PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Custom Coding Models for All
Cursor and Windsurf launch their own coding models, Kimi releases a CLI,
tl;dr
- Lightning fast coding models from Cursor and Windsurf
- Thinking Machines lay the groundwork for continual learning
Releases
Custom Coding Agent Models
I have said before that the winners of the agent framework battle will be those that control both the harness the model uses and also the model itself, since they will be able to coadapt the harness and the model together. Thus their model will work the best with their harness, giving the best results.
Previously Anthropic and OpenAI were the only major names that had both of these things (along with widespread adoption). The model wrappers, Cursor and Windsurf, did not have such an advantage, which is why I did not recommend using them. This week however, they came out with their own offerings, so lets see how they stack up to GPT-5 and Claude 4.5, and if they are worth switching over to their platforms for.
Windsurf SWE-1.5
For both of the models, their main selling point is not necessarily their quality, but rather their speed. GPT-5 in Codex is the biggest example of slow and good, often taking over 30 minutes to complete a single request. Having a faster iteration loop with the AI is good, especially when you have underspecified criteria where the model won’t be able to get it right the first try no matter how smart it is. If you are going to need to have a back and forth with a model to make a feature, would you rather wait 10 seconds or 15 minutes between responses.
For SWE-1.5, it appears to be trained from the Z.ai GLM 4.5 model (not 4.6, most likely due to training starting before the 4.6 release).
The model is hosted on Cerebras, which offers the fastest LLM inference of any platform by far, allowing for inference speeds exceeding 1.8k tokens per second.
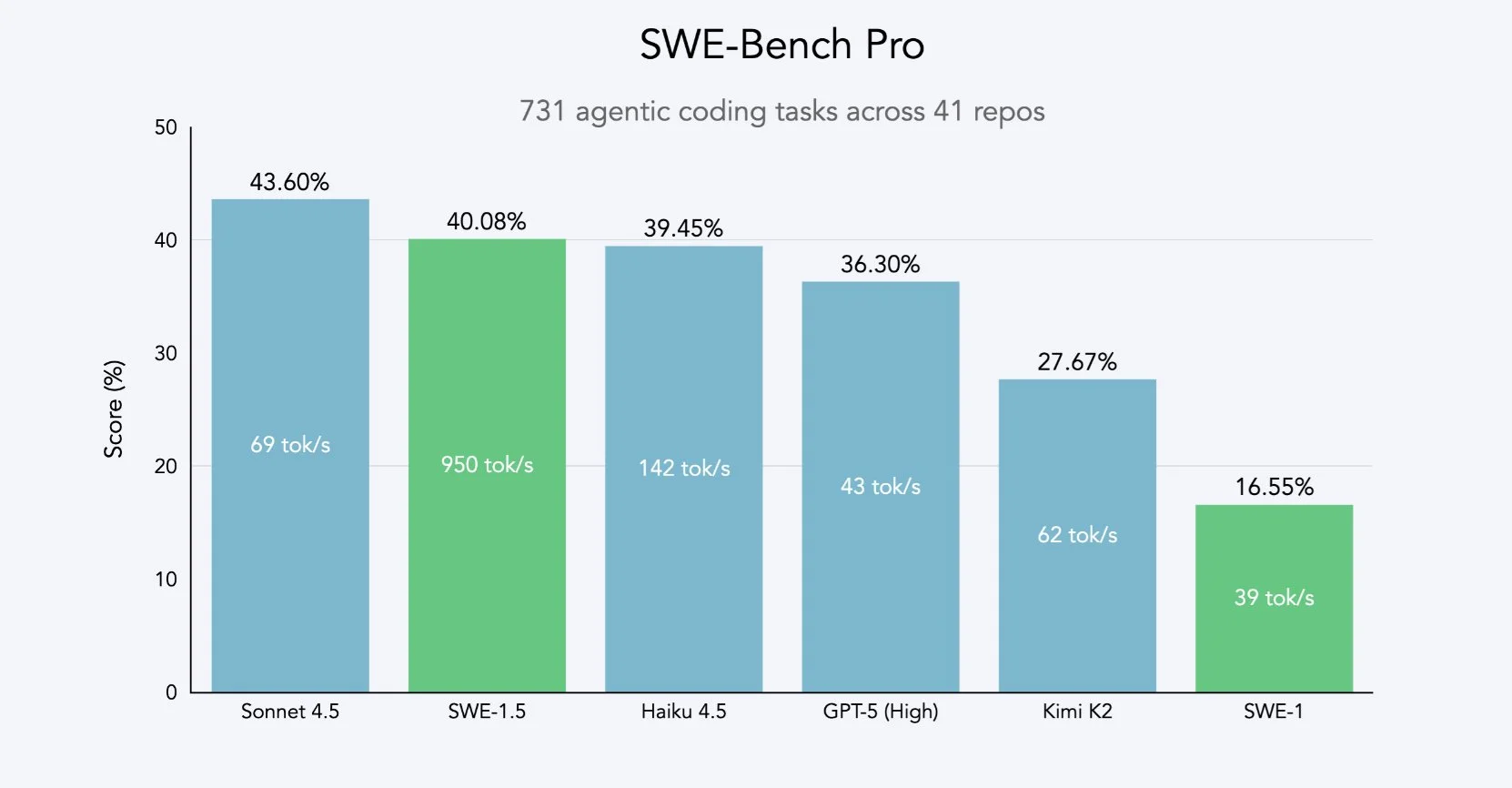
In terms of quality, the model seems to be around GLM 4.6 level, so definitely usable, but not near the frontier level of intelligence that Claude 4.5 and GPT-5 have. Also Cerebras will be offering GLM 4.6 directly in the near future, so I don’t see any need to lock yourself in the Windsurf world to use this model.
