Research
Slop Code Bench
I have been looking for a good benchmark that shows what happens to codebases when building them with vibe coding and I have finally found one, called Slop Code Bench.
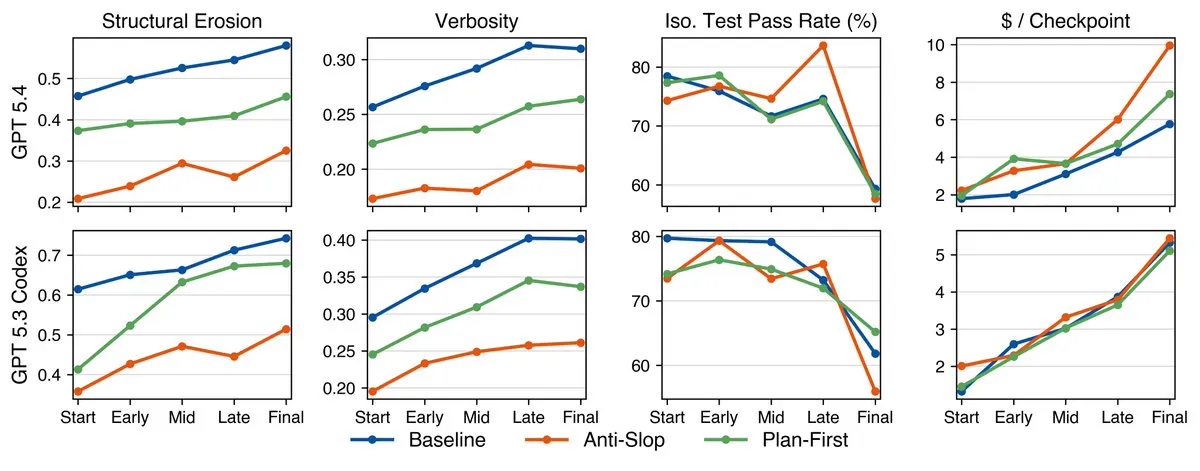
OpenAI model performance (GPT 5.4 and 5.3 Codex)
They find that across all metrics that they measured, across 20 codebases with up to 8 (sequential) tasks, coding performance decreases.
This decrease in quality can be measured in terms of code structure, verbosity, test pass rate, and cost.
They also were testing models in their “natural habitats”, ie Claude Code or the Codex CLI, and also tried different prompting techniques, including instruction on how to prevent sloppy code or adding in a planning phase at the start as well.
