Releases
GPT 5.2
Less than a month after the release of GPT 5.1, OpenAI has released GPT 5.2.
Based on the benchmark scores it is much more than the small performance and personality tweaks that GPT 5.1 was.
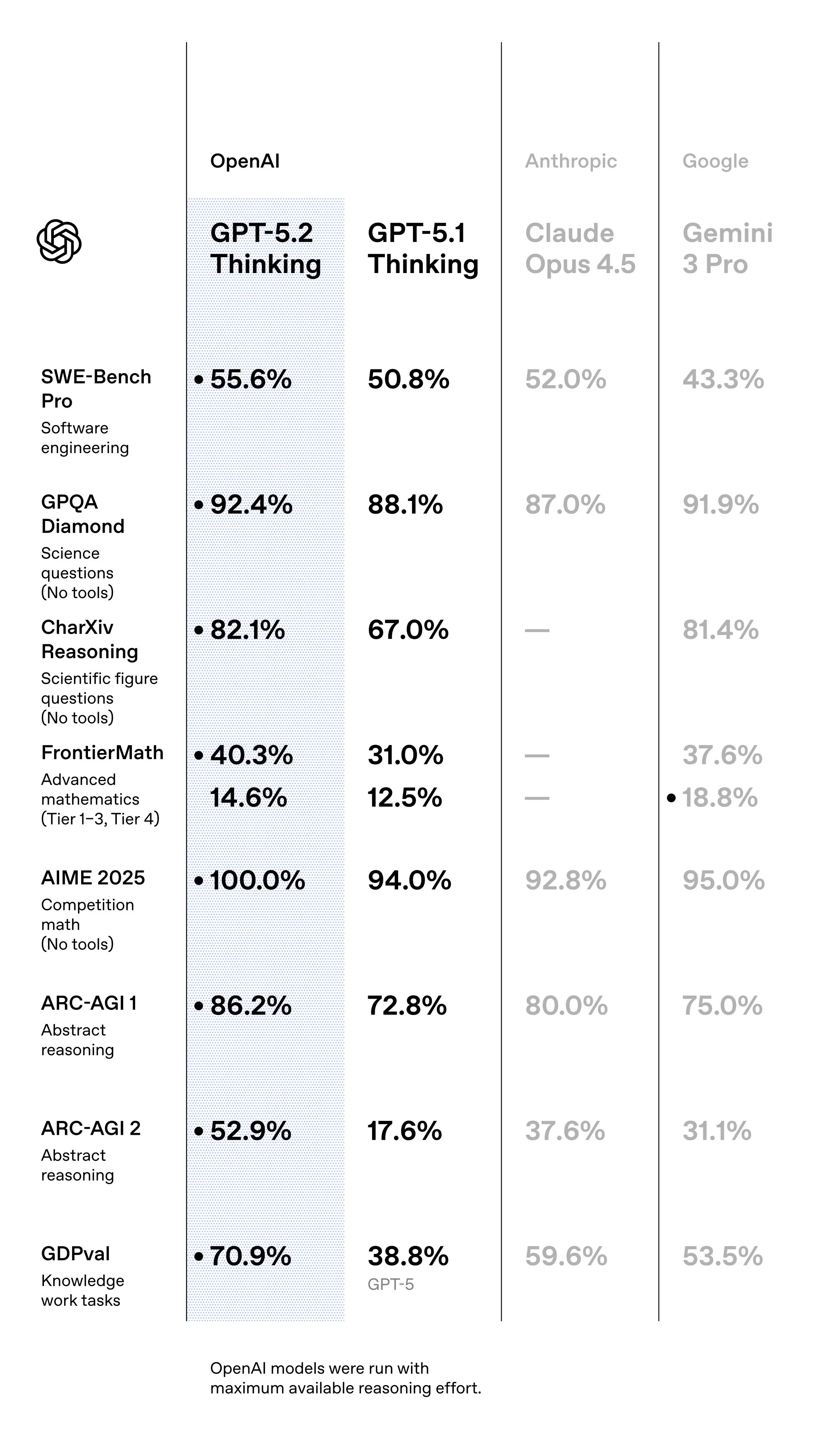
In real world use, the model seems to be a step up from GPT 5.1, but still not at the same level of quality that Opus 4.5 is, and not as revolutionary as the benchmarks make it seem.
