News
OpenAI enters the browser game
Having agents control your browser for you has been big recently, with products like Browserbase and Perpexity Comet.
OpenAI has decided to dip their toes in the space as well, releasing their own web browser, ChatGPT Atlas.
Atlas operates just like any normal web browser would, except you have a chat sidebar where you can ask ChatGPT to do tasks for you. One of the big selling points is that it keeps track of your browsing history and habits, and is able to build a profile around you to continually improve the more that you use it.
OpenAI also says that they have done extensive red teaming to prevent it from following malicious “hidden” AI instructions on a page. It still is vulnerable to other attacks like clipboard injection since it can’t see the Javascript of the site that is being used.
In terms of quality, it is nothing that we haven’t seen before. It is good at “boring”, well defined, repetitive tasks and struggles in situations where it’s not immediately obvious what it needs to do or if the task requires any aesthetic taste.
Releases
OpenRouter Exacto
Previously Kimi had uncovered that many of the people hosting their open source Kimi K2 model did not have the same quality as their own “correct” implementation.
This lead to OpenRouter (an inference provider aggregator) to dig into this more, and for many of the major models, they have identified which of their providers are the best.

They bundle the best inference providers into a group called the exacto providers. You can use the exacto providers by adding the :exacto keyword to the model name when using a supported model on OpenRouter.
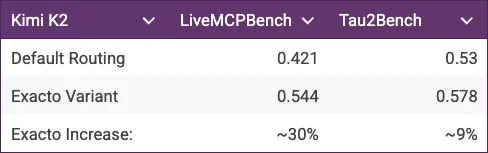
Performance increase by using only exacto providers on OpenRouter
Everyone releases an OCR model
All of the cool kids this week decided to release an open source OCR model.
The types of models fall into 2 distinct categories: interesting, and good.
We will start with the interesting ones first.
On the same day, both DeepSeek and Z.ai, two of the top labs in China, released OCR models that operate fully in pixel space bypassing the need to convert to tokens.
By doing so, they are able to use 3x less input tokens to process the documents.
These models are both very strong, and would be state of the art if it weren’t for the other models also released this week.
Architecturally, I think we will see most models going forward adopt a similar architecture to these two, since it is so much more efficient, and it does not cause any real hit to performance.
It is still to be seen if we can adopt this to more general LLMs as well in the future.
On the good side of things, we have 3 new models that all exceed the previous state of the art level.
The first is Paddle OCR from the Chinese Paddle Paddle team. It was state of the art for a few hours, until Chandra OCR was released.
Chandra OCR is from datalab. The model was previously closed source, its release this week is just the open sourcing of it.
The final model is OlmOCR 2 from AllenAI.
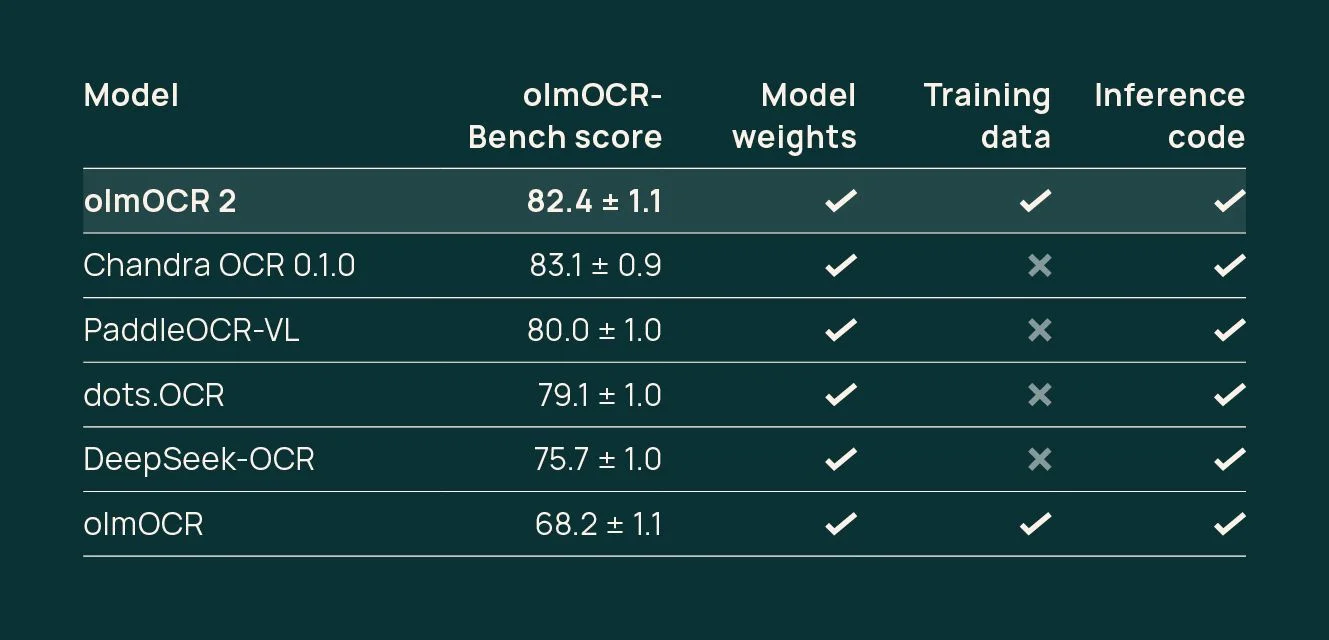
Scores from all the models mentioned — from AllenAI
If you are looking to use the models, Chandra OCR looks like the best based on scores, but it doesn’t tell the whole story.
