Releases
Multimodal embedding models
Embedding models allow us to compare the “vibe” of two pieces of content, which is useful in contexts where you don’t know the specific keywords you are looking for when searching for a document.
Historically, good embedding models only acted upon one modality, like text or image, but did not interoperate between them.
A multimodal embedding model could, in theory, allow us to upload an image of a flower, and allow you to find a poem about flowers, a video explaining how to take care of flowers, or a podcast talking about the best smelling flowers from your database.
Gemini Embedding 2
Gemini started the week with their Gemini Embedding 2 model.
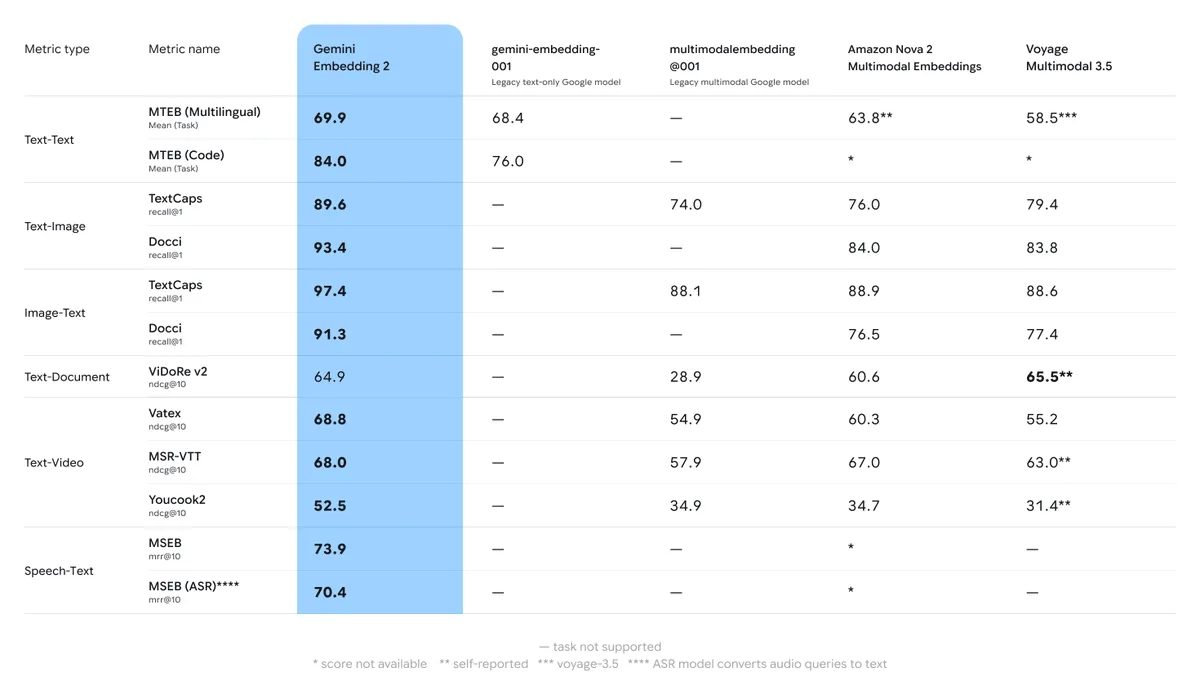
Despite only comparing against other multimodal embedding models, it also does extremely well against the domain specific ones as well, being in the top 5 when compared against the current best text only open source models.
Like we said at the start, there are very few multimodal embedding models to compare against, so they easily take the top spot for all other categories.
MixedBread WholeEmbed V3
Within two days Google had some competition, with search startup MixedBread AI (great company name) releasing the WholeEmbed V3 model.
