PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Gemini 3 Flash
Is Gemini 3 Flash the best value LLM? Nvidia releases the best LLM to run at home, GPT 5.2 Codex, and a new SOTA open source voice cloning model
tl;dr
- Is Gemini 3 Flash the best value LLM?
- Nvidia releases the best LLM to run at home
- New SOTA open source voice cloning model
- And more!
Releases
Gemini 3 Flash
Google has released the smaller, cheaper, faster version of their Gemini 3 Pro model, Gemini 3 Flash.
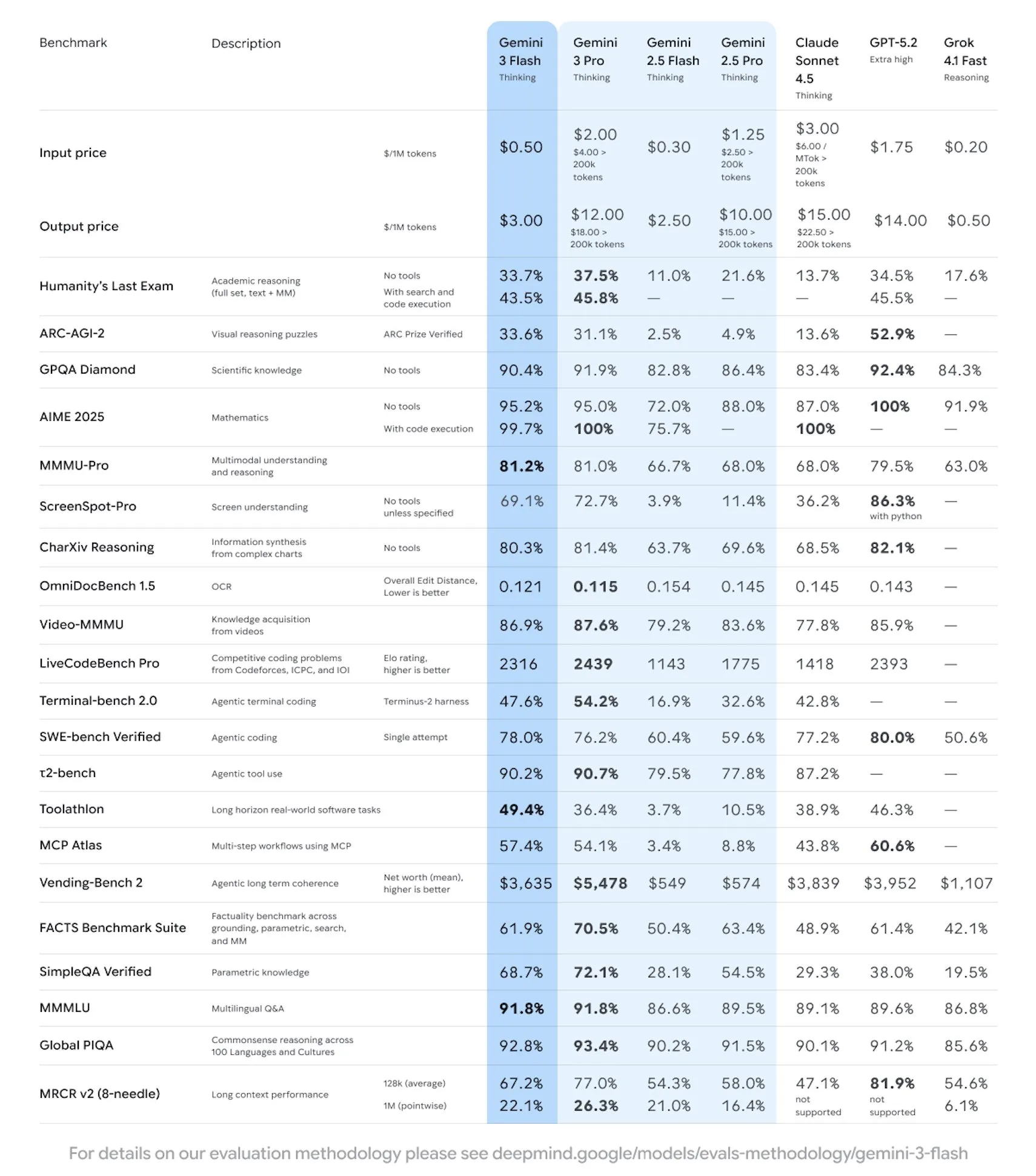
It is a strong model, especially given its pricing. For most tasks it will be passable, if not equal to many of the top models out there right now. It is on the Pareto frontier for intelligence per dollar. If you are looking for an alternative to the cheap Chinese LLM’s this is a great option to look at, as it seems to be just as good if not better across the board.
