Releases
Kimi K2 Thinking
Moonshot AI has released the thinking version of their already strong Kimi K2 model.
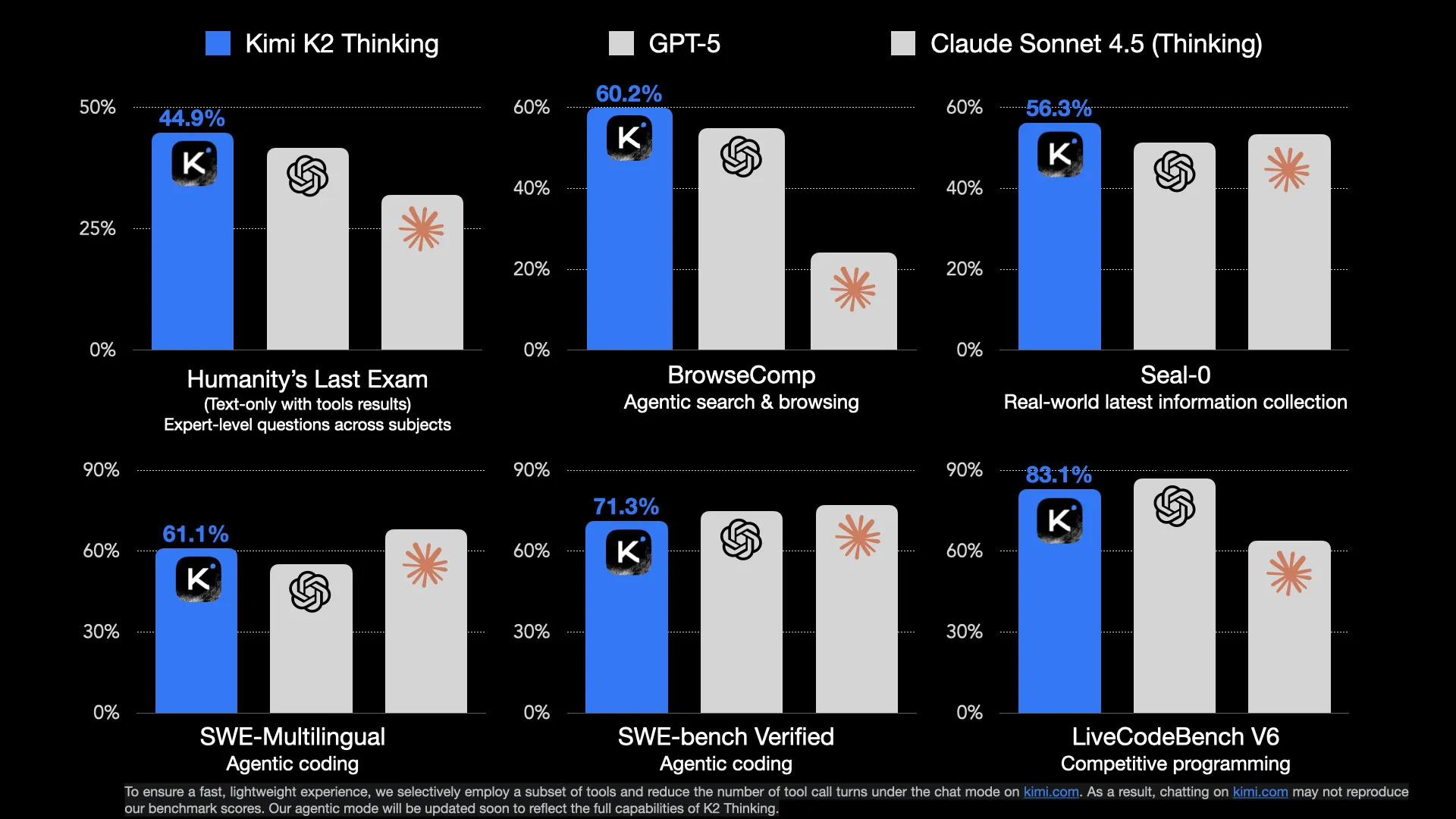
Major respect for only comapring to GPT-5 and Sonnet 4.5, although its easy when your model directly competes and beats them on benchmarks
The model is still the 1 trillion parameter behemomouth mixture of experts model from before with 32B active parameters. The model was trained using quantization aware training to allow it to be deployed at 4 bit without suffering much performance degredation. All benchmarks released by the team are for the INT4 model.
It contiues to be the best model in terms of writing, somehow outdoing its predessor instruct model which was the previous best.
It also continues to be the most unique LLM in terms of personality and general writing style, being drastically different from the slop pretty much every other major LLM has.