OlmOCR has comparable scores, and is made to run much faster. This can be seen by the pricing on the companies site for their hosted versions.
Chandra OCR is 10x more expensive per page than OlmOCR 2 ($2 vs $0.20 per thousand pages).
So if you have a large number of documents, I would suggest OlmOCR 2, but if you need the very highest quality and don’t care about how much it costs, then use Chandra OCR.
All of these models are open source as well, so you can run them at home as well.
Quick hits
Claude Code comes to the browser
Similar to OpenAI’s Codex, which has both a web and terminal interface, Claude Code now has the same as well.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Color video of a Tokamok reactor operating — from Tokamak Energy on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Notícias
OpenAI entra no jogo dos navegadores
Ter agentes controlando seu navegador tem sido uma grande tendência recentemente, com produtos como Browserbase e Perpexity Comet.
A OpenAI decidiu entrar nesse espaço também, lançando seu próprio navegador web, ChatGPT Atlas.
O Atlas opera como qualquer navegador web normal, exceto que você tem uma barra lateral de chat onde pode pedir ao ChatGPT para fazer tarefas para você. Um dos grandes diferenciais é que ele mantém registro do seu histórico de navegação e hábitos, e é capaz de construir um perfil sobre você para melhorar continuamente quanto mais você o usa.
A OpenAI também afirma que fizeram testes de segurança extensivos para evitar que ele siga instruções de IA “ocultas” maliciosas em uma página. Ainda é vulnerável a outros ataques como injeção de clipboard, já que não consegue ver o Javascript do site que está sendo usado.
Em termos de qualidade, não é nada que não tenhamos visto antes. É bom em tarefas “chatas”, bem definidas e repetitivas, e tem dificuldades em situações onde não é imediatamente óbvio o que precisa fazer ou se a tarefa requer algum gosto estético.
Lançamentos
OpenRouter Exacto
Anteriormente, a Kimi havia descoberto que muitas das pessoas hospedando seu modelo de código aberto Kimi K2 não tinham a mesma qualidade que sua própria implementação “correta”.
Isso levou o OpenRouter (um agregador de provedores de inferência) a investigar isso mais a fundo, e para muitos dos principais modelos, eles identificaram quais de seus provedores são os melhores.
Eles agrupam os melhores provedores de inferência em um grupo chamado de provedores exacto. Você pode usar os provedores exacto adicionando a palavra-chave :exacto ao nome do modelo ao usar um modelo suportado no OpenRouter.
Aumento de desempenho ao usar apenas provedores exacto no OpenRouter
Todo mundo lança um modelo de OCR
Todos os descolados desta semana decidiram lançar um modelo de OCR de código aberto.
Os tipos de modelos se dividem em 2 categorias distintas: interessantes e bons.
Vamos começar com os interessantes primeiro.
No mesmo dia, tanto a DeepSeek quanto a Z.ai, dois dos principais laboratórios da China, lançaram modelos de OCR que operam totalmente no espaço de pixels, dispensando a necessidade de converter para tokens.
Ao fazer isso, eles conseguem usar 3x menos tokens de entrada para processar os documentos.
Esses modelos são ambos muito fortes, e seriam o estado da arte se não fosse pelos outros modelos também lançados esta semana.
Arquiteturalmente, acho que veremos a maioria dos modelos futuros adotando uma arquitetura similar a esses dois, já que é muito mais eficiente e não causa nenhuma perda real de desempenho.
Ainda está por ver se podemos adotar isso para LLMs mais gerais também no futuro.
Do lado bom das coisas, temos 3 novos modelos que todos excedem o nível anterior do estado da arte.
O primeiro é o Paddle OCR da equipe chinesa Paddle Paddle. Foi estado da arte por algumas horas, até o Chandra OCR ser lançado.
Chandra OCR é da datalab. O modelo era anteriormente de código fechado, seu lançamento esta semana é apenas a abertura do código fonte.
O modelo final é o OlmOCR 2 da AllenAI.
Pontuações de todos os modelos mencionados — da AllenAI
Se você está procurando usar os modelos, o Chandra OCR parece ser o melhor com base nas pontuações, mas isso não conta toda a história.
O OlmOCR tem pontuações comparáveis, e é feito para rodar muito mais rápido. Isso pode ser visto pelo preço no site das empresas para suas versões hospedadas.
O Chandra OCR é 10x mais caro por página do que o OlmOCR 2 ($2 vs $0.20 por mil páginas).
Então, se você tem um grande número de documentos, eu sugeriria o OlmOCR 2, mas se você precisa da mais alta qualidade possível e não se importa com quanto custa, então use o Chandra OCR.