These prompting techniques were able to make the code better at the start, but they still did not stop the decrease in code quality as more and more features were added by the AI.
I hope to see this benchmark expand even more and be updated with new models, and if they do you will be seeing me reference it when new models are released.
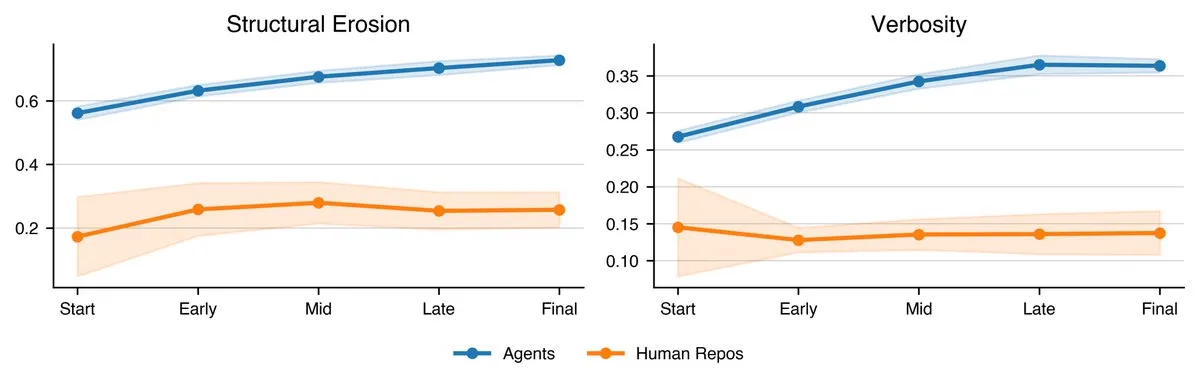
Human made answers do not have the same degradation over time that we see with LLMs
Quick Hits
GitHub trains on your data
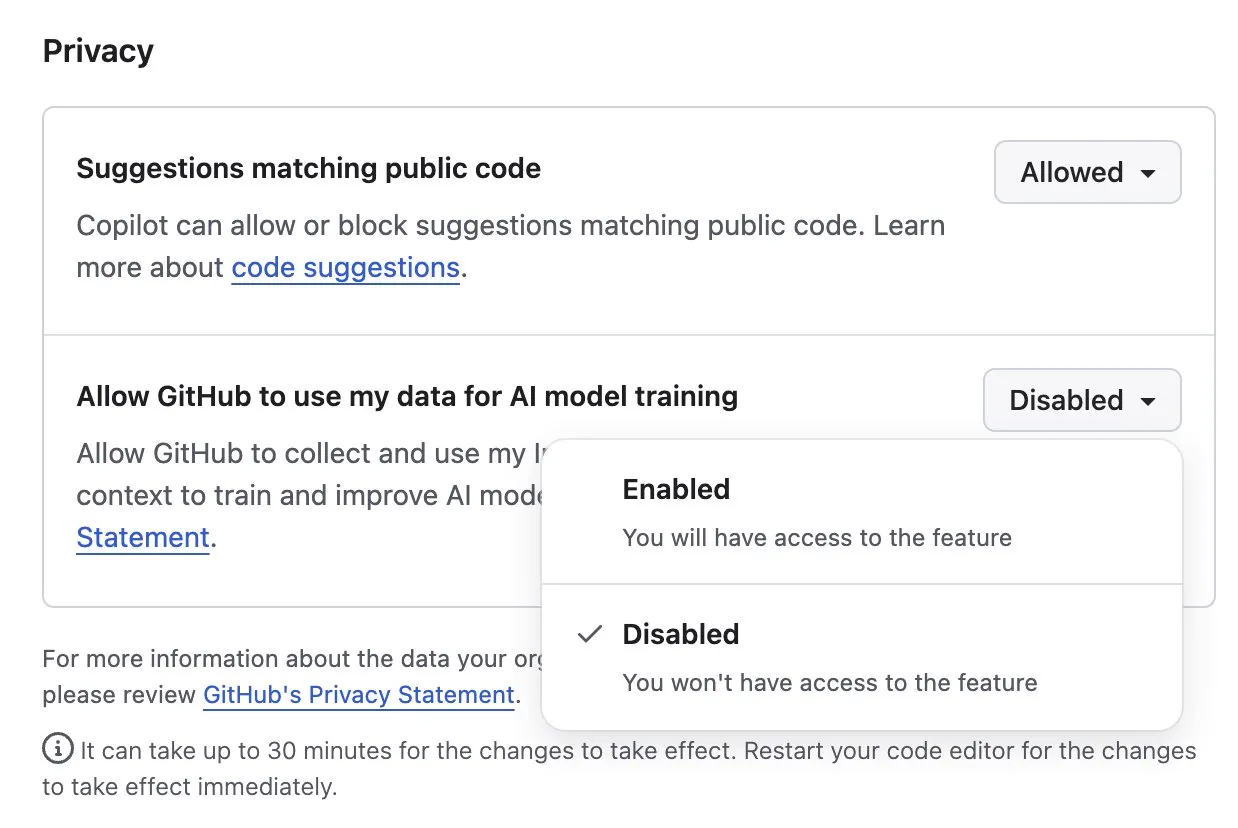
A PSA for those that use GitHub: by default they use your repo data to train their models with.
To turn it off, go to Settings > Copilot > Features > Privacy and set Allow GitHub to use my data for AI model training to disabled.
Finish
It was a quiet week for AI news.