It also inherits the capabilities of the 5.1 Codex models, making it a strong coding model, and also streamlines the lineup to that there is one model you use for all use cases instead of the 3 that they had.
This increase in performance also does not come for free, as they have increased the pricing to $14 per million.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| Claude Opus 4.5 | $5 | $25 | 69 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
| GPT 5.1 | $1.50 | $10 | 34 |
| GPT 5.2 | $1.75 | $14 | 38 |
As a general chatbot, there has been a lot of talk that the model is much colder now and reverted back to a more bland style of conversation that many users do not like when compared to 5.1 or 4o.
Overall its a another bump in capabilities, but not revolutionary. If you are already using GPT for coding it should be a bit better, as a chatbot its a bit worse, and for production use cases its increased price makes it ambiguous if its worth upgrading to.
Mistral is Back?
Last week we talked about how Mistral seems to be falling off given the poor performance of their Mistral 3 series of models
This week they released a pair of models as a part of their coding line called Devtral.
The first model is a “small” 24 billion parameter dense model called Devstral Small 2.
The other model is a 123B parameter dense model called Devstral 2.
The 123B parameter model has an interesting architecture. Most models in the 100B+ parameter range tend to be mixture of experts (MoE) models, as they provide much higher speeds than a similarly sized dense model.
This speed does come at the cost of extra engineering effort, so this could mean that Mistral is struggling to train MoE or they find the extra effort not worth it.
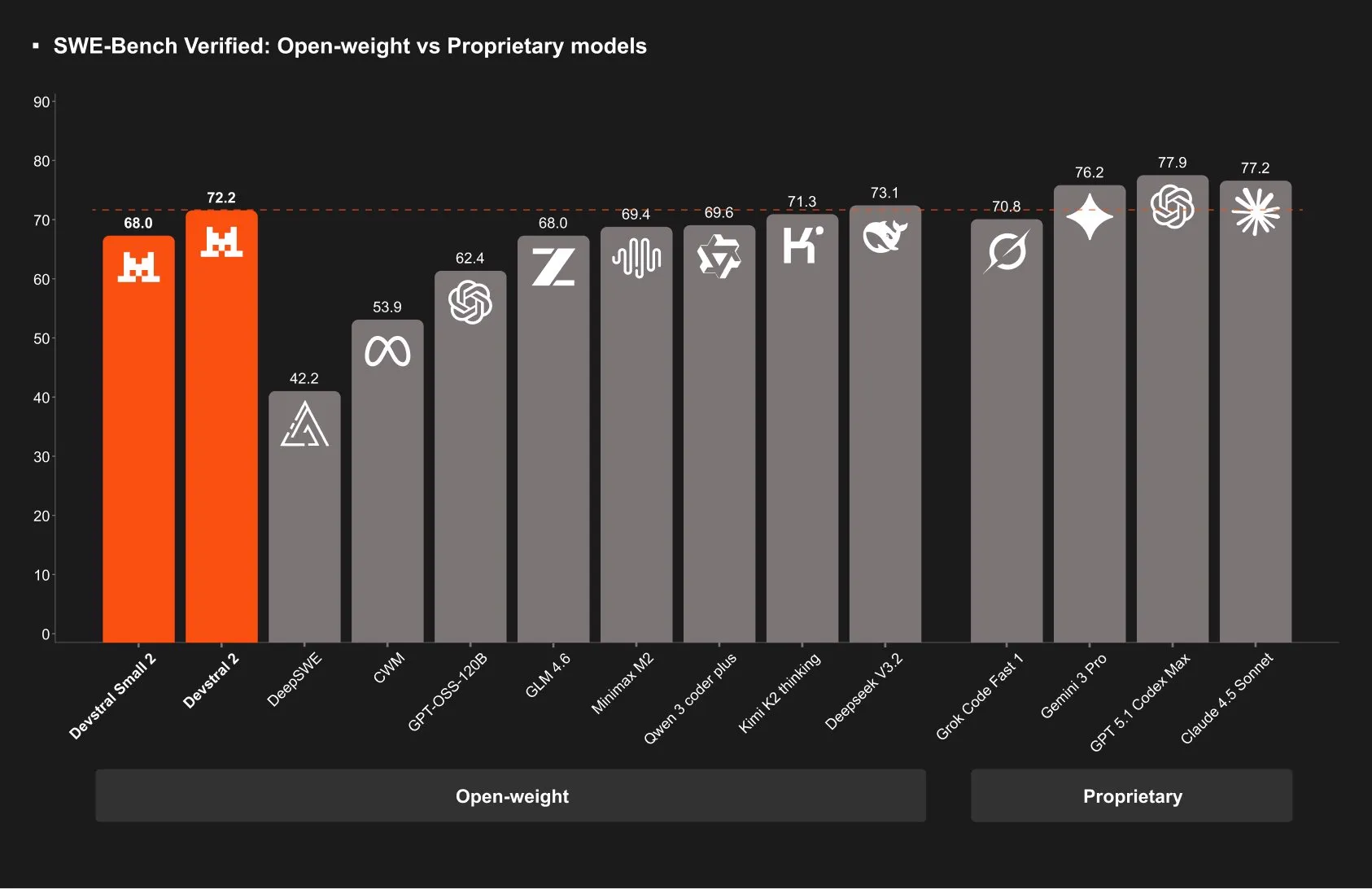
They only release benchmark scores for SWE-Bench Verified, which makes it seem like it may be benchmaxxed
The models seem decent for their size, although not a leap above the other models like their benchmark scores entail.
The small model is competitive with Qwen 3 Coder 30B, and the large model is also fairly usable given its size, although does not seem as good as GLM 4.5 Air.
Neither model stands out however when compared to the competition, and because they are dense models instead of MoE’s, that means they will be substantially slower, which is what you would want when using a small model.
There is also the issue of the license.
They use a modified MIT license, which states that if you are a part of a company that makes more than 20 million a year in revenue, then you need a commercial license for the model.