It will be interesting to see if Windsurf will be able to tune the model to the point where it is at the same level as GPT and Claude, because then there is significant incentive with the inference speed + quality to go to Windsurf.
Cursor Composer
The headlining feature for the Cursor 2.0 release is their new Cursor Composer model. Similar to SWE-1.5, we do not know for certain what the model they are using is, although it is definitely a fine tune on top of an already existing model. There is evidence that it may be based on Deepseek, but it is not as clear as it is for SWE-1.5.
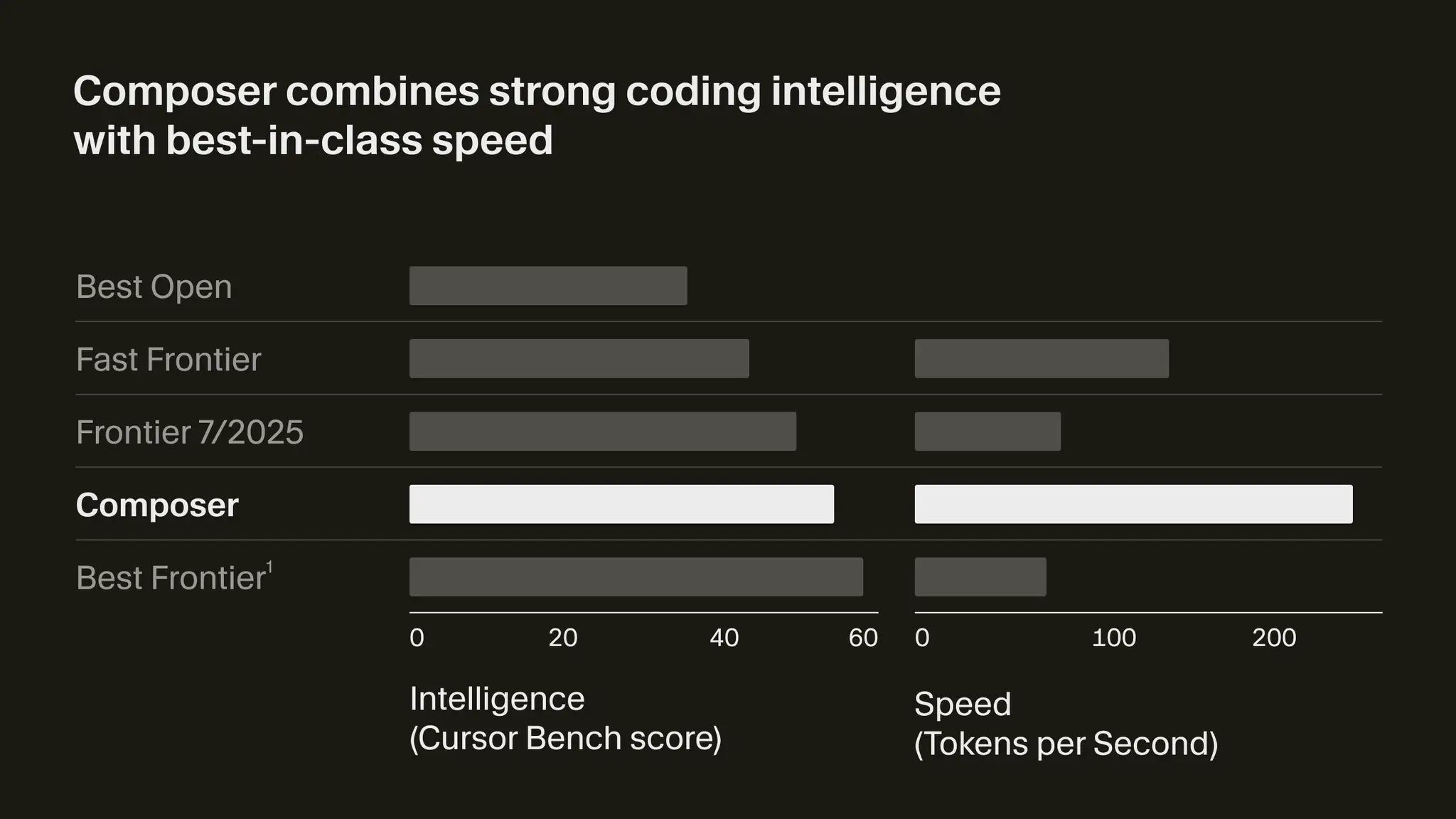
Composer is not hosted on Cerebras, so it is unable to hit the 4 digit token per second speeds that SWE-1.5 can, but it is still fast for a transformer model.
Vibe check on this one is a bit worse than SWE-1.5, probably around Sonnet 3.7 quality. If SWE-1.5 was a pass, then Cursor Composer with its almost 10x slower speeds and worse quality is a hard no.
Research