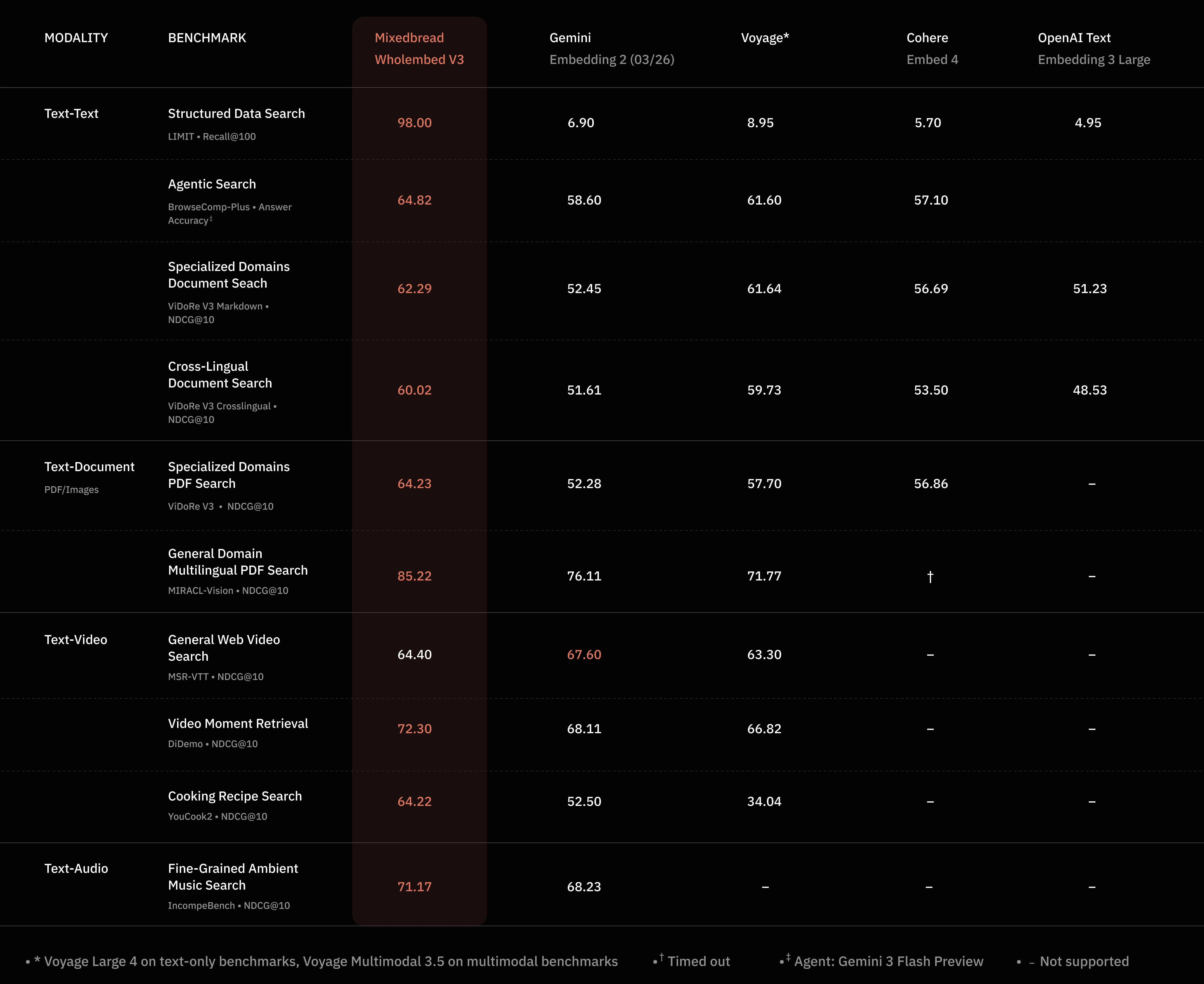
I would say its better, but they seem to use a lot of benchmarks that Google didn’t. It could be a different focus for what the model is good at, or handpicking datasets where they look good.
It seems to be better for many use cases than Google’s model, but that does not mean they are necessarily the same.
Google’s endpoint is a traditional one: you give it your content and it returns a vector (an array of numbers like [1.12, 2.97, -3.2, 0.49]) which you can then use with any vector database that you like.