This also technically applies to personal use as well.
That means that if you are a employee at a school or researcher, than you cannot use this model.
(Calling this a modified MIT license is a very generous interpretation of what an MIT license is).
Compared to last week’s model, these models are at least about on par with their competition, but the lack of MoE versions and also the poor licensing still makes me concerned for the future of Mistral.
Quick Hits
GLM 4.6V
GLM has released an updated version of their vision model GLM 4.5V.
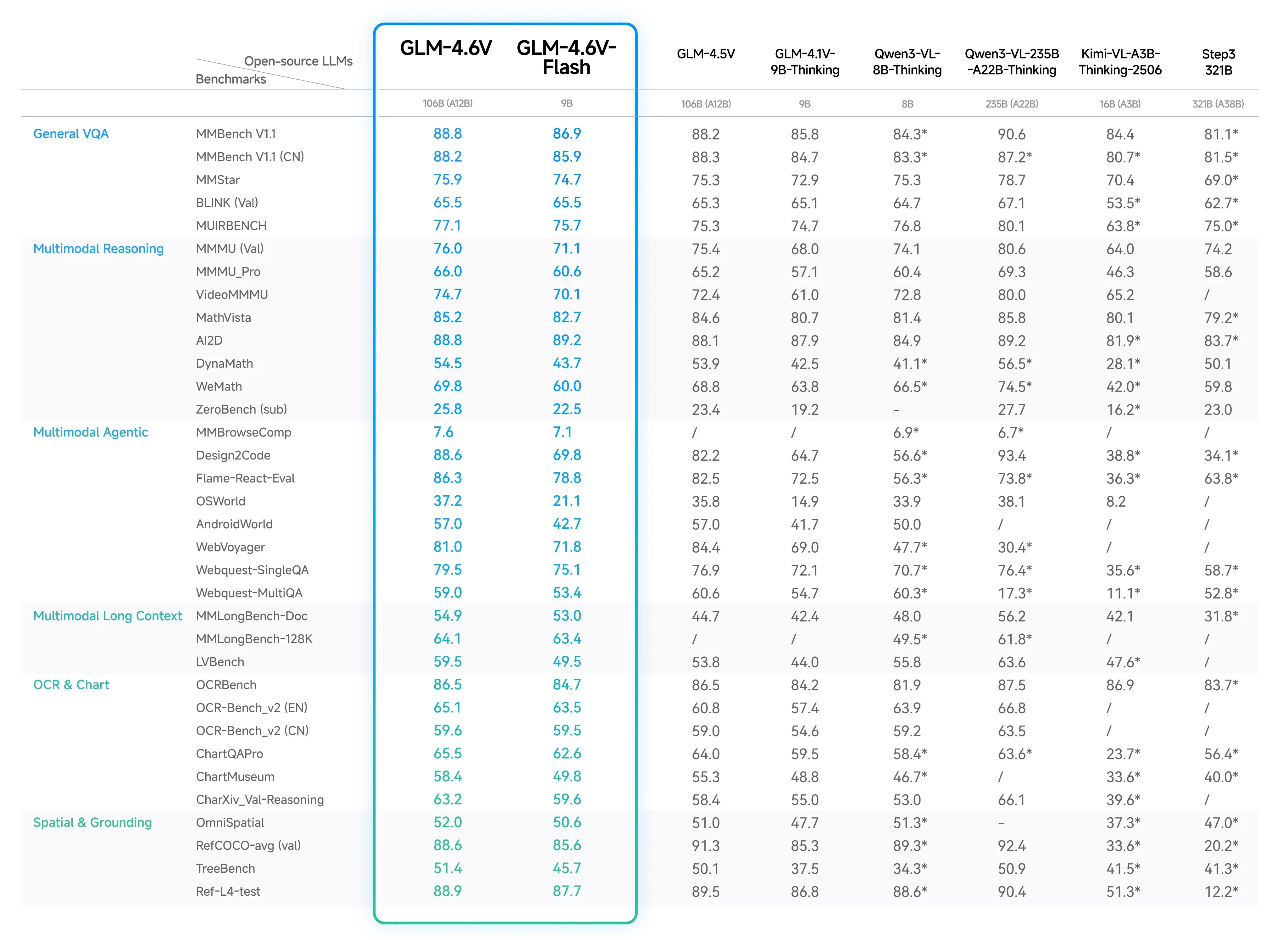
Despite the name, it is not based on the large GLM 4.6 model, but instead the small GLM 4.5 Air model.
This makes it a 108 billion parameter MoE model with 12 billion parameters.
They also released a smaller 9B dense version called GLM 4.6V-Flash.
They benchmark well for their size, with the 9B being SOTA and the 108B model being competitive with models in the 100-300B range.
Persona Prompting Does Not Work
Many people will prompt their models wit something like “You are an expert senior software engineer…” and say or expect the model to perform better.
This is known as persona prompting.
Researchers have found that this does not actually improve the model at all, and can even hurt performance instead.
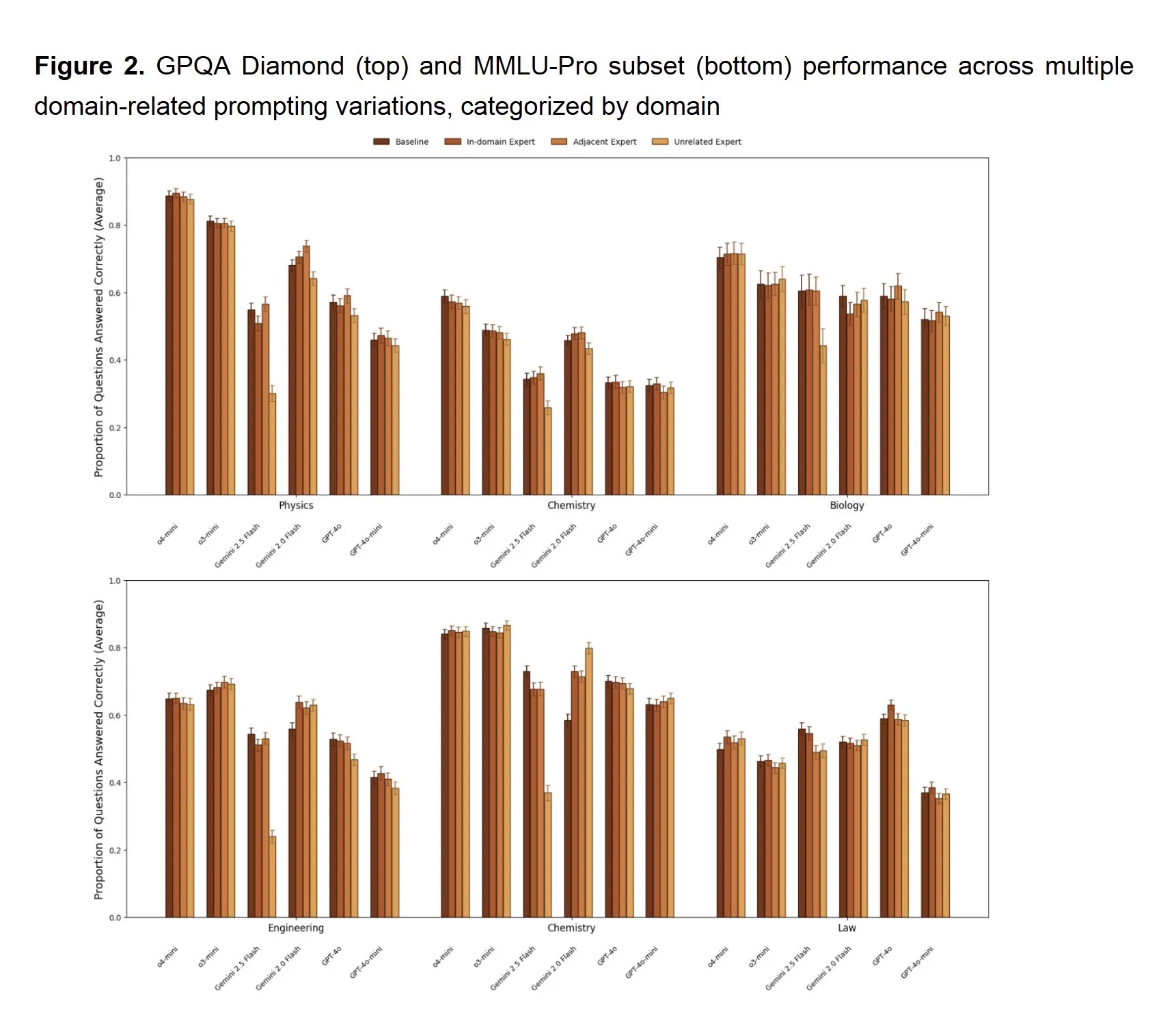