This version of the model the Moonshot team really worked on the agentic capabilities of the model, which were lacking in the instruct model. It seems to not necessarily be on the same level as GPT-5 and Sonnet 4.5 for agentic coding, but for more general agent use cases it seems to be able to hold its own.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|
| GLM 4.6 | $0.60 | $2.20 | 90 |
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5 | $1.5 | $10 | 34 |
| Kimi K2 Thinking | $0.6 | $2.50 | 25 |
| Kimi K2 Thinking Turbo | $1.15 | $8 | 107 |
The turbo model is the same as the regular, just hosted on faster hardware. Info from OpenRouter
The main issues with the model are speed and token usage.
The model is cheap, at only $2.50 per million output tokens, but at 25 tokens per second it is slower than even the glacial GPT-5 (those that have used GPT-5 in Codex know what I mean). For agent tasks this is unacceptably slow. You could switch to the Turbo endpoint, but then the price becomes similar to GPT-5, which defeats one of the main purposes of these Chinese models which is that they are very cheap.
Also Kimi K2 Thinking has an issue most other first generation reasoning models have which is extrmely long thinking traces. Specifically, Kimi K2 seems to have the longest chain of thought processes of any reasoning model, as shown by the Artifical Analysis benchmark below.
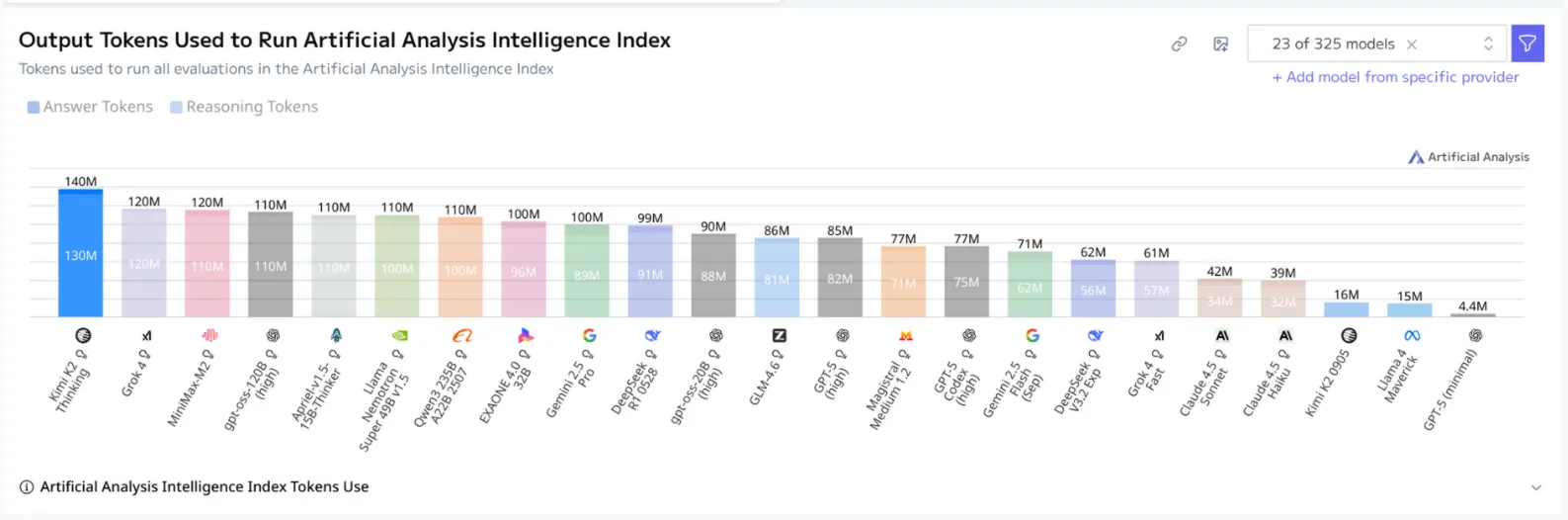
Double the thinking tokens of GPT-5 high, meaning it will feel twice as slow if it were running as the same tokens per second
This is an issue that can be fixed, so I expect the Moonshot team to fix it in the future, but it does make the model even slower to use now.
These are not deal breakers however, because at the end of the day this model is very strong, near or at the frontier of intelligence, all while being open source. I will be daily driving Kimi K2 thinking for the next week or so to see if it can replace GPT-5 for my daily AI questions.
The jagged edge of intelligence makes it so that these frontier models will be seen going back and forth at the top of benchmarks, with no direct clear winner. At the end of the day, it will come down to your specific use case for what model you should be using. I tend to focus on agentic coding, since that’s what I use these models for the most, but your needs may be different. Because of this, I recommend building out your own small evaluation set and using it to test existing and new models that come out, so you can assess whether or not you should switch to it.