MixedBread on the other hand do not give you back a vector. They maintain the search engine themselves, so you just upload data into and then can query it. This is nice if you want a fully managed solution, but lacks the flexibility that Google gives you.
They also are (probably) using a late interaction embedding model, which means that search latencies will be high as well.
Quick Hits
Research paper tiktok
There are hundreds of AI research papers that get released every week, making keeping up with all of them a full time job.
To help combat this, Alphaxiv has released a TikTok style app called Briefs that shows you relevant papers with summaries (one paragraph, and one page).

Claude 1 million context
Anthropic has had 1 million context window limits in a beta mode for the last few months.
This week they decided they were happy with what they were seeing and decided to move it out of beta and make it generally available.
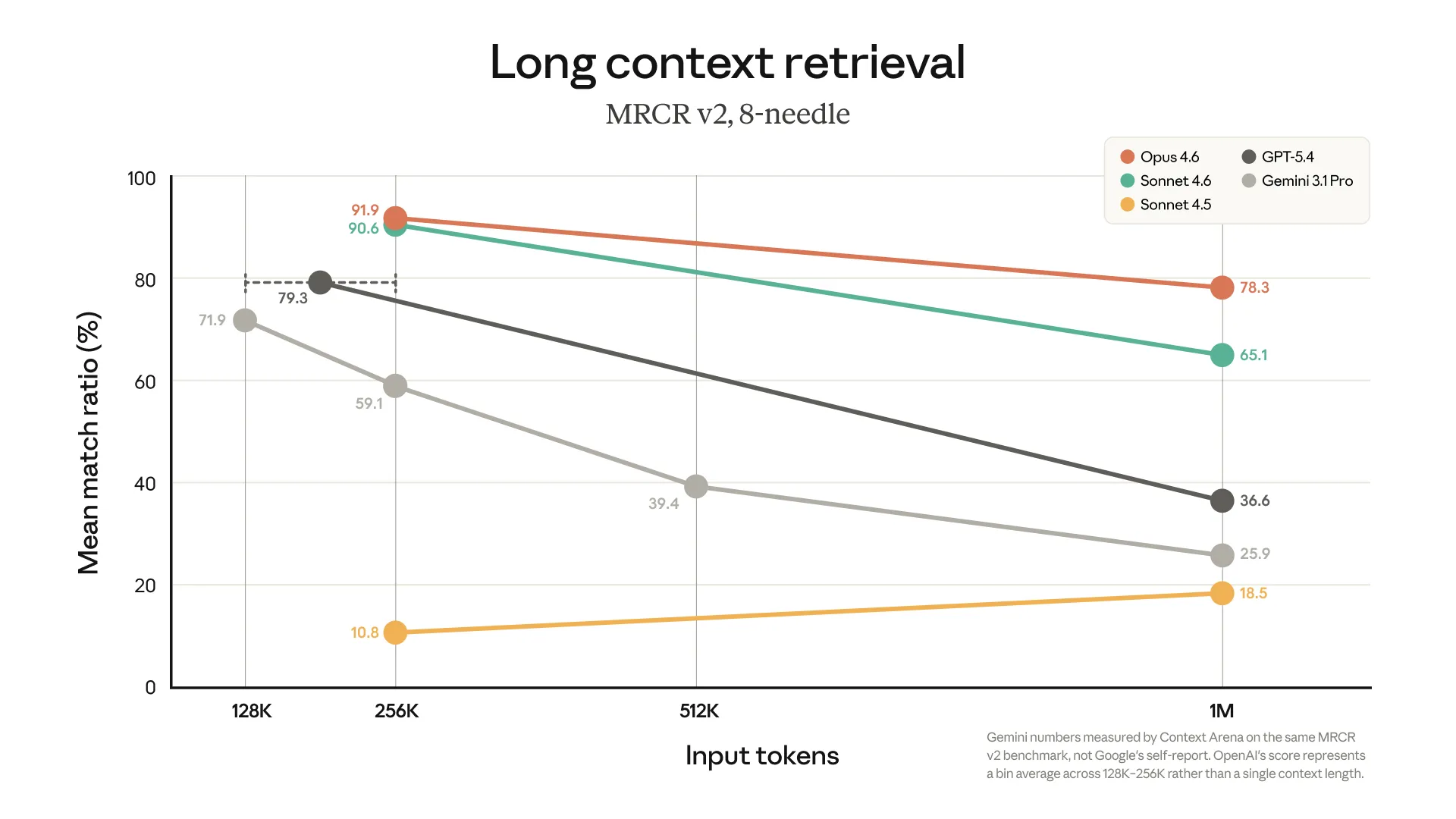
Based on their benchmarks (needle in the haystack style retrieval), they outclass both Gemini and GPT at long context tasks.
