PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Haiku Returns
Haiku makes its return, Veo 3 gets and upgrade, and new leng context benchmarks
tl;dr
- Claude Haiku gets an update after almost a year
- Veo 3.1 is good at image to video
- New benchmarks show how bad LLM’s are long context tasks
- And more Qwen3 VL models
Releases
Claude Haiku 4.5
It has been almost a year since the last Claude Haiku release, so I don’t blame you if you have forgotten about this model. Haiku is the smallest member of the Claude Trinity, and its most recent update had been from the Claude 3.5 series of models, which, depending on how you count it, means its 5 versions behind its brothers Opus and Sonnet.
Haiku 4.5 is being billed as a Sonnet 4 replacement, which puts it squarely against the GLM 4.6 model, so how does it stack up?
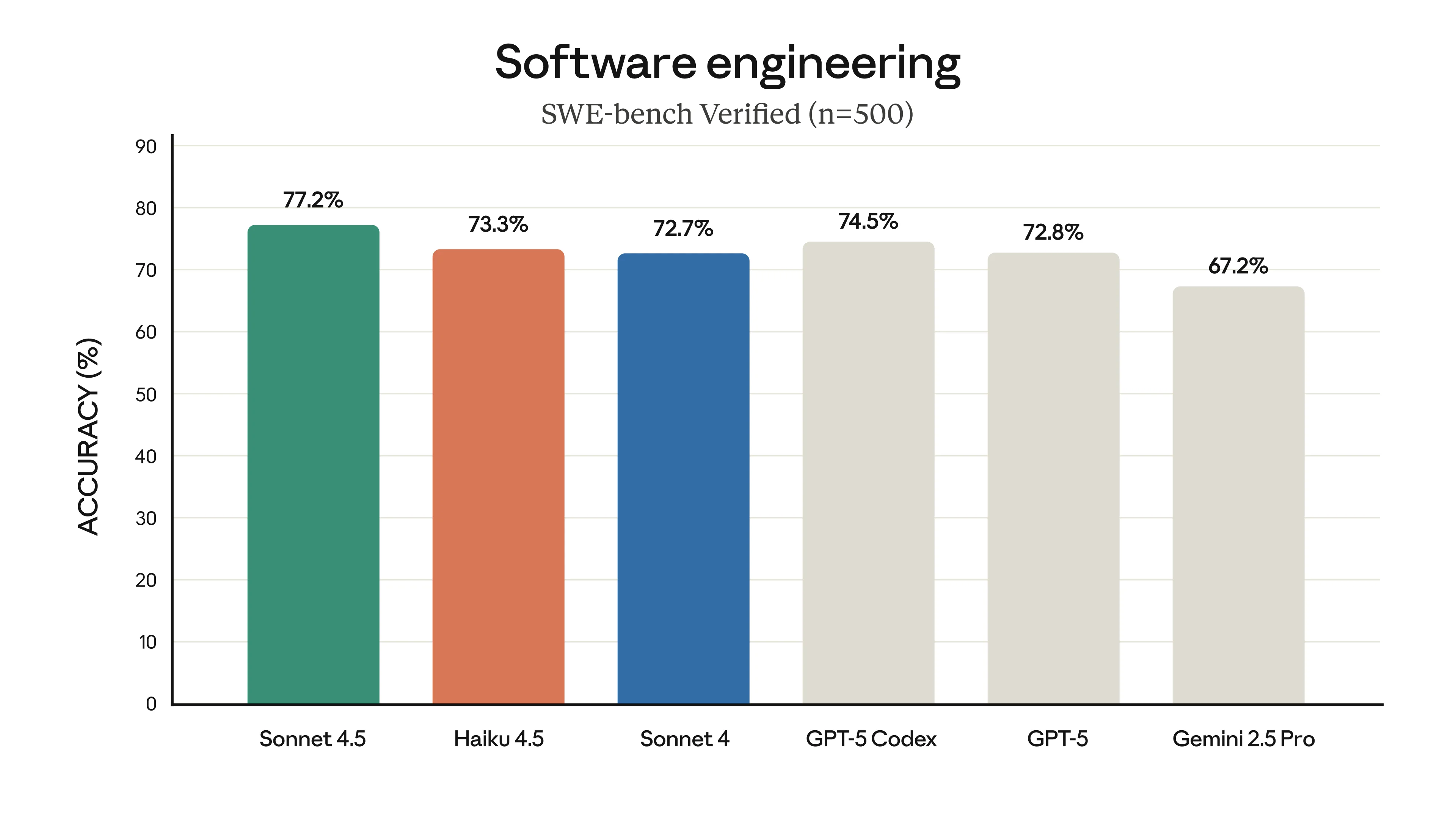
Not very impressively, is the answer. Its one main selling point over GLM 4.6 is that it’s a bit faster, but otherwise it’s about two times more expensive to use.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|---|---|---|
| GLM 4.6 | $0.60 | $2.20 | 46 |
| Claude Haiku 4.5 | $1 | $5 | 106 |
Also, the public consensus seems to put it a bit below Sonnet 4, whereas for GLM 4.6, people tend to prefer it to Sonnet 4.