Continual Learning from Thinking Machines
When trying to finetune a model for your own use case, the most difficult thing to do is encode new information into the model without having it forget what it previously had known and was capable of. The best way for a model to learn information is during the pre or mid training steps, which is just meant for unstructured text. So if you are fine tuning a model that has already had a chat style post training done to it, you would be essentially overwriting its chatbot behaviours with your new info.
Normally you would add in some of the “original” data, or something akin to it, but the model would still struggle to fully recover what it had known and was a very finicky process.
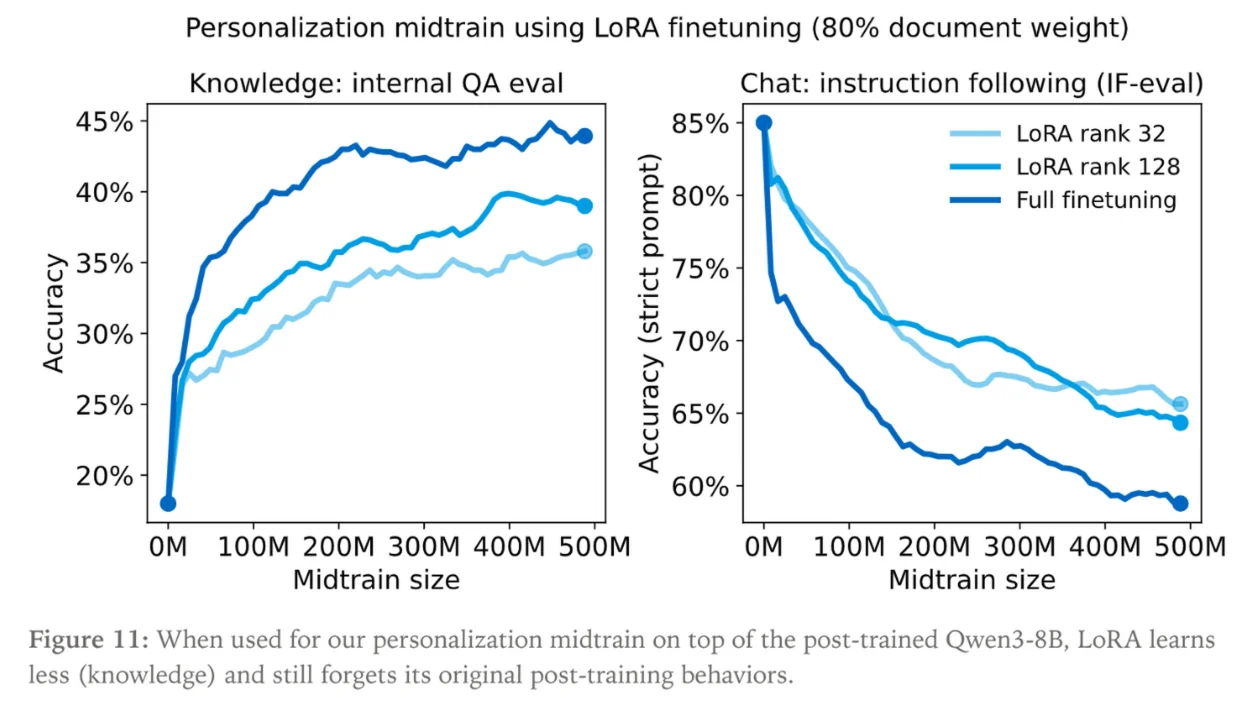
The researchers at Thinking Machines have a fix for this. They propose a new methodology called On-Policy Distillation which allows you to recover the original model quality very easily after doing continued pretraining on your internal documents.