I hope you enjoyed and can spend the extra time catching up with previous releases.
If you want to get the news every week, be sure to join our mailing list below.

caterpillar(?) by Neda on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Pesquisa
Slop Code Bench
Eu estava procurando um bom benchmark que mostrasse o que acontece com bases de código quando construídas com vibe coding e finalmente encontrei um, chamado Slop Code Bench.
Desempenho dos modelos OpenAI (GPT 5.4 e 5.3 Codex)
Eles descobriram que, em todas as métricas medidas, em 20 bases de código com até 8 tarefas (sequenciais), o desempenho de programação diminui.
Essa queda na qualidade pode ser medida em termos de estrutura de código, verbosidade, taxa de aprovação em testes e custo.
Eles também estavam testando os modelos em seus “habitats naturais”, ou seja, Claude Code ou o Codex CLI, e também experimentaram diferentes técnicas de prompting, incluindo instruções sobre como evitar código desleixado ou a adição de uma fase de planejamento no início.
Essas técnicas de prompting conseguiram melhorar o código no início, mas ainda assim não impediram a queda na qualidade do código à medida que mais e mais funcionalidades eram adicionadas pela IA.
Espero ver esse benchmark se expandir ainda mais e ser atualizado com novos modelos, e se isso acontecer, você certamente me verá referenciando-o quando novos modelos forem lançados.
Respostas feitas por humanos não apresentam a mesma degradação ao longo do tempo que vemos com os LLMs
Destaques Rápidos
Um aviso importante para quem usa o GitHub: por padrão, eles utilizam os dados do seu repositório para treinar seus modelos.
Para desativar isso, acesse Configurações > Copilot > Recursos > Privacidade e defina Permitir que o GitHub use meus dados para treinamento de modelos de IA como desativado.
Conclusão
Foi uma semana tranquila para as novidades em IA.
Espero que você tenha gostado e possa aproveitar o tempo extra para se atualizar com os lançamentos anteriores.
Se quiser receber as novidades toda semana, não deixe de se inscrever em nossa lista de e-mails abaixo.
unearth por pale kirill no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Investigación
Slop Code Bench
He estado buscando un buen benchmark que muestre qué le ocurre a las bases de código cuando se construyen con vibe coding y finalmente he encontrado uno, llamado Slop Code Bench.
Rendimiento de los modelos de OpenAI (GPT 5.4 y 5.3 Codex)
Descubren que en todas las métricas que midieron, a lo largo de 20 bases de código con hasta 8 tareas (secuenciales), el rendimiento de programación disminuye.
Esta disminución en la calidad puede medirse en términos de estructura del código, verbosidad, tasa de superación de pruebas y coste.
También probaron los modelos en sus “hábitats naturales”, es decir, Claude Code o el Codex CLI, y además experimentaron con diferentes técnicas de prompting, incluyendo instrucciones sobre cómo prevenir código descuidado o añadir una fase de planificación al inicio.
Estas técnicas de prompting lograron mejorar el código al principio, pero aun así no detuvieron la disminución en la calidad del código a medida que la IA añadía más y más funcionalidades.
Espero ver este benchmark expandirse aún más y actualizarse con nuevos modelos, y si eso ocurre, lo verán referenciado aquí cuando se lancen nuevos modelos.
Las respuestas hechas por humanos no presentan la misma degradación a lo largo del tiempo que vemos con los LLMs
Noticias Breves
GitHub entrena con tus datos
Un aviso importante para quienes usan GitHub: de forma predeterminada, utilizan los datos de tu repositorio para entrenar sus modelos.
Para desactivarlo, ve a Configuración > Copilot > Características > Privacidad y establece Permitir que GitHub use mis datos para el entrenamiento de modelos de IA en desactivado.
Cierre
Fue una semana tranquila en noticias sobre IA.
Espero que lo hayas disfrutado y puedas aprovechar el tiempo extra para ponerte al día con entregas anteriores.
Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
unearth por pale kirill en Twitter