It is currently unknown how the rate limits are for it in Claude code with the anthropic subscription. But the limits are going to have to be extremely generous to make it a better value than GLM 4.6, especially considering the subscription is almost 10 times more expensive.
Because of this, I don’t think it’s a very interesting or unique release and does not change the LLM landscape at all.
Qwen3 VL 4B and 8B
Qwen continues to release models in their vision lineup, dropping a 4 and 8 billion parameter VLMs based on their Qwen3 models.
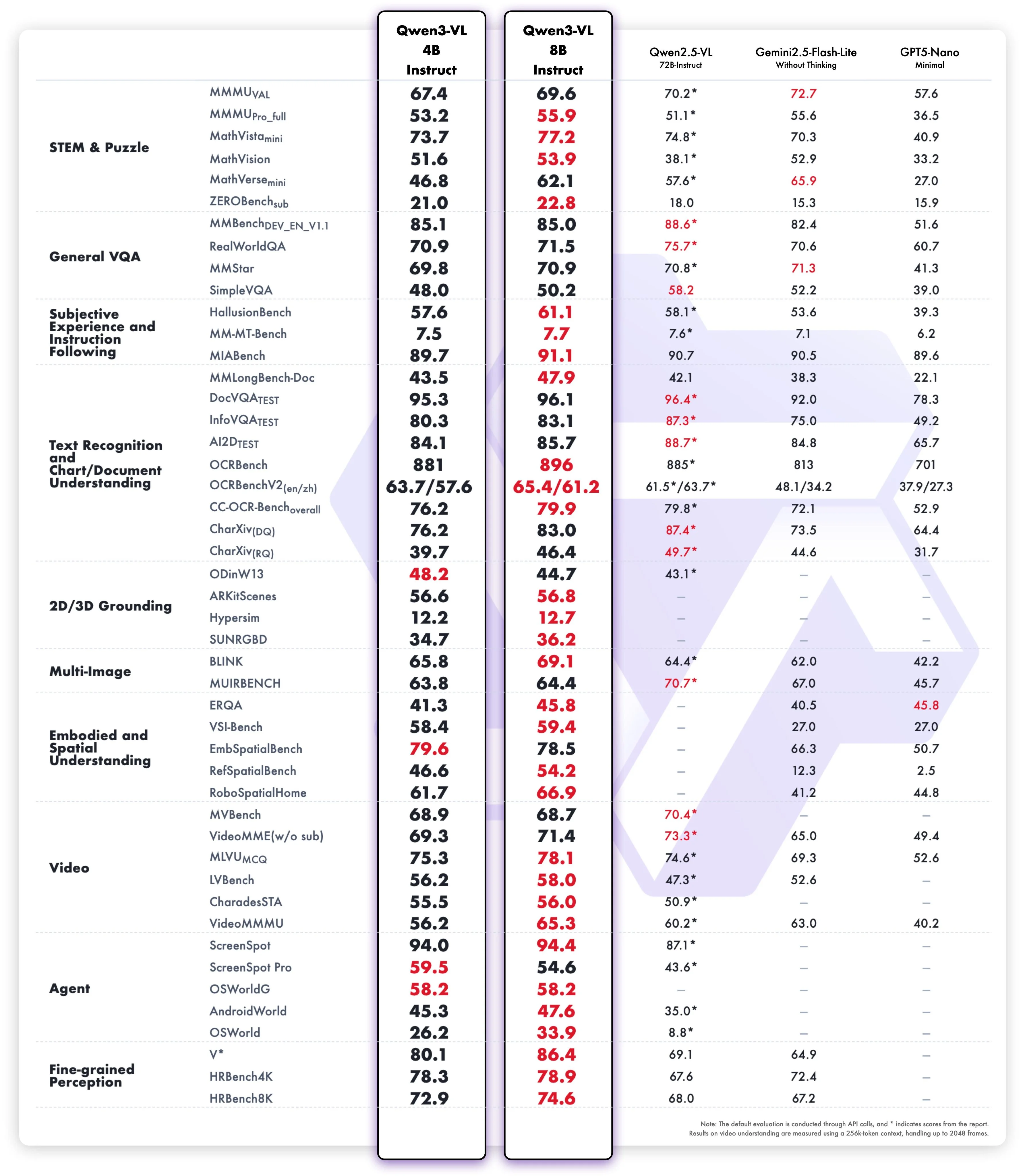
As expected, they are number one for their given sizes. Not that that really means much given that there is not much competition in the open source VLM space right now. Despite this, they are still strong models that are good enough to make them usable in the real world for basic tasks while being able to be deployed on device.
Of note: non-vision benchmarks decreased a bit more than they did for the larger variants, but the difference is still relatively small (1-2% drop in absolute performance)
Another interesting aspect is the release of an 8 billion parameter model. Previously, in their Qwen 3 refreshes, they had neglected to update their 8 billion parameter model along with a couple others. But now with this release, they have updated the post-training of their 8 billion parameter model and also added vision capabilities to it, which is good to see since the eight billion parameter size is ideal for small at-home GPU deployments.
Veo 3.1
Google has released a new version of their already very strong Veo 3 model.
For this version, they have greatly improved the image to text performance and ability to do proper video creations for the likes of tv shows or movies. For instance you can upload an image of a location, and then ask the model to generate video of a helicopter flying over it.
The usual benchmarks have yet to release scores for the model, but from what I have been seeing, it looks to be near the top for image to video generation.
Research
New Long Context Benchmarks
Long context is usually very hard for models. Only with some of the recent frontier releases like GPT-5 have models been able to even remotely use their full context window.
The “hardest” long context benchmarks only tested to see how good a model is at retrieving information from its context; none of the benchmarks made the model to anything complex with this information.
We now have a new benchmark that looks to fill this gap. LongCodeEdit is a benchmark that looks to measure an LLM’s ability to find, diagnose and fix bugs across a large file.
