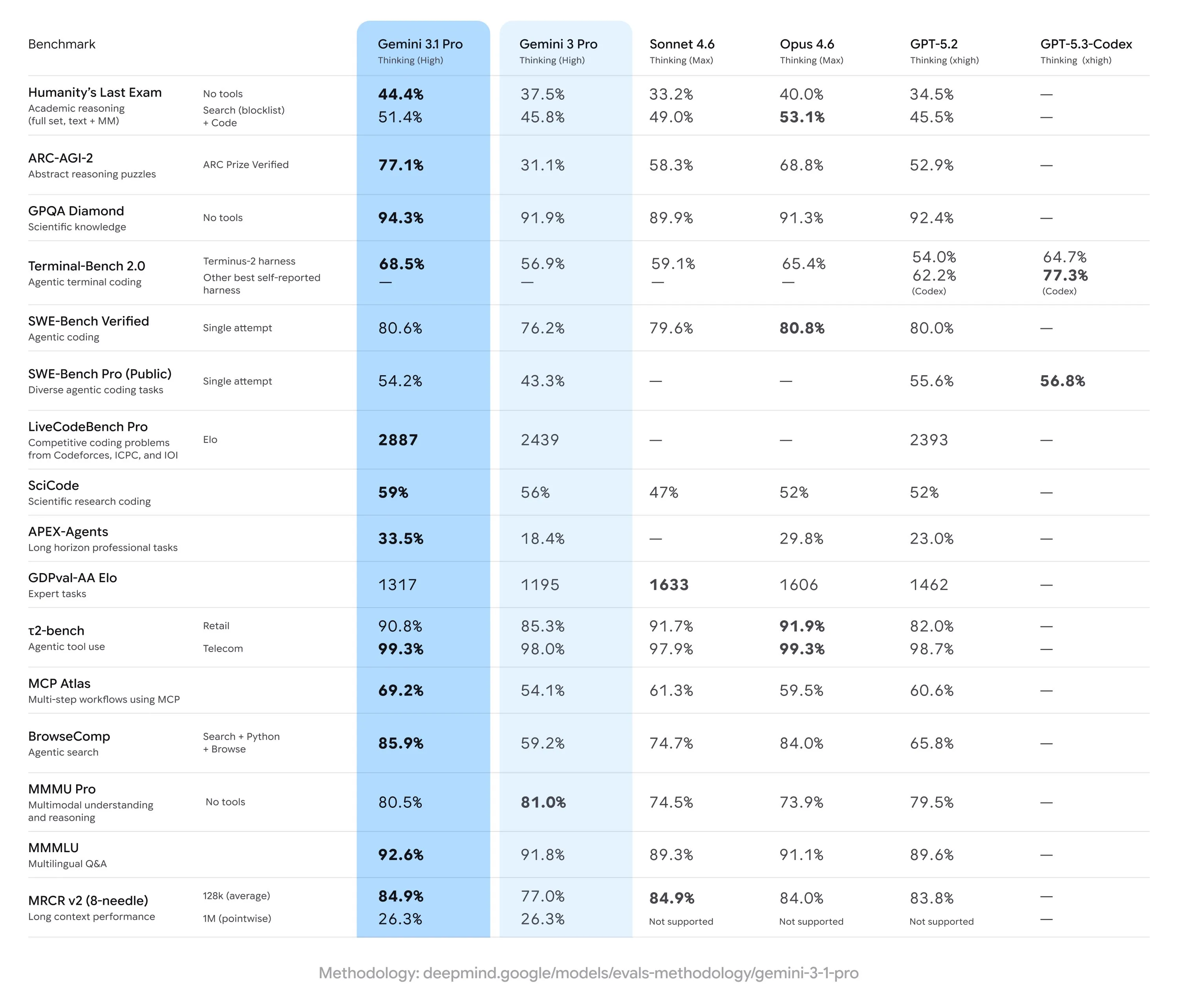
Based on the benchmarks that Google has released with the model (which very nicely includes all of the scores for every other major model), Gemini 3.1 Pro seems to be the best model out there right now. Sadly this is not the case however, and seems to be a case of benchmaxxing from Google.
In the majority of 3rd party evaluations, we see a regression in capabilities versus Gemini 3 Pro. This is not isolated to a few types of benchmarks either. We see worse scores across a variety of benchmarks, including Design Arena, which measure the model’s design capabilities for frontend tasks, Vending Bench, which measures agentic capabilities and long term planning, and EQ bench, which measures soft skills like emotional intelligence and create writing.
Also for real world usage, I have seen complaints from users about poor coding capabilities and code quality, doom loops where the model keeps repeating the same thing over and over, and an overall worse experience.
With this release, Google has not only failed to beat OpenAI or Anthropic, but they have failed to beat themselves. Why might this be? My guess is poor post training.
Google has the resources both in terms of data and compute to have a really strong pretrained base model to start from. This step does not require too much finesse and is instead just a function of high quality data, model size, and compute FLOPs, all of which Google clearly has.
Post training (supervised finetuning and reinforcement learning) on the other hand requires a lot more taste and refinement, and cannot just be done in a brute force manner of “more is better”. When you take this “more is better” approach, and don’t actually assess the model directly and instead just look at benchmark scores, you end up with a benchmaxxed model like we see here. It seems very much like the performance of the people post training the model is based on benchmark scores instead of actual model quality.
If Google wants to be able to compete at the top, they need to completely overhaul their philosophy around how they are post-training their models, otherwise they will quickly fade into irrelevance.
I would also be worried about the release schedule if I were at Google. From the time Gemini 3 was released to now, OpenAI and Anthropic have both shipped 3 major updates to their models, which has been Google’s first in 3 months. If they want to continue to compete at the top, they will have to start training and shipping models faster.
Sonnet 4.6
Speaking of Anthropic releases, they have released an update for their midsized Sonnet model.

The model is another good, quality release from Anthropic, updating Sonnet so that it is not so far away in terms of capabilities versus its bigger brother Opus. It does inherit the questionable safety considerations that I talked about in my Opus 4.6 review last week, as evidenced by its behavior in Vending Bench.
In terms of real world coding capabilities, I have been using it in Claude Code this week, and it seems able to get tasks done at a rate somewhere in between Opus 4.5 and Opus 4.6, but writes slightly lower quality code and still runs some silly commands which can get itself stuck at points, although it is usually able to correct. Because of this, I put it in the same tier as Opus 4.5 and GPT 5.2: very capable, but not fully frontier.
As always, its pricing is a bit weird, being more expensive than GPT 5.x, even though it is not as good of a model. I would love to see Anthropic drop the price of Sonnet the same way they did for Opus. If they halved the price from $15 to $7.50 per million output tokens, the model would be a hard value to pass up, but at its current price it sits in a weird place.
I have been ranking many of the models relative to each other, so I decided to put something together to show my rankings. These ranks are specifically for coding. If you don’t see a model on these rankings, it’s because I don’t recommend using it for coding at all.
Frontier models
- GPT 5.3 Codex
- Opus 4.6
Second tier
- Sonnet 4.6
- GPT 5.2
- Opus 4.5
Third tier
- GLM 5
- Minimax M2.5
- Kimi K2.5
Quick Hits
AI Slop Detector
AI slop (and its detection) has becoming something we see every day now. Distil labs has made a small finetune of Gemma 3 270M that can detect AI slop.
At this size it is feasible to run in your browser or as a part of a chrome extension. There are also some cool ideas around how they made a high quality dataset from very little human made/validated data.
Note that this is not an AI post detector, it just detects if the writing quality is similar to AI slop.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Stay Updated
Subscribe to get the latest AI news in your inbox every week!