PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
New Year, New AI
Can AI train more AI? How to use Claude as a on-call engineer, and a new Qwen Image model
tl;dr
- Can an AI train other AI’s?
- Claude as your on-call engineer
- New Qwen Image model release
Quick Hits
This was one of the quietest weeks of the year due to the holidays, so there is no major news or releases to be highlighted.
Post train bench
How good are LLM’s at finetuning other LLM’s?
That is what a group of researchers wanted to find out, so they made PostTrainBench, which measures how well model’s can finetune small LLMs do do better on some common benchmarks. They then compare the LLM’s results to a human finetuned baseline.
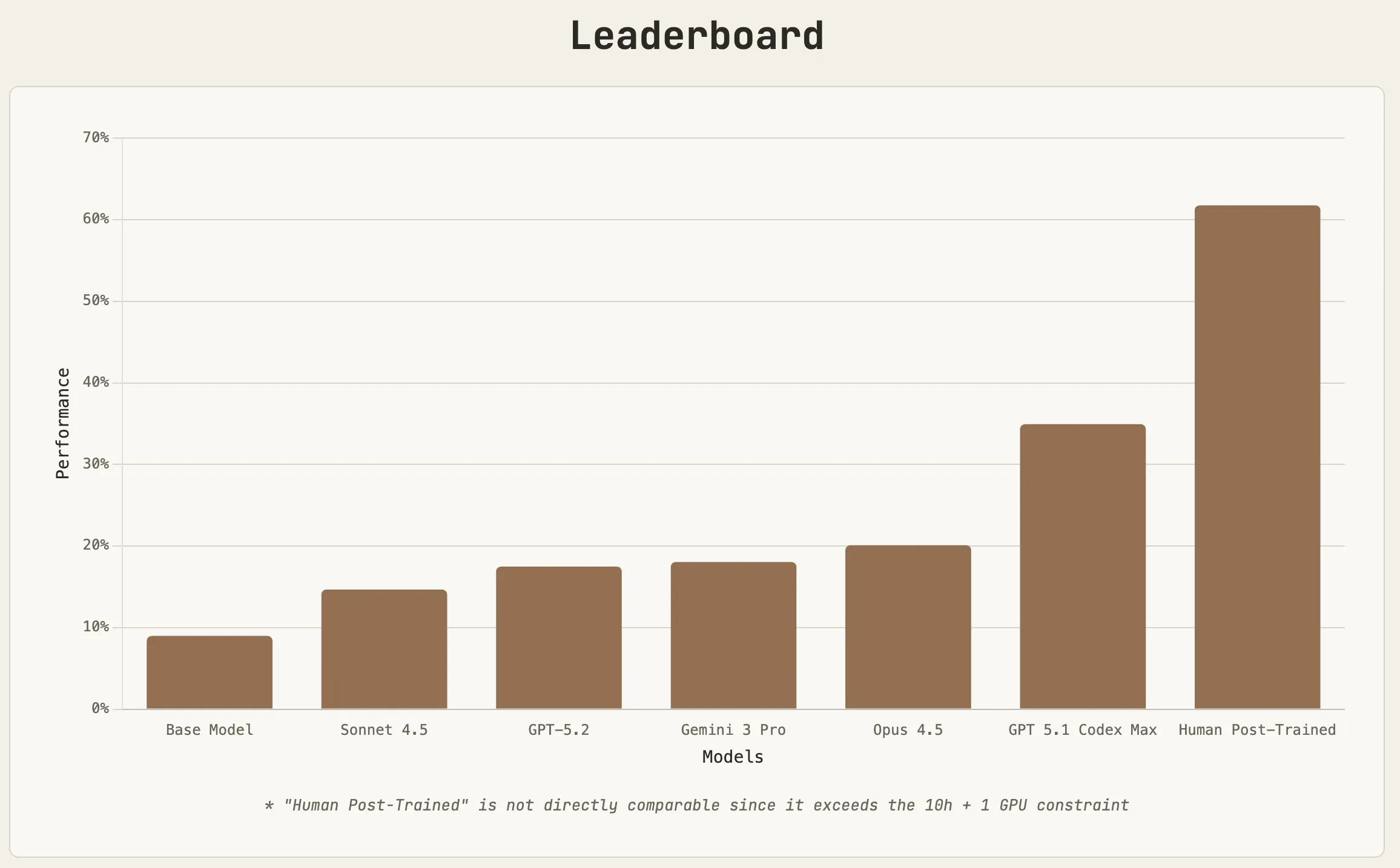
For the benchmark, there are 4 models that must be finetuned for a particular benchmark, and the LLM’s are given 10 hours on an H100 to get it done. All of the models being evaluated used their native harnesses (ie Claude Code, Codex, or the Gemini CLI). The time was not a bottleneck for the models, as all of them finished before the 10 hours was used up. The quality of the trained models was mostly to do with data curation, which GPT 5.1 was able to do the best.
I was surprised how well the models were able to do, and that they were all able to get an increase in score versus the base model. GPT 5.2 is a step up from 5.1 as well, so my guess is that the difference between humans and models is even less than what is shown.
Qwen Image 2512
Continuing the refresh of their image models, the Qwen team has released a update for their Qwen Image model.
The Qwen Image model has fallen behind its open source competitors in Z Image (which is also from Alibaba) and Flux 2, and this release puts it in the same ballpark as those in terms of quality.
I would still recommend using Z Image, as it has similar quality while being faster and cheaper. Compared to Flux 2, it is smaller, and has better community support since all of the existing loras made for the previous should still work with this refreshed model.
Claude as your on call engineer
Monitoring and fixing deployment issues will quite literally keep you up at night. But what if they didn’t?
Denislav Gavrilov had the idea of attaching Claude to the logs of his deployment cluster, and have it diagnose and hot fix any issues that came about, effectively making a 24/7 on-call engineer.
I personally would use GPT 5.2, as it has much better bug hunting ability, especially for more difficult issues, but the idea is still good nonetheless.
I think we will be seeing a lot more of this LLM “self healing” in future. Imagine that as you are testing your app and you run into a http 500 error, your coding agent sees this and immediately fixes it for you instead of you needing to copy the error or describe the issue to it.
I can also see this being used for web scraping tasks. Websites often change and break your information retrieval scripts, so if you detect a break or deviation in the site’s content, have an LLM immediately be fired up to go and investigate what changed and how to fix it. This will allow LLM’s to be able to proactively work for you with zero input needed from the user, freeing you up to do more productive and proactive tasks versus needing to maintain existing projects and infrastructure.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Stay Updated
Subscribe to get the latest AI news in your inbox every week!