Big Llama.cpp updates
The Llama.cpp team has had enough of being known as the unacknowledged backend for subpar tools like Ollama, LMStudio, and Jan, and have rolled out changes to make the library easily accessible for all.
The first change is a revamp of the default UI that is available when running a llama.cpp model.
Previously the UI had been very bare bones and did not save anything for the user.
The revamped UI, very similar to the ChatGPT interface
Now the UI has a much more standard, intuitive, and better looking interface for you to use. It also has chat history and more advanced tools like modifying sampling parameters or having the model follow structured outputs.
One of the long standing issues with Llama cpp has been the difficulty of setting it up, easpecially when compared to tools like Ollama.
This has been fixed now, with the release of LlamaBarn, a Mac menu bar app that allows you to run LLMs with just a single click.
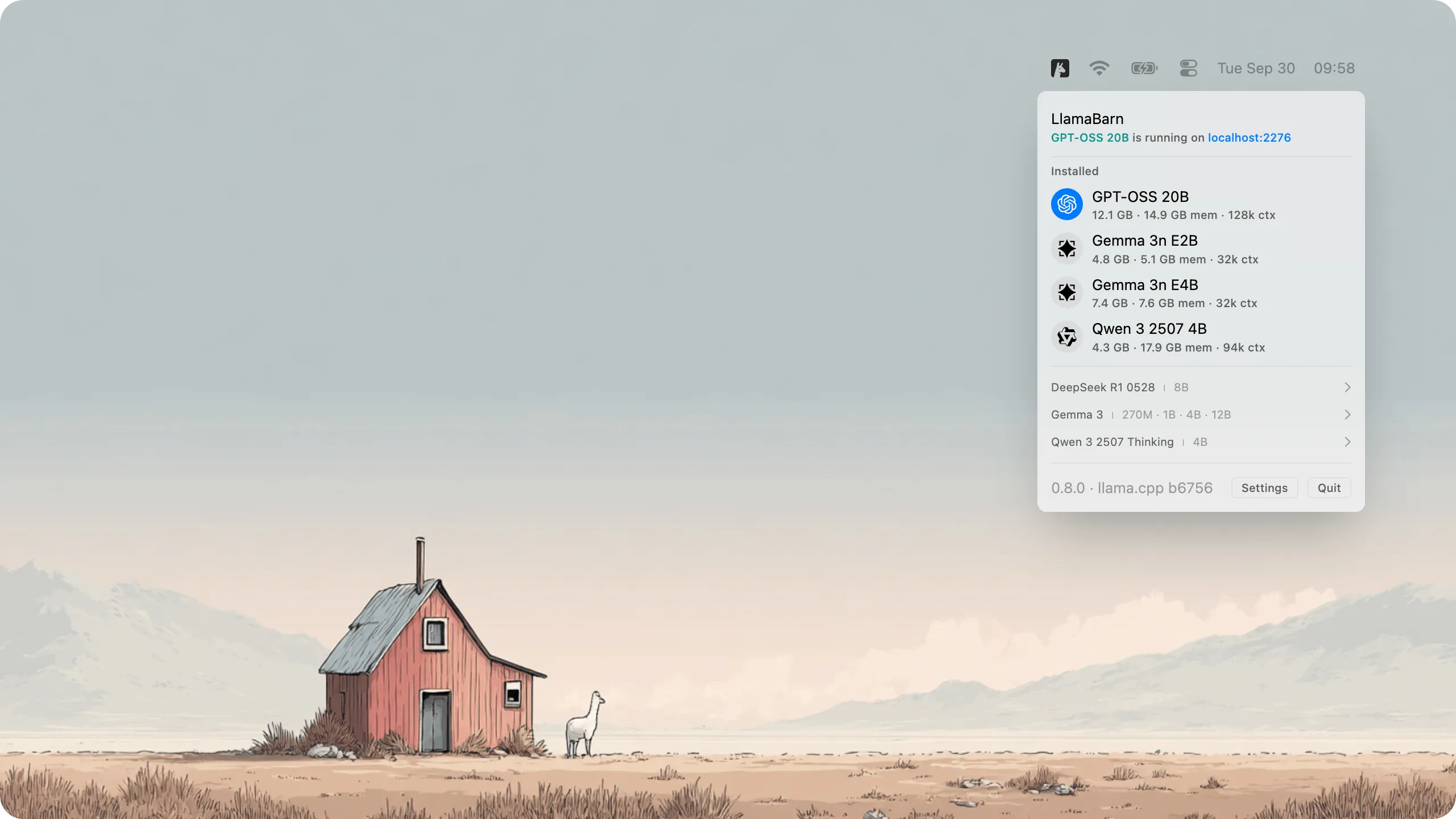
LlamaBarn will automatically handle model download, optimization for your specific hardware, and then the actual running of the model.