For coding it is definitely usable for easy and maybe even medium difficulty tasks. You may notice in some of the coding benchmarks it actually outdoes Gemini 3 Pro. According to the team at Google, this is because they were able to spend more time RL’ing the model before release. This does not seem to translate to real world performance however, and is just a bit of benchmaxxing.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|---|---|---|
| GLM 4.6 | $0.60 | $2.20 | 90 |
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5.2 | $1.75 | $14 | 34 |
| Kimi K2 Thinking | $0.6 | $2.50 | 25 |
| Gemini 3 Pro | $2 | $12 | 80 |
| Gemini 3 Flash | $0.50 | $3 | 75 |
Overall a very solid model that I would check out if you are looking for a good quality LLM that is fast and cheap.
Nemotron 3 Nano
Nvidia has been turning up the open source releases as of late, releasing the first model in their new Nemotron 3 series.
The model is the smallest in the family, called Nemotron 3 Nano and is a mixture of experts model with 30 billion parameters with 3 billion active, putting it at the same size as the Qwen3 30B model. Where it differs from its Qwen3 counterpart is its architecture. Instead of using the usual transformer layers with quadratic attention, it is using a linear variant called Mamba-2, which allows it to have much better speeds as the sequence length increases.
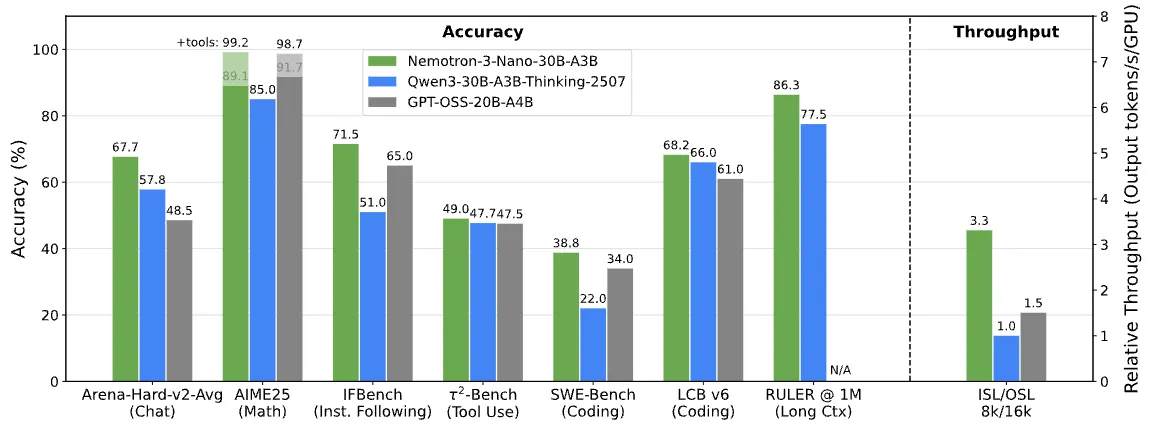
Unlike the Qwen models, which only have the model open sourced, but none of the training infrastructure or data, Nemotron 3 has everything available, including the pretraining data, supervised finetuning data, and reinforcement learning environments.
In the real world, people seem to prefer Nemotron over Qwen, which was the previous best model for its size. This is also reflected in some of the internal benchmarks I have been making (official release coming soon), as it has almost triple the real world knowledge that Qwen 30B has.
If you run models at home, I would definitely recommend checking out this model if you haven’t already. Also expect releases of its two bigger brothers in the near future, which will be ~120 billion and ~480 billion parameters each.