It does however change the style of the output, which can be useful depending on what you are looking for. For instance you may want more or less comments in your code.
If this is what you want, you should be telling it to answer for a specific audience instead.
OfficeQA
Databricks has released a benchmark measuring the performance of models on real world tasks that models and agents would be expected to do in an enterprise setting, including data analysis, reasoning over large pdfs, chart understanding, and web search.
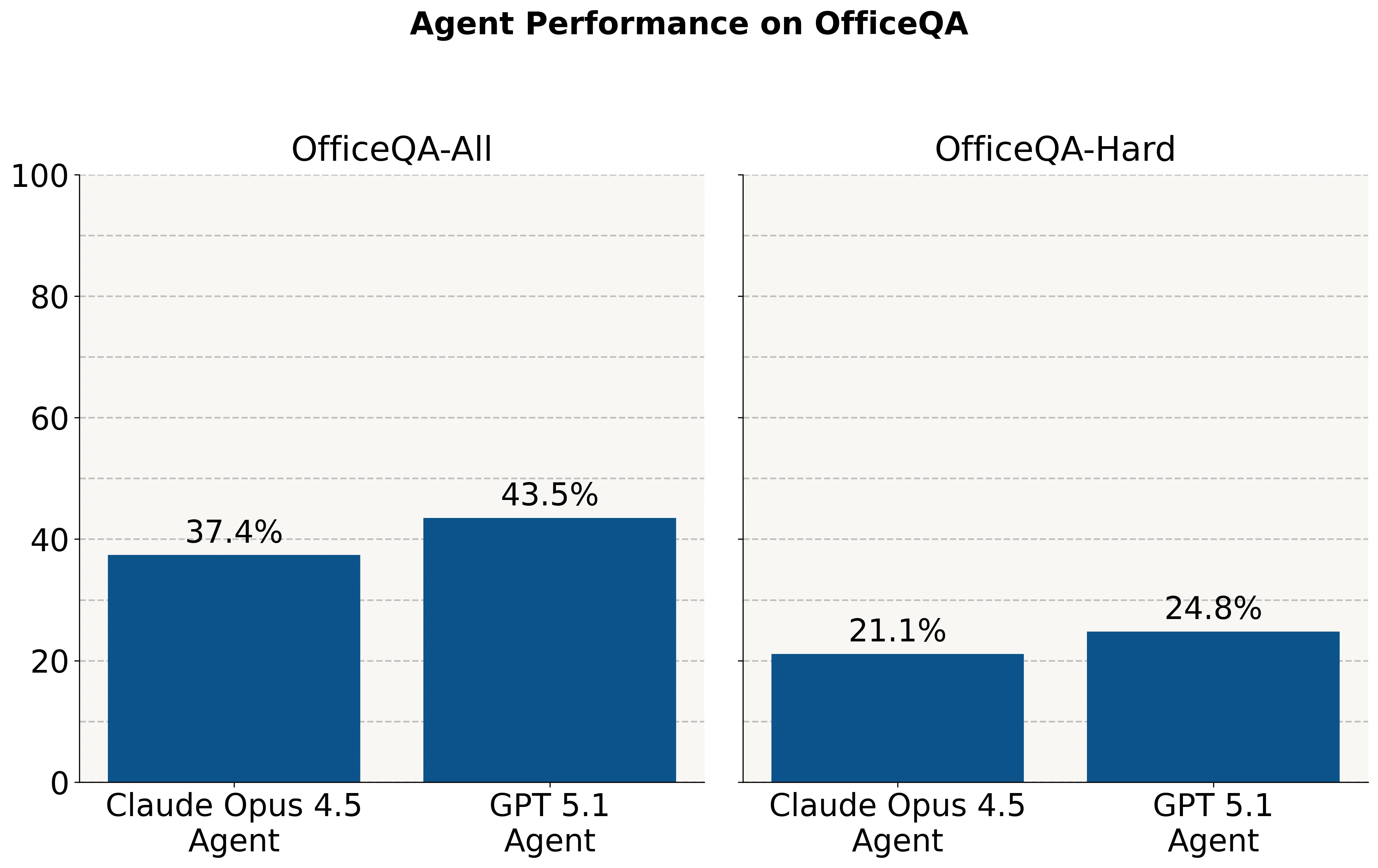
They find that even frontier models struggle on these real world tasks and there is still a lot of room to grow even for easier questions.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
GPT 5.2
Menos de um mês após o lançamento do GPT 5.1, a OpenAI lançou o GPT 5.2.
Com base nas pontuações de benchmark, é muito mais do que os pequenos ajustes de desempenho e personalidade que o GPT 5.1 foi.
 **
**
No uso do mundo real, o modelo parece ser um passo à frente do GPT 5.1, mas ainda não está no mesmo nível de qualidade que o Opus 4.5, e não é tão revolucionário quanto os benchmarks fazem parecer.
Ele também herda as capacidades dos modelos 5.1 Codex, tornando-o um modelo forte de codificação, e também simplifica a linha de produtos para que haja um modelo que você usa para todos os casos de uso em vez dos 3 que eles tinham.
Esse aumento de desempenho também não é gratuito, pois eles aumentaram o preço para $14 por milhão.
| Modelo | $ por milhão (entrada) | $ por milhão (saída) | Tokens por segundo |
|---|
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| Claude Opus 4.5 | $5 | $25 | 69 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
| GPT 5.1 | $1.50 | $10 | 34 |
| GPT 5.2 | $1.75 | $14 | 38 |
Como um chatbot geral, houve muita conversa de que o modelo está muito mais frio agora e voltou a um estilo de conversa mais sem graça que muitos usuários não gostam quando comparado ao 5.1 ou 4o.
No geral, é outro aumento nas capacidades, mas não revolucionário. Se você já está usando GPT para codificação, deve ser um pouco melhor, como chatbot é um pouco pior, e para casos de uso em produção seu preço aumentado torna ambíguo se vale a pena atualizar.
Mistral está de Volta?
Na semana passada falamos sobre como a Mistral parece estar em declínio dado o desempenho ruim de sua série de modelos Mistral 3
Esta semana eles lançaram um par de modelos como parte de sua linha de codificação chamada Devtral.
O primeiro modelo é um modelo denso “pequeno” de 24 bilhões de parâmetros chamado Devstral Small 2.