It will start a OpenAI API library compatible server for you to use in your code, and also start the new web UI mentioned above.
If you are running models locally on your Mac right now with tools like Ollama, LMStudio, Jan or any others, I would highly recommend switching to Llama.cpp, as it is what all of these other tools are using under the hood.
By using Llama.cpp you will be getting the first party experience of running these models, without any of the bloat or “performance tweaks” that degrade model quality that they other libraries provide.
Quick Hits
OpenAI Codex updates
OpenAI has released some updates to their coding platform Codex, most notably increasing rate limits by 50% and releasing GPT 5 Codex Mini, which uses rate limits half as fast as the regualr Codex model, and is also noticably faster.
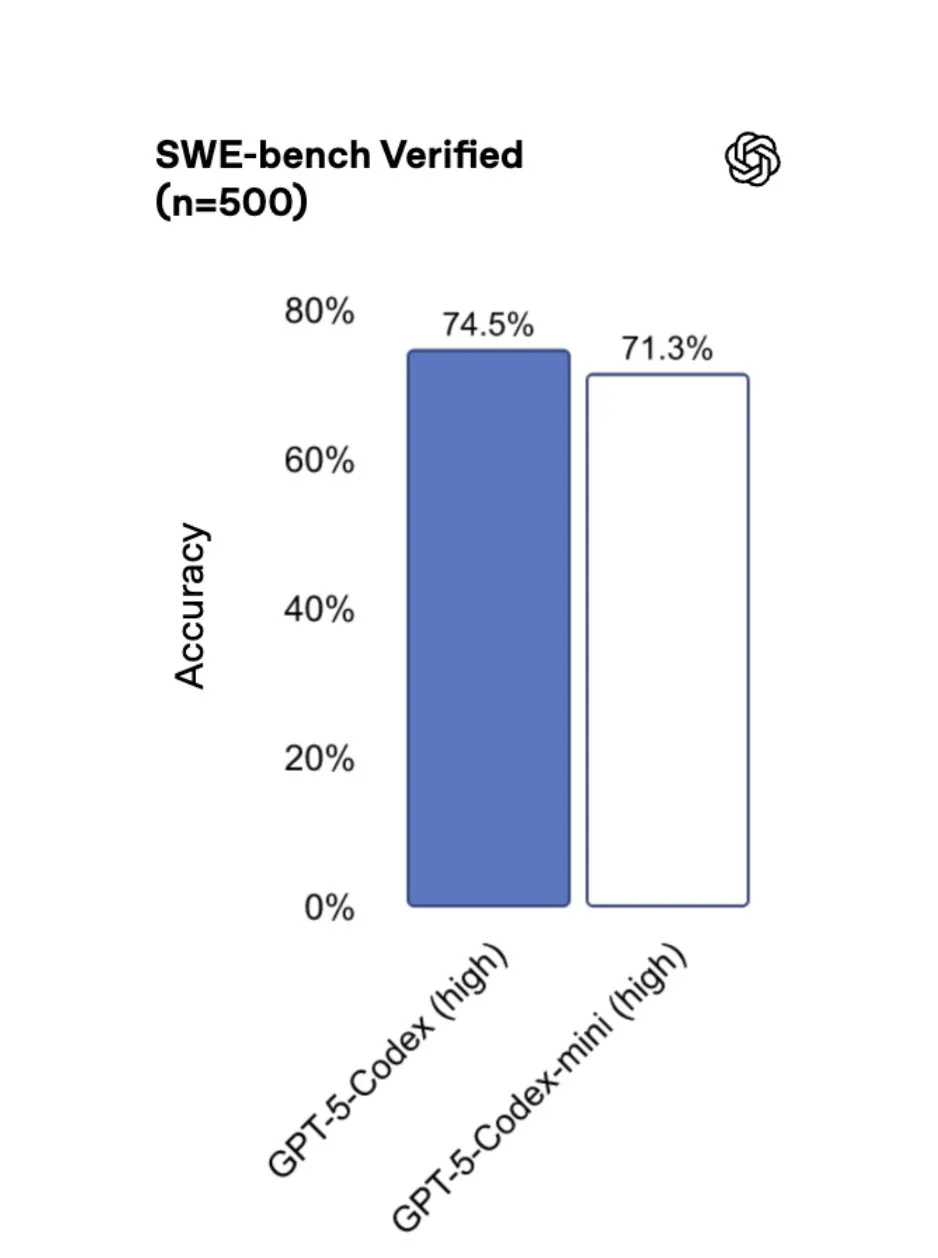
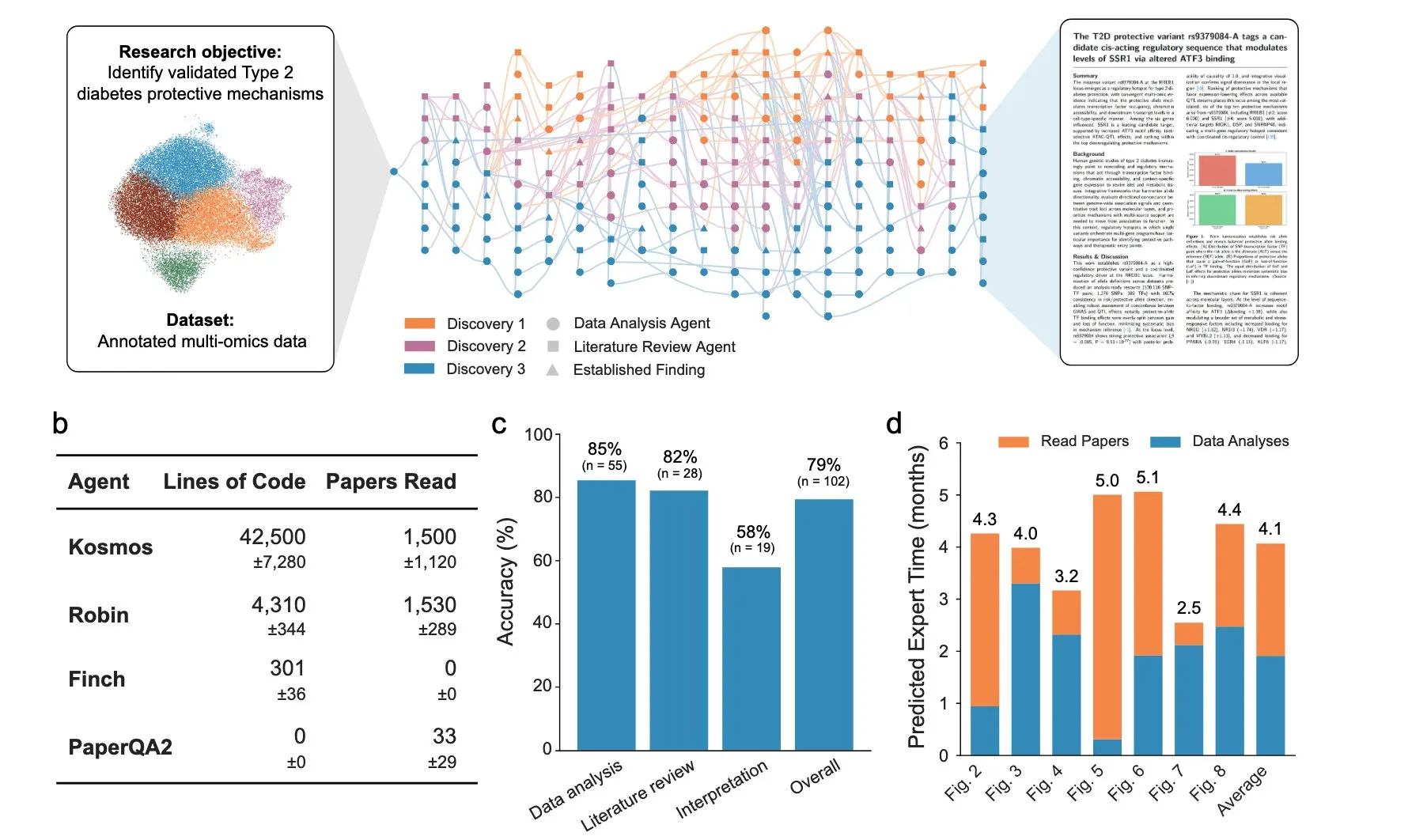
AI Scientist that can work for days
A company called Edison Scientific has come out with an agent system that they say can run for days at a time.
They say it has already written 7 papers on unique, previous unknown/ unexplored topics, and that its success rate is 80%. They also include a paper as well documenting how it works.
You can use it now for free if you have an academic email (you get 3 queries). After that it will cost $200 per run.
ComfyUI cloud
Popular image and video generation platform ComfyUI has released a monthly compute plan that gives users 8 hours of A100 40GB GPU per day for generating images and video.
If you are a power user, startup that has custom workflows that you want to run, or have wanted to use ComfyUI but didn’t have teh compute for it, this is the most cost effective option to use right now.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

Epoch AI released a cool visualization of all the major datacenters being built right now Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Kimi K2 Thinking
Moonshot AI lançou a versão thinking de seu já forte modelo Kimi K2.