Todos esses modelos são de código aberto também, então você pode rodá-los em casa.
Destaques rápidos
Claude Code chega ao navegador
Similar ao Codex da OpenAI, que tem tanto uma interface web quanto terminal, o Claude Code agora tem o mesmo também.
Fim
Espero que você tenha gostado das notícias desta semana. Se você quer receber as notícias toda semana, certifique-se de entrar na nossa lista de e-mails abaixo.
Vídeo colorido de um reator Tokamak operando — da Tokamak Energy no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
resumen
- OpenAI lanza un navegador
- Se lanzaron cinco modelos de OCR de última generación (todos por diferentes personas)
- OpenRouter lanza benchmarks de proveedores de inferencia
Noticias
OpenAI entra en el juego de los navegadores
Tener agentes que controlen tu navegador por ti ha sido muy popular recientemente, con productos como Browserbase y Perpexity Comet.
OpenAI ha decidido incursionar en este espacio también, lanzando su propio navegador web, ChatGPT Atlas.
Atlas opera como cualquier navegador web normal, excepto que tienes una barra lateral de chat donde puedes pedirle a ChatGPT que haga tareas por ti. Uno de los grandes puntos de venta es que mantiene un registro de tu historial de navegación y hábitos, y es capaz de construir un perfil sobre ti para mejorar continuamente mientras más lo uses.
OpenAI también dice que han hecho un extenso red teaming para evitar que siga instrucciones de IA “ocultas” maliciosas en una página. Todavía es vulnerable a otros ataques como la inyección de portapapeles ya que no puede ver el Javascript del sitio que se está utilizando.
En términos de calidad, no es nada que no hayamos visto antes. Es bueno en tareas “aburridas”, bien definidas y repetitivas, y tiene dificultades en situaciones donde no es inmediatamente obvio lo que necesita hacer o si la tarea requiere algún gusto estético.
Lanzamientos
OpenRouter Exacto
Anteriormente Kimi había descubierto que muchas de las personas que alojaban su modelo de código abierto Kimi K2 no tenían la misma calidad que su propia implementación “correcta”.
Esto llevó a OpenRouter (un agregador de proveedores de inferencia) a profundizar más en esto, y para muchos de los modelos principales, han identificado cuáles de sus proveedores son los mejores.
Agrupan los mejores proveedores de inferencia en un grupo llamado proveedores exacto. Puedes usar los proveedores exacto agregando la palabra clave :exacto al nombre del modelo cuando uses un modelo compatible en OpenRouter.
Aumento de rendimiento al usar solo proveedores exacto en OpenRouter
Todo el mundo lanza un modelo de OCR
Todos los chicos cool de esta semana decidieron lanzar un modelo de OCR de código abierto.
Los tipos de modelos caen en 2 categorías distintas: interesantes y buenos.
Comenzaremos con los interesantes primero.
El mismo día, tanto DeepSeek como Z.ai, dos de los principales laboratorios en China, lanzaron modelos de OCR que operan completamente en el espacio de píxeles, evitando la necesidad de convertir a tokens.
Al hacerlo, pueden usar 3 veces menos tokens de entrada para procesar los documentos.
Estos modelos son muy fuertes, y serían de última generación si no fuera por los otros modelos también lanzados esta semana.
Arquitectónicamente, creo que veremos que la mayoría de los modelos en el futuro adoptarán una arquitectura similar a estos dos, ya que es mucho más eficiente y no causa ningún impacto real en el rendimiento.
Todavía está por verse si podemos adoptar esto también a LLMs más generales en el futuro.
En el lado bueno de las cosas, tenemos 3 nuevos modelos que todos superan el nivel de última generación anterior.
El primero es Paddle OCR del equipo chino Paddle Paddle. Fue de última generación durante unas pocas horas, hasta que se lanzó Chandra OCR.
Chandra OCR es de datalab. El modelo anteriormente era de código cerrado, su lanzamiento esta semana es solo la apertura del código.
El modelo final es OlmOCR 2 de AllenAI.
Puntuaciones de todos los modelos mencionados — de AllenAI
Si estás buscando usar los modelos, Chandra OCR parece ser el mejor basado en las puntuaciones, pero eso no cuenta toda la historia.
OlmOCR tiene puntuaciones comparables, y está hecho para ejecutarse mucho más rápido. Esto se puede ver por los precios en el sitio de las empresas para sus versiones alojadas.
Chandra OCR es 10 veces más caro por página que OlmOCR 2 ($2 vs $0.20 por mil páginas).
Así que si tienes un gran número de documentos, sugeriría OlmOCR 2, pero si necesitas la más alta calidad y no te importa cuánto cuesta, entonces usa Chandra OCR.
Todos estos modelos son de código abierto también, así que puedes ejecutarlos en casa también.
Notas rápidas
Claude Code llega al navegador
Similar a Codex de OpenAI, que tiene tanto una interfaz web como de terminal, Claude Code ahora tiene lo mismo también.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Video a color de un reactor Tokamok operando — de Tokamak Energy en Twitter