GPT 5.2 Codex
OpenAI has released the coding focused version of their GPT 5.2 model. It is finetuned specifically for using their Codex coding framework, hence the name GPT 5.2 Codex.
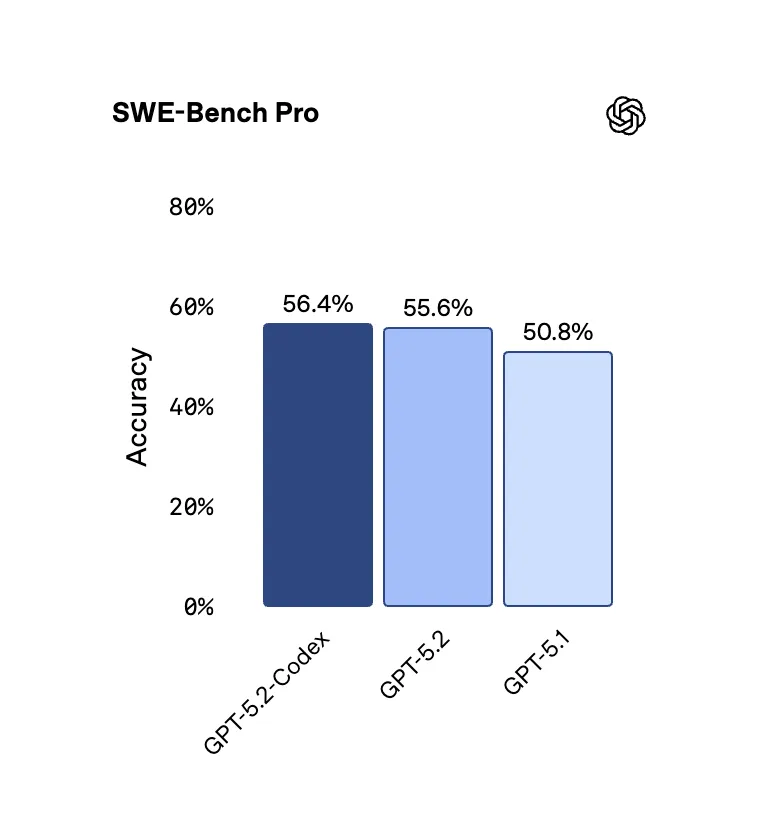
There is not much that stands out about the model on the benchmark side of things. It is most likely just more reliable in the Codex harness than they have for it.
For GPT 5.2, what I have been seeing people say is that it excels for very hard tasks, but for day to day coding it is slow and depending on the task still may not be better than Opus 4.5.
I recently have switched to Opus 4.5 on the Claude Max plan ($100/month) and have yet to run into anything that Opus was unable to crush in one or two prompts for me.
Quick Hits
SOTA Open Source TTS
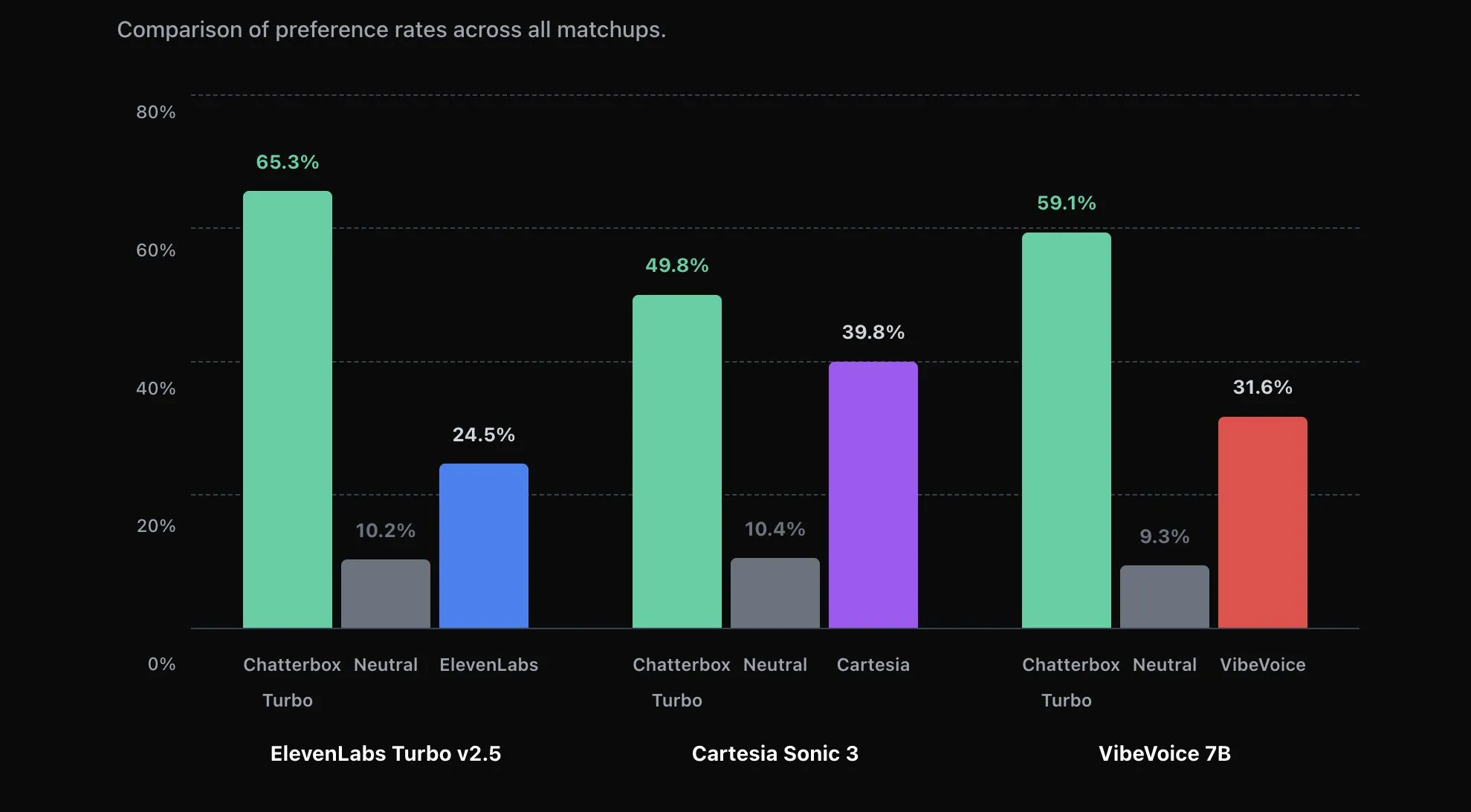
The open source TTS community has been falling behind companies like ElevenLabs, especially when it comes to voice cloning.
We no longer have that issue as Resemble AI has released their Chatterbox Turbo TTS model.
It is an MIT licensed open source model that can do voice cloning off of just 5 seconds of audio, has better performance that Eleven Labs Turbo v2.5, and has 150ms time to first utterance.
I used it to clone my own voice on Huggingface and it did a very good job. It is definitely far above any other open source model I have used, and is just as good as Eleven Labs v3 was for cloning my voice.
Qwen Image Layered
When has released an interesting new image model based on their Qwen Image and Edit lineup.
This model is a layer decomposition model, which allows you to take your reference image and split into multiple layers for you to edit like you would in Photoshop.
The model can then be used to edit each layer for you as well, similar to Qwen Image Edit, giving you much more fine grained control over your images.
Like the other Qwen Image models, it is open source under an Apache 2 license.
Claude Code can use Chrome
A small quality of life improvement for those using Claude Code. If you run the /chrome command, you can set up Claude to be able to use Chrome directly using an extension, which will allow it to view and debug frontend issues all by itself.
Function Gemma
Alongside the Gemini 3 Flash release, Google also released a small 270 million parameter model called Function Gemma that has been trained specifically for function calling.
You are meant to finetune it for your specific task, since it is not a very general model given its small size. Its size does allow it to be deployed pretty much anywhere and will be able to run faster than pretty much any other edge LLM out there.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!