Grande respeito por comparar apenas com GPT-5 e Sonnet 4.5, embora seja fácil quando seu modelo compete diretamente e os supera nos benchmarks
O modelo continua sendo o gigantesco mixture of experts de 1 trilhão de parâmetros de antes, com 32B de parâmetros ativos. O modelo foi treinado usando quantization aware training para permitir que seja implantado em 4 bits sem sofrer muita degradação de desempenho. Todos os benchmarks divulgados pela equipe são para o modelo INT4.
Ele continua sendo o melhor modelo em termos de escrita, de alguma forma superando seu predecessor, o modelo instruct, que era o melhor anterior.
Ele também continua sendo o LLM mais único em termos de personalidade e estilo geral de escrita, sendo drasticamente diferente do conteúdo genérico que praticamente todos os outros LLMs importantes têm.
Nesta versão do modelo, a equipe Moonshot realmente trabalhou nas capacidades agênticas do modelo, que eram deficientes no modelo instruct. Parece não estar necessariamente no mesmo nível que GPT-5 e Sonnet 4.5 para codificação agêntica, mas para casos de uso de agentes mais gerais parece ser capaz de se manter competitivo.
| Modelo | $ por milhão (entrada) | $ por milhão (saída) | Tokens por segundo |
|---|
| GLM 4.6 | $0.60 | $2.20 | 90 |
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5 | $1.5 | $10 | 34 |
| Kimi K2 Thinking | $0.6 | $2.50 | 25 |
| Kimi K2 Thinking Turbo | $1.15 | $8 | 107 |
O modelo turbo é o mesmo que o regular, apenas hospedado em hardware mais rápido. Informações do OpenRouter
Os principais problemas com o modelo são velocidade e uso de tokens.
O modelo é barato, custando apenas $2.50 por milhão de tokens de saída, mas a 25 tokens por segundo é mais lento até que o glacial GPT-5 (aqueles que usaram GPT-5 no Codex sabem o que quero dizer). Para tarefas de agentes isso é inaceitavelmente lento. Você poderia mudar para o endpoint Turbo, mas então o preço fica similar ao GPT-5, o que derrota um dos principais propósitos desses modelos chineses, que é serem muito baratos.
Além disso, Kimi K2 Thinking tem um problema que a maioria dos outros modelos de raciocínio de primeira geração têm, que são traces de pensamento extremamente longos. Especificamente, Kimi K2 parece ter os processos de cadeia de pensamento mais longos de qualquer modelo de raciocínio, como mostrado pelo benchmark da Artificial Analysis abaixo.
O dobro dos tokens de pensamento do GPT-5 high, significando que parecerá duas vezes mais lento se estivesse rodando nos mesmos tokens por segundo
Este é um problema que pode ser corrigido, então espero que a equipe Moonshot o corrija no futuro, mas isso torna o modelo ainda mais lento de usar agora.
Estes não são problemas fatais, no entanto, porque no final das contas este modelo é muito forte, próximo ou na fronteira da inteligência, tudo isso sendo de código aberto. Vou usar Kimi K2 thinking diariamente pela próxima semana para ver se ele pode substituir GPT-5 para minhas perguntas diárias de IA.
A fronteira irregular da inteligência faz com que esses modelos de fronteira sejam vistos indo e voltando no topo dos benchmarks, sem um vencedor claro direto. No final das contas, vai depender do seu caso de uso específico para qual modelo você deve usar. Eu tendo a focar em codificação agêntica, já que é para isso que uso esses modelos na maior parte do tempo, mas suas necessidades podem ser diferentes. Por causa disso, recomendo construir seu próprio pequeno conjunto de avaliação e usá-lo para testar modelos existentes e novos que surgirem, para que você possa avaliar se deve ou não mudar para ele.
Grandes atualizações do Llama.cpp
A equipe Llama.cpp se cansou de ser conhecida como o backend não reconhecido para ferramentas inferiores como Ollama, LMStudio e Jan, e lançou mudanças para tornar a biblioteca facilmente acessível para todos.
A primeira mudança é uma reformulação da UI padrão que está disponível ao executar um modelo llama.cpp.
Anteriormente, a UI tinha sido muito básica e não salvava nada para o usuário.
A UI reformulada, muito similar à interface do ChatGPT
Agora a UI tem uma interface muito mais padrão, intuitiva e com melhor aparência para você usar. Ela também tem histórico de chat e ferramentas mais avançadas como modificar parâmetros de amostragem ou fazer o modelo seguir saídas estruturadas.
Um dos problemas de longa data com Llama cpp tem sido a dificuldade de configurá-lo, especialmente quando comparado a ferramentas como Ollama.
Isso foi corrigido agora, com o lançamento do LlamaBarn, um aplicativo de barra de menu para Mac que permite executar LLMs com apenas um único clique.