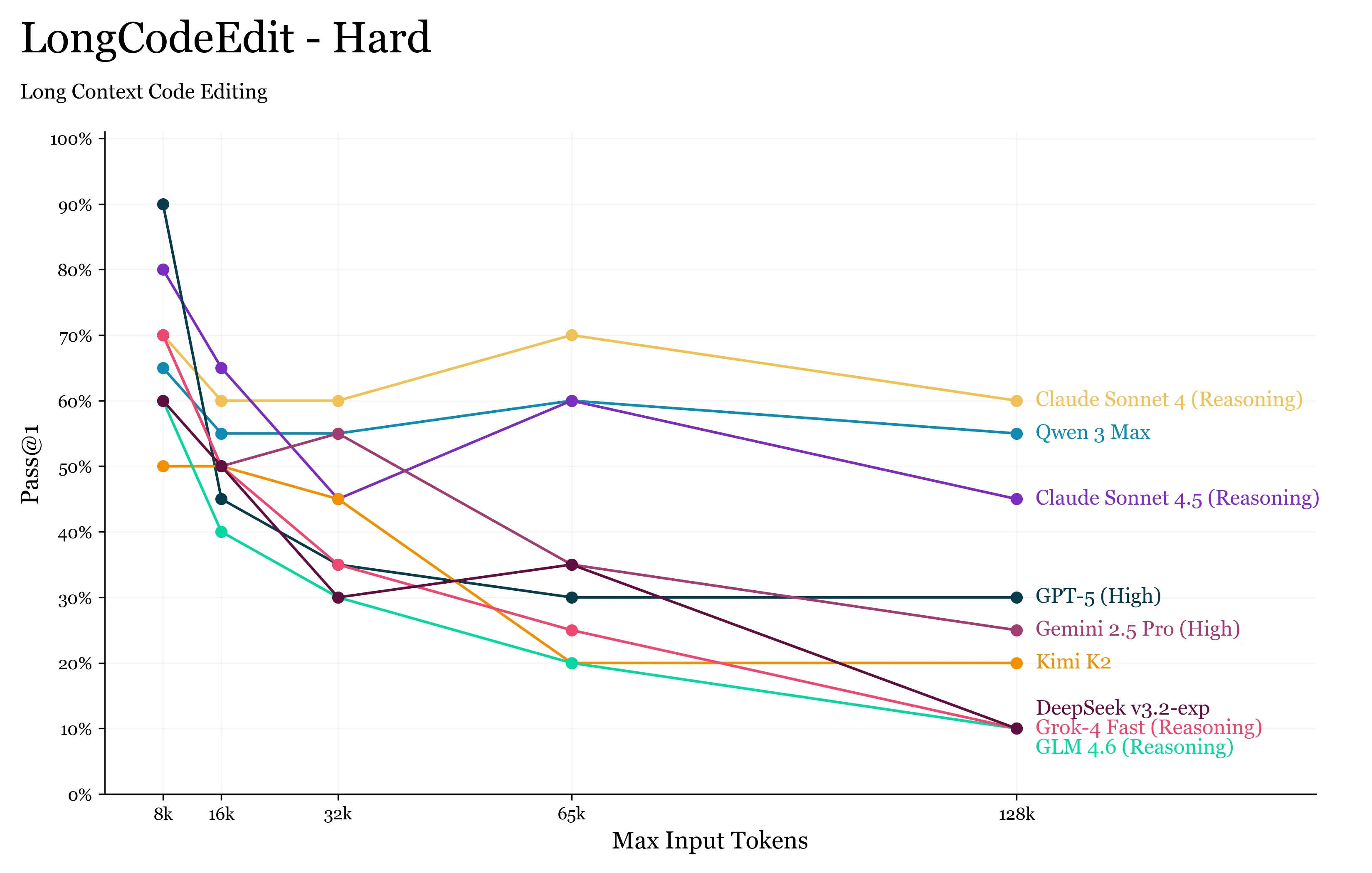
What we find is more of the same from the previous long context benchmarks: that LLM’s are remarkably bad at using their reported context window, as even at 16k tokens we see non-trivial performance degradation on the tasks.
The benchmark takes a number of working functions from existing code benchmarks, corrupts a single one of them, and then passes all of them together into a single “file” to the LLM.
Surprisingly, we find that GPT-5 degrades significantly, while Sonnet 4 and 4.5 are able to roughly maintain their capabilities. Also of note is the Qwen team being number 2, with their flagship Qwen3 Max model.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Stay Updated
Subscribe to get the latest AI news in your inbox every week!