PICK YOUR SUPPORT STYLE
MONTHLY SUPPORT
Reader
$5/mo
Contributor
$15/mo
Architect
$50/mo
Recurring subscriptions auto-bill monthly via Stripe Checkout. Cancel anytime from the receipt email.
Chinese Labs Go Public
Z.ai and Minimax are now publicly traded companies, Liquid AI releases a new flagship (small) LLM, and Anthropic tells us how to do agent evals right
tl;dr
- Z.ai and Minimax are now publicly traded companies
- Liquid AI releases a new flagship (small) LLM
- Anthropic tells us how to do agent evals right
News
Chinese AI labs go public
In the quest for more funding to train their LLMs, two large Chinese labs have gone public this week.
The first is Z.ai, known for their GLM series of models. Their most recent model, GLM 4.7 is a very strong agentic model, around Sonnet 4.5 quality, while being 7 times cheaper, and fully open source.
The other is MiniMax, known for their slightly smaller flagship model MiniMax M2.1. This model is around the same quality as GLM 4.7, while being half the total parameters.
Both companies are listed on the Hong Kong Stock Exchange, which you can trade through most brokers if you live in the US.
They both had strong first days, with Z.ai gaining 32% in the first 2 days of trading reaching a market cap of almost $9 billion USD, and Minimax more than doubling in its first day, ending on a valuation of $13.5 billion USD.
Of note, on the Hong Kong Stock Exchange, you need to buy a minimum of 100 shares, which equates to about $2k USD for Z.ai and $4500 for MiniMax.
Releases
LFM 2.5