LlamaBarn irá automaticamente lidar com o download do modelo, otimização para seu hardware específico e então a execução real do modelo.
Ele iniciará um servidor compatível com a biblioteca API OpenAI para você usar em seu código, e também iniciará a nova UI web mencionada acima.
Se você está executando modelos localmente em seu Mac agora com ferramentas como Ollama, LMStudio, Jan ou quaisquer outras, eu recomendaria fortemente mudar para Llama.cpp, pois é o que todas essas outras ferramentas estão usando por baixo dos panos.
Ao usar Llama.cpp você estará obtendo a experiência de primeira mão de executar esses modelos, sem nenhum do inchaço ou “ajustes de desempenho” que degradam a qualidade do modelo que as outras bibliotecas fornecem.
Destaques Rápidos
Atualizações do OpenAI Codex
OpenAI lançou algumas atualizações para sua plataforma de codificação Codex, mais notavelmente aumentando os limites de taxa em 50% e lançando GPT 5 Codex Mini, que usa limites de taxa metade da velocidade do modelo Codex regular, e também é visivelmente mais rápido.
Cientista de IA que pode trabalhar por dias
Uma empresa chamada Edison Scientific lançou um sistema de agentes que eles dizem poder executar por dias a fio.
Eles dizem que já escreveu 7 artigos sobre tópicos únicos, previamente desconhecidos/inexplorados, e que sua taxa de sucesso é de 80%. Eles também incluem um artigo documentando como funciona.
Você pode usá-lo agora gratuitamente se tiver um e-mail acadêmico (você recebe 3 consultas). Depois disso custará $200 por execução.
ComfyUI cloud
A popular plataforma de geração de imagens e vídeos ComfyUI lançou um plano de computação mensal que dá aos usuários 8 horas de GPU A100 40GB por dia para gerar imagens e vídeos.
Se você é um usuário avançado, startup que tem workflows personalizados que deseja executar, ou queria usar ComfyUI mas não tinha a computação necessária para isso, esta é a opção mais econômica para usar agora.
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quer receber as notícias toda semana, certifique-se de se juntar à nossa lista de e-mails abaixo.
Epoch AI lançou uma visualização legal de todos os principais datacenters sendo construídos agora Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Kimi K2 Thinking
Moonshot AI ha lanzado la versión thinking de su ya potente modelo Kimi K2.
Gran respeto por compararse solo con GPT-5 y Sonnet 4.5, aunque es fácil cuando tu modelo compite directamente y los supera en benchmarks
El modelo sigue siendo el gigantesco mixture of experts de 1 billón de parámetros de antes con 32B de parámetros activos. El modelo fue entrenado usando quantization aware training para permitir su implementación en 4 bits sin sufrir mucha degradación de rendimiento. Todos los benchmarks publicados por el equipo son para el modelo INT4.
Continúa siendo el mejor modelo en términos de escritura, superando de alguna manera a su predecesor, el modelo instruct, que era el mejor anterior.
También sigue siendo el LLM más único en términos de personalidad y estilo general de escritura, siendo drásticamente diferente de la mediocridad que tienen prácticamente todos los demás LLM importantes.
En esta versión del modelo, el equipo de Moonshot realmente trabajó en las capacidades agénticas del modelo, que faltaban en el modelo instruct. No parece estar necesariamente al mismo nivel que GPT-5 y Sonnet 4.5 para codificación agéntica, pero para casos de uso de agentes más generales parece poder mantenerse firme.
| Modelo | $ por millón (entrada) | $ por millón (salida) | Tokens por segundo |
|---|
| GLM 4.6 | $0.60 | $2.20 | 90 |
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5 | $1.5 | $10 | 34 |
| Kimi K2 Thinking | $0.6 | $2.50 | 25 |
| Kimi K2 Thinking Turbo | $1.15 | $8 | 107 |
El modelo turbo es el mismo que el regular, solo que alojado en hardware más rápido. Información de OpenRouter
Los principales problemas con el modelo son la velocidad y el uso de tokens.
El modelo es económico, a solo $2.50 por millón de tokens de salida, pero a 25 tokens por segundo es más lento que incluso el glacial GPT-5 (aquellos que han usado GPT-5 en Codex saben a qué me refiero). Para tareas de agentes esto es inaceptablemente lento. Podrías cambiar al endpoint Turbo, pero entonces el precio se vuelve similar al de GPT-5, lo que anula uno de los principales propósitos de estos modelos chinos, que es que son muy baratos.
Además, Kimi K2 Thinking tiene un problema que la mayoría de los modelos de razonamiento de primera generación tienen, que son las trazas de pensamiento extremadamente largas. Específicamente, Kimi K2 parece tener los procesos de cadena de pensamiento más largos de cualquier modelo de razonamiento, como muestra el benchmark de Artifical Analysis a continuación.