O outro modelo é um modelo denso de 123B parâmetros chamado Devstral 2.
O modelo de 123B parâmetros tem uma arquitetura interessante. A maioria dos modelos na faixa de 100B+ parâmetros tendem a ser modelos de mistura de especialistas (MoE), pois fornecem velocidades muito maiores do que um modelo denso de tamanho semelhante.
Essa velocidade vem ao custo de esforço extra de engenharia, então isso pode significar que a Mistral está tendo dificuldades para treinar MoE ou eles acham que o esforço extra não vale a pena.

Eles apenas lançam pontuações de benchmark para SWE-Bench Verified, o que faz parecer que pode estar otimizado para benchmarks
Os modelos parecem decentes para seu tamanho, embora não sejam um salto acima dos outros modelos como suas pontuações de benchmark implicam.
O modelo pequeno é competitivo com Qwen 3 Coder 30B, e o modelo grande também é bastante utilizável dado seu tamanho, embora não pareça tão bom quanto o GLM 4.5 Air.
Nenhum dos modelos se destaca, no entanto, quando comparado à concorrência, e porque são modelos densos em vez de MoE’s, isso significa que serão substancialmente mais lentos, que é o que você gostaria ao usar um modelo pequeno.
Há também a questão da licença.
Eles usam uma licença MIT modificada, que afirma que se você faz parte de uma empresa que ganha mais de 20 milhões por ano em receita, então você precisa de uma licença comercial para o modelo.
Isso também se aplica tecnicamente ao uso pessoal.
Isso significa que se você é um funcionário de uma escola ou pesquisador, então você não pode usar este modelo.
(Chamar isso de licença MIT modificada é uma interpretação muito generosa do que é uma licença MIT).
Comparado ao modelo da semana passada, esses modelos estão pelo menos no mesmo nível de sua concorrência, mas a falta de versões MoE e também o licenciamento ruim ainda me preocupa quanto ao futuro da Mistral.
Destaques Rápidos
GLM 4.6V
A GLM lançou uma versão atualizada de seu modelo de visão GLM 4.5V.

Apesar do nome, ele não é baseado no grande modelo GLM 4.6, mas sim no pequeno modelo GLM 4.5 Air.
Isso o torna um modelo MoE de 108 bilhões de parâmetros com 12 bilhões de parâmetros.
Eles também lançaram uma versão densa menor de 9B chamada GLM 4.6V-Flash.
Eles têm bom desempenho em benchmarks para seu tamanho, com o 9B sendo SOTA e o modelo de 108B sendo competitivo com modelos na faixa de 100-300B.
Prompting de Persona Não Funciona
Muitas pessoas vão fazer prompts em seus modelos com algo como “Você é um engenheiro de software sênior especialista…” e dizem ou esperam que o modelo tenha melhor desempenho.
Isso é conhecido como prompting de persona.
Pesquisadores descobriram que isso não melhora realmente o modelo, e pode até prejudicar o desempenho.

**
No entanto, isso muda o estilo da saída, o que pode ser útil dependendo do que você está procurando. Por exemplo, você pode querer mais ou menos comentários em seu código.
Se isso é o que você quer, você deveria estar dizendo para responder para um público específico.
OfficeQA
A Databricks lançou um benchmark medindo o desempenho de modelos em tarefas do mundo real que modelos e agentes seriam esperados para fazer em um ambiente empresarial, incluindo análise de dados, raciocínio sobre grandes PDFs, compreensão de gráficos e busca na web.

Eles descobriram que mesmo modelos de ponta lutam nessas tarefas do mundo real e ainda há muito espaço para crescer mesmo para questões mais fáceis.
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quer receber as notícias toda semana, certifique-se de se juntar à nossa lista de e-mails abaixo.
Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
GPT 5.2
Menos de un mes después del lanzamiento de GPT 5.1, OpenAI ha lanzado GPT 5.2.
Basándose en los puntajes de los benchmarks, es mucho más que los pequeños ajustes de rendimiento y personalidad que fue GPT 5.1.
**
En el uso del mundo real, el modelo parece ser un paso adelante respecto a GPT 5.1, pero aún no está al mismo nivel de calidad que Opus 4.5, y no es tan revolucionario como los benchmarks lo hacen parecer.