They also have strayed away from increasing prices for long contexts; OpenAI and Google both charge double for tokens over 256K, but Anthropic have either found a way to keep prices down or are just willing to eat the extra cost to show up the other labs.
Either way, the consumers win.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Not now, she’s clauding — From proxima centauri b on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Modelos de embedding multimodal
Modelos de embedding nos permitem comparar a “vibe” de dois conteúdos, o que é útil em contextos onde você não conhece as palavras-chave específicas que está buscando ao procurar um documento.
Historicamente, bons modelos de embedding atuavam apenas em uma modalidade, como texto ou imagem, mas não interoperavam entre elas.
Um modelo de embedding multimodal poderia, em teoria, nos permitir fazer upload de uma imagem de uma flor e encontrar um poema sobre flores, um vídeo explicando como cuidar de flores, ou um podcast falando sobre as flores com melhor cheiro em seu banco de dados.
Gemini Embedding 2
O Gemini iniciou a semana com seu modelo Gemini Embedding 2.
Apesar de comparar apenas com outros modelos de embedding multimodal, ele também se sai extremamente bem em relação aos modelos específicos de domínio, ficando no top 5 quando comparado aos melhores modelos open source somente de texto.
Como dissemos no início, há pouquíssimos modelos de embedding multimodal para comparar, então eles facilmente assumem o primeiro lugar em todas as outras categorias.
MixedBread WholeEmbed V3
Em dois dias, o Google teve concorrência, com a startup de busca MixedBread AI (ótimo nome de empresa) lançando o modelo WholeEmbed V3.
Eu diria que é melhor, mas eles parecem usar muitos benchmarks que o Google não usou. Pode ser um foco diferente no que o modelo é bom, ou uma seleção cuidadosa de datasets onde eles se destacam.
Parece ser melhor para muitos casos de uso do que o modelo do Google, mas isso não significa que sejam necessariamente iguais.
O endpoint do Google é tradicional: você fornece seu conteúdo e ele retorna um vetor (um array de números como [1.12, 2.97, -3.2, 0.49]) que você pode usar com qualquer banco de dados vetorial de sua preferência.
O MixedBread, por outro lado, não devolve um vetor. Eles mantêm o motor de busca por conta própria, então você apenas faz upload dos dados e pode consultá-los. Isso é conveniente se você deseja uma solução totalmente gerenciada, mas falta a flexibilidade que o Google oferece.
Eles também (provavelmente) utilizam um modelo de embedding de interação tardia, o que significa que as latências de busca também serão elevadas.
Destaques Rápidos
TikTok de artigos de pesquisa
Centenas de artigos de pesquisa em IA são publicados toda semana, tornando o acompanhamento de todos eles um trabalho de tempo integral.
Para ajudar a combater isso, o Alphaxiv lançou um aplicativo estilo TikTok chamado Briefs que exibe artigos relevantes com resumos (um parágrafo e uma página).
Claude com contexto de 1 milhão
A Anthropic manteve limites de janela de contexto de 1 milhão em modo beta pelos últimos meses.
Esta semana, eles decidiram que estavam satisfeitos com o que estavam vendo e optaram por tirá-lo do beta, tornando-o geralmente disponível.
Com base em seus benchmarks (recuperação estilo agulha no palheiro), eles superam tanto o Gemini quanto o GPT em tarefas de longo contexto.