El doble de tokens de pensamiento que GPT-5 high, lo que significa que se sentirá el doble de lento si estuviera ejecutándose a los mismos tokens por segundo
Este es un problema que puede solucionarse, así que espero que el equipo de Moonshot lo solucione en el futuro, pero sí hace que el modelo sea aún más lento de usar ahora.
Sin embargo, estos no son obstáculos definitivos, porque al final del día este modelo es muy potente, cerca o en la frontera de la inteligencia, todo mientras es de código abierto. Estaré usando Kimi K2 thinking diariamente durante la próxima semana más o menos para ver si puede reemplazar a GPT-5 para mis preguntas diarias de IA.
El jagged edge of intelligence hace que estos modelos de frontera se vean yendo y viniendo en la cima de los benchmarks, sin un ganador claro directo. Al final del día, todo se reducirá a tu caso de uso específico para determinar qué modelo deberías usar. Yo tiendo a enfocarme en la codificación agéntica, ya que es para lo que más uso estos modelos, pero tus necesidades pueden ser diferentes. Debido a esto, recomiendo construir tu propio pequeño conjunto de evaluación y usarlo para probar modelos existentes y nuevos que salgan, para que puedas evaluar si deberías o no cambiar a él.
Grandes actualizaciones de Llama.cpp
El equipo de Llama.cpp se ha cansado de ser conocido como el backend no reconocido de herramientas mediocres como Ollama, LMStudio y Jan, y ha implementado cambios para hacer que la biblioteca sea fácilmente accesible para todos.
El primer cambio es una renovación de la interfaz de usuario predeterminada que está disponible al ejecutar un modelo de llama.cpp.
Anteriormente, la interfaz de usuario había sido muy básica y no guardaba nada para el usuario.
La interfaz renovada, muy similar a la interfaz de ChatGPT
Ahora la interfaz tiene una interfaz mucho más estándar, intuitiva y de mejor aspecto para que uses. También tiene historial de chat y herramientas más avanzadas como modificar parámetros de muestreo o hacer que el modelo siga salidas estructuradas.
Uno de los problemas persistentes con Llama cpp ha sido la dificultad de configurarlo, especialmente en comparación con herramientas como Ollama.
Esto se ha solucionado ahora, con el lanzamiento de LlamaBarn, una aplicación de barra de menú para Mac que te permite ejecutar LLMs con solo un clic.
LlamaBarn manejará automáticamente la descarga del modelo, la optimización para tu hardware específico y luego la ejecución real del modelo.
Iniciará un servidor compatible con la biblioteca de la API de OpenAI para que lo uses en tu código, y también iniciará la nueva interfaz web mencionada anteriormente.
Si actualmente estás ejecutando modelos localmente en tu Mac con herramientas como Ollama, LMStudio, Jan o cualquier otra, te recomendaría encarecidamente cambiar a Llama.cpp, ya que es lo que todas estas otras herramientas están usando internamente.
Al usar Llama.cpp obtendrás la experiencia de primera mano de ejecutar estos modelos, sin ninguna de las sobrecargas o “ajustes de rendimiento” que degradan la calidad del modelo que las otras bibliotecas proporcionan.
Quick Hits
Actualizaciones de OpenAI Codex
OpenAI ha lanzado algunas actualizaciones a su plataforma de codificación Codex, principalmente aumentando los límites de tasa en un 50% y lanzando GPT 5 Codex Mini, que usa límites de tasa la mitad de rápido que el modelo Codex regular, y también es notablemente más rápido.
Científico de IA que puede trabajar durante días
Una empresa llamada Edison Scientific ha salido con un sistema de agentes que dicen puede ejecutarse durante días seguidos.
Dicen que ya ha escrito 7 artículos sobre temas únicos, previamente desconocidos/inexplorados, y que su tasa de éxito es del 80%. También incluyen un artículo que documenta cómo funciona.
Puedes usarlo ahora gratis si tienes un correo electrónico académico (obtienes 3 consultas). Después de eso costará $200 por ejecución.
ComfyUI cloud
La popular plataforma de generación de imágenes y videos ComfyUI ha lanzado un plan de cómputo mensual que brinda a los usuarios 8 horas de GPU A100 40GB por día para generar imágenes y videos.
Si eres un usuario avanzado, una startup que tiene flujos de trabajo personalizados que quieres ejecutar, o has querido usar ComfyUI pero no tenías el poder de cómputo para ello, esta es la opción más rentable para usar ahora mismo.
Cierre
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Epoch AI lanzó una visualización genial de todos los principales centros de datos que se están construyendo ahora mismo