On-Policy Distillation uses the original model (teacher) as a reward model, giving a reward for each token the fine tuned model (student) produces. This way the model learns to mimic the original distribution of knowledge that it had. The surprising thing about this method is that it doesn’t then cause the student to forget any of the new information that it just learned. It also is much more compute efficient than doing a regular finetune, using 50-100x less compute in the process.
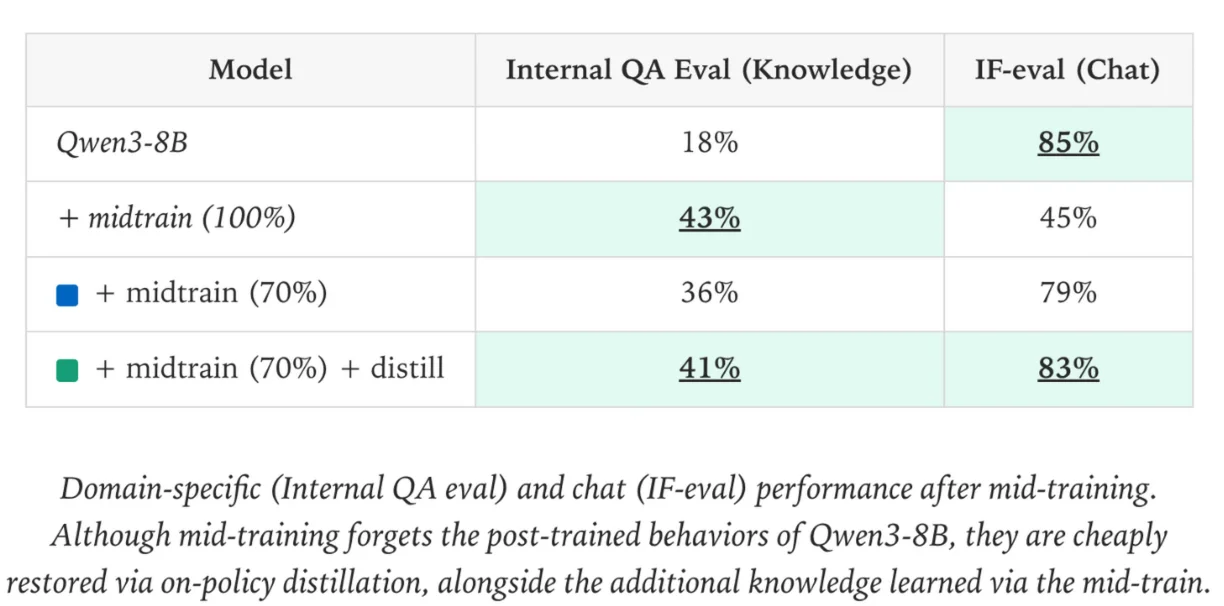
This is not that groundbreaking in terms of research, most of these concepts existed previously, they have just been brought together into a single report here by Thinky.
What is interesting is that this, coupled with Thinking Machines previous releases of a training service and an in depth Lora analysis, seems to point to what the company will be focused on in the future.
They are not chasing the frontier of intelligence like OpenAI and Anthropic are. Instead they are focusing on small, fast, specially catered models that can be iterated on quickly and easily with updated information. I am a big fan of this direction, as I have been skeptical of how much we really need to be scaling models versus focusing them more narrowly for our tasks. Scaling has just been the easiest method, especially with all of the money pouring into the field recently.
I (think) I share the same vision of the future as Thinking Machines, where we are running our own models at home or in small clusters instead of using proprietary models in large datacenters. We will see if this vision holds. I look forward to more releases from Thinking Machines and will be sure to cover anything interesting here.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Stay Updated
Subscribe to get the latest AI news in your inbox every week!