Eles também se afastaram do aumento de preços para contextos longos; OpenAI e Google cobram o dobro por tokens acima de 256K, mas a Anthropic encontrou uma forma de manter os preços baixos ou simplesmente está disposta a arcar com o custo extra para se destacar frente aos outros laboratórios.
De qualquer forma, quem ganha são os consumidores.
Conclusão
Espero que você tenha gostado das novidades desta semana. Se quiser receber as notícias toda semana, não se esqueça de se inscrever em nossa lista de e-mails abaixo.
Agora não, ela está claudando — De proxima centauri b no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Modelos de embedding multimodal
Los modelos de embedding nos permiten comparar la “vibra” de dos piezas de contenido, lo cual es útil en contextos donde no conoces las palabras clave específicas que buscas al buscar un documento.
Históricamente, los buenos modelos de embedding solo operaban sobre una modalidad, como texto o imagen, pero no interoperaban entre ellas.
Un modelo de embedding multimodal podría, en teoría, permitirnos subir una imagen de una flor y encontrar un poema sobre flores, un video que explique cómo cuidar flores, o un podcast que hable sobre las flores con mejor aroma en tu base de datos.
Gemini Embedding 2
Gemini comenzó la semana con su modelo Gemini Embedding 2.
A pesar de compararse únicamente contra otros modelos de embedding multimodal, también se desempeña extremadamente bien frente a los modelos específicos de dominio, quedando en el top 5 al compararse con los mejores modelos actuales de código abierto solo de texto.
Como dijimos al principio, hay muy pocos modelos de embedding multimodal con los que compararse, por lo que fácilmente toman el primer lugar en todas las demás categorías.
MixedBread WholeEmbed V3
En menos de dos días Google ya tenía competencia, cuando la startup de búsqueda MixedBread AI (excelente nombre de empresa) lanzó el modelo WholeEmbed V3.
Diría que es mejor, pero parece que usan muchos benchmarks que Google no utilizó. Podría ser un enfoque diferente en lo que el modelo es bueno, o una selección cuidadosa de conjuntos de datos donde se ven favorecidos.
Parece ser mejor que el modelo de Google en muchos casos de uso, pero eso no significa que sean necesariamente equivalentes.
El endpoint de Google es uno tradicional: le das tu contenido y te devuelve un vector (un arreglo de números como [1.12, 2.97, -3.2, 0.49]) que puedes usar con cualquier base de datos vectorial que prefieras.
MixedBread, por otro lado, no te devuelve un vector. Ellos mantienen el motor de búsqueda por su cuenta, así que simplemente subes los datos y luego puedes consultarlos. Esto es conveniente si quieres una solución completamente administrada, pero carece de la flexibilidad que te ofrece Google.
Además, (probablemente) están usando un modelo de embedding de interacción tardía, lo que significa que las latencias de búsqueda también serán altas.
Noticias Rápidas
TikTok de papers de investigación
Se publican cientos de papers de investigación en IA cada semana, lo que hace que mantenerse al día con todos ellos sea un trabajo de tiempo completo.
Para ayudar a combatir esto, Alphaxiv ha lanzado una aplicación estilo TikTok llamada Briefs que te muestra papers relevantes con resúmenes (de un párrafo y de una página).
Claude con 1 millón de contexto
Anthropic ha tenido límites de ventana de contexto de 1 millón en modo beta durante los últimos meses.
Esta semana decidieron que estaban satisfechos con lo que veían y resolvieron sacarlo de la beta para hacerlo disponible de forma general.
Según sus benchmarks (recuperación estilo aguja en un pajar), superan tanto a Gemini como a GPT en tareas de contexto largo.
También han evitado aumentar los precios para contextos largos; OpenAI y Google cobran el doble por los tokens que superan los 256K, pero Anthropic o bien ha encontrado la forma de mantener los precios bajos o simplemente está dispuesto a absorber el costo adicional para destacar frente a los otros laboratorios.
De cualquier manera, los consumidores ganan.
Cierre
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Ahorita no, está claudeando — De proxima centauri b en Twitter