Liquid AI has unveiled their new series of small foundation models meant for on-device deployment.
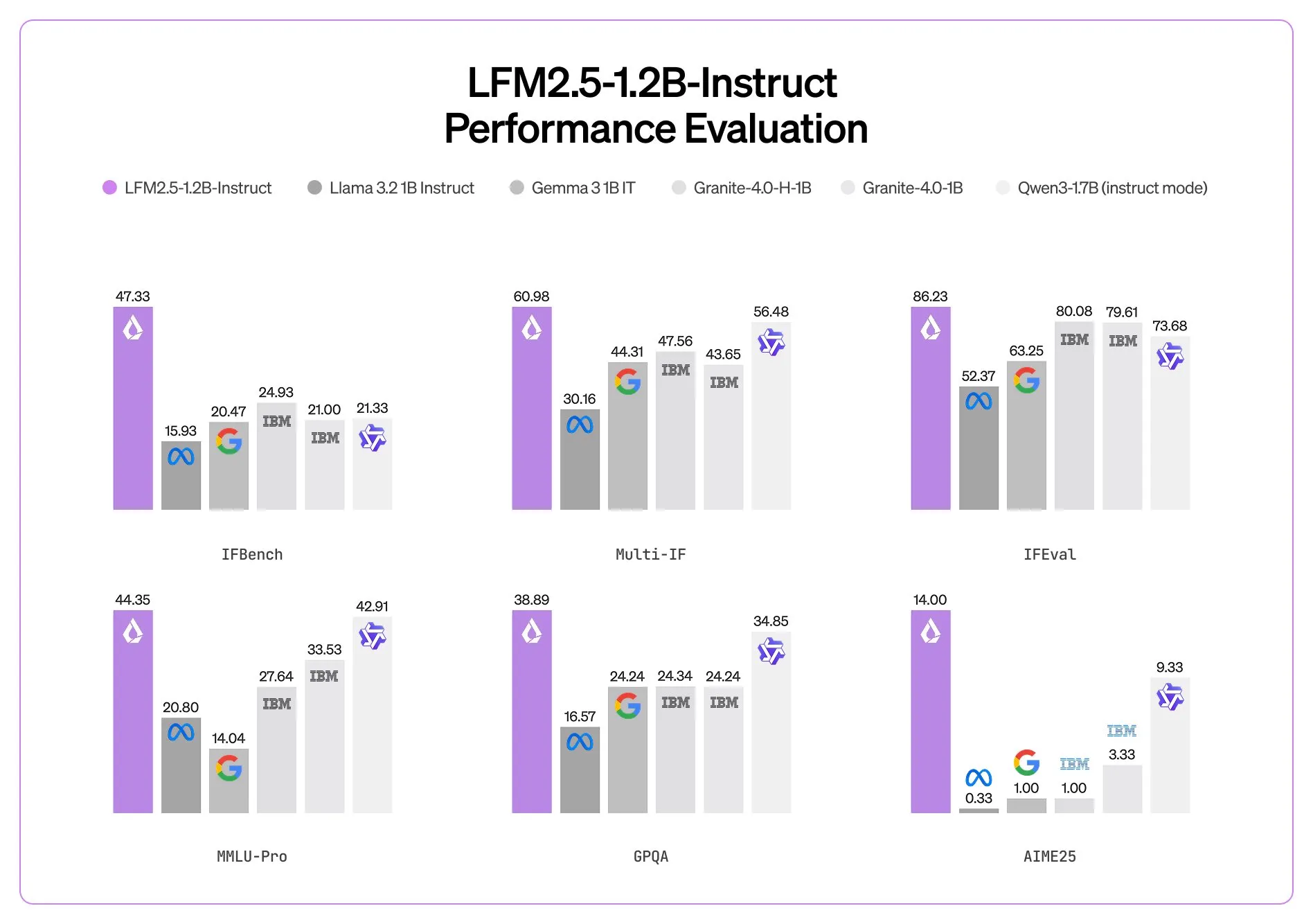
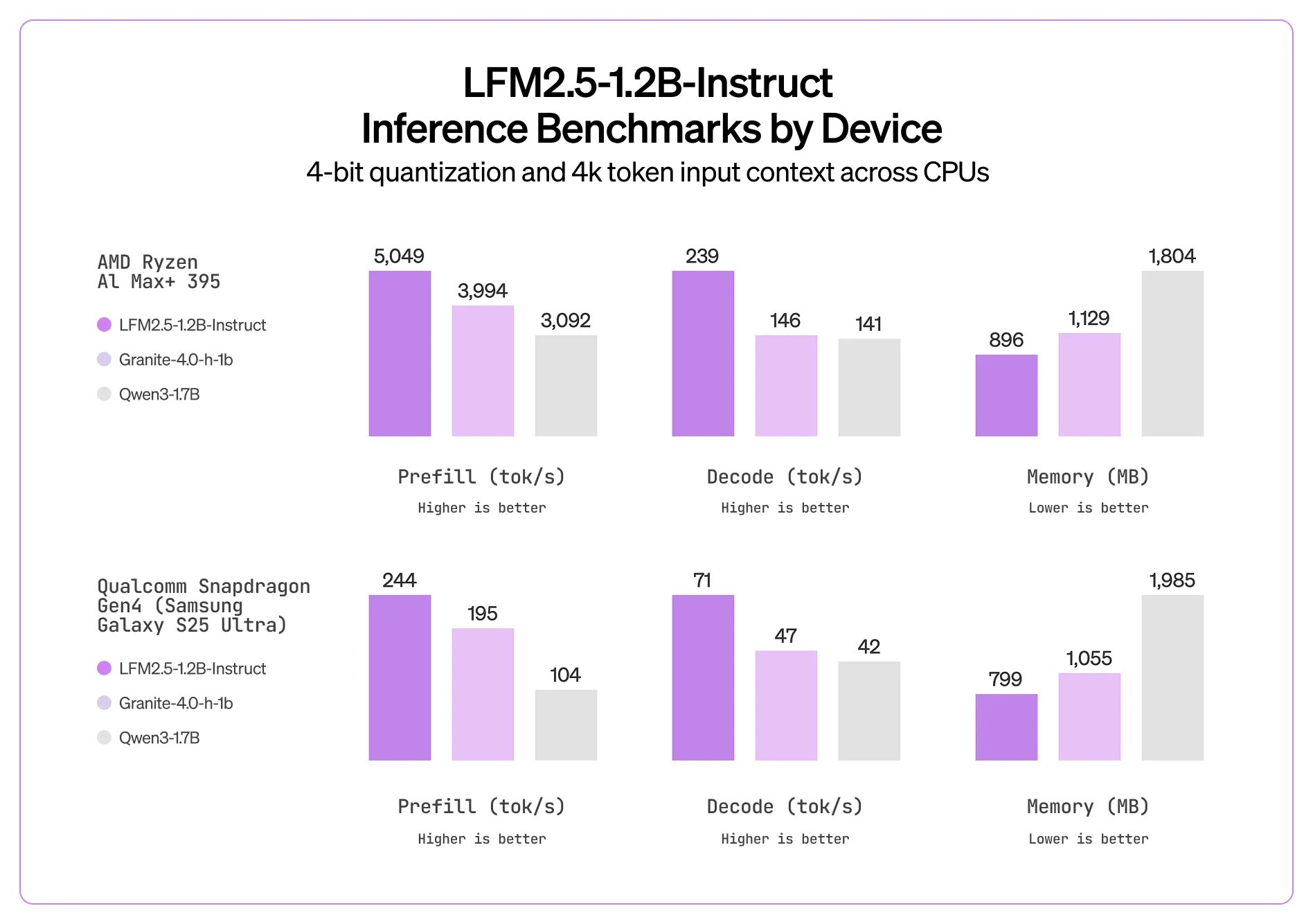
The first model that they have unveiled is the LFM 2.5 1.2B instruct model. Like their previous LFM models, it utilizes an efficient transformer architecture, using both regular transformer layers and also Mamba linear attention layers. This makes the model up to 2x faster than the similar sized Qwen3 1.7B model.
In terms of real world quality, I have heard nothing but good things so far from the community. It punches above its weight in terms of quality and can be deployed anywhere. When using it yourself, know that it will excel at basic agent tasks (web search), data extraction, and RAG; basically any task where instructing following is needed based on its context window. It will however fail when it comes to knowledge intensive tasks (world knowledge in LLMs is directly correlated to number of parameters, and this model doesn’t have many of those) and also coding tasks.
Quick Hits
How Anthropic does agent evals
As you use more and more agents in your day to day life and start deploying them to production, evaluating them becomes a critical task. To help with this, Anthropic has released an in-depth post going over everything you need to consider when making an agent eval. It goes over what the eval space looks like, how to design a high quality eval, and what pitfalls you should avoid.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Stay Updated
Subscribe to get the latest AI news in your inbox every week!