También hereda las capacidades de los modelos 5.1 Codex, convirtiéndolo en un modelo de programación sólido, y además simplifica la línea de productos para que haya un solo modelo que uses para todos los casos de uso en lugar de los 3 que tenían.
Este aumento en el rendimiento tampoco es gratuito, ya que han incrementado el precio a $14 por millón.
| Modelo | $ por millón (entrada) | $ por millón (salida) | Tokens por segundo |
|---|
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| Claude Opus 4.5 | $5 | $25 | 69 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
| GPT 5.1 | $1.50 | $10 | 34 |
| GPT 5.2 | $1.75 | $14 | 38 |
Como chatbot general, ha habido mucha conversación de que el modelo es ahora mucho más frío y ha vuelto a un estilo de conversación más soso que a muchos usuarios no les gusta cuando se compara con 5.1 o 4o.
En general, es otro aumento en las capacidades, pero no revolucionario. Si ya estás usando GPT para programación debería ser un poco mejor, como chatbot es un poco peor, y para casos de uso en producción su precio aumentado hace ambiguo si vale la pena actualizarlo.
¿Mistral está de vuelta?
La semana pasada hablamos de cómo Mistral parece estar cayendo dado el pobre rendimiento de su serie de modelos Mistral 3.
Esta semana lanzaron un par de modelos como parte de su línea de programación llamada Devtral.
El primer modelo es un modelo denso “pequeño” de 24 mil millones de parámetros llamado Devstral Small 2.
El otro modelo es un modelo denso de 123B parámetros llamado Devstral 2.
El modelo de 123B parámetros tiene una arquitectura interesante. La mayoría de los modelos en el rango de 100B+ parámetros tienden a ser modelos mixture of experts (MoE), ya que proporcionan velocidades mucho más altas que un modelo denso de tamaño similar.
Esta velocidad sí viene con el costo de esfuerzo adicional de ingeniería, por lo que esto podría significar que Mistral está teniendo dificultades para entrenar MoE o encuentran que el esfuerzo adicional no vale la pena.
Solo publican puntajes de benchmark para SWE-Bench Verified, lo que hace parecer que puede estar benchmaxxed
Los modelos parecen decentes para su tamaño, aunque no son un salto por encima de los otros modelos como implican sus puntajes de benchmark.
El modelo pequeño es competitivo con Qwen 3 Coder 30B, y el modelo grande también es bastante utilizable dado su tamaño, aunque no parece tan bueno como GLM 4.5 Air.
Sin embargo, ninguno de los modelos destaca cuando se compara con la competencia, y debido a que son modelos densos en lugar de MoE’s, eso significa que serán sustancialmente más lentos, que es lo que querrías al usar un modelo pequeño.
También está el problema de la licencia.
Usan una licencia MIT modificada, que establece que si eres parte de una empresa que genera más de 20 millones al año en ingresos, entonces necesitas una licencia comercial para el modelo.
Esto también se aplica técnicamente al uso personal.
Eso significa que si eres empleado de una escuela o investigador, entonces no puedes usar este modelo.
(Llamar a esto una licencia MIT modificada es una interpretación muy generosa de lo que es una licencia MIT).
Comparado con el modelo de la semana pasada, estos modelos al menos están a la par con su competencia, pero la falta de versiones MoE y también la pobre licencia aún me preocupan por el futuro de Mistral.
Noticias Rápidas
GLM 4.6V
GLM ha lanzado una versión actualizada de su modelo de visión GLM 4.5V.
A pesar del nombre, no está basado en el gran modelo GLM 4.6, sino en el pequeño modelo GLM 4.5 Air.
Esto lo convierte en un modelo MoE de 108 mil millones de parámetros con 12 mil millones de parámetros.
También lanzaron una versión densa más pequeña de 9B llamada GLM 4.6V-Flash.
Obtienen buenos resultados en benchmarks para su tamaño, con el 9B siendo SOTA y el modelo de 108B siendo competitivo con modelos en el rango de 100-300B.
Los Prompts de Persona No Funcionan
Muchas personas harán prompts a sus modelos con algo como “Eres un ingeniero de software senior experto…” y dirán o esperarán que el modelo tenga mejor rendimiento.
Esto se conoce como persona prompting.
Los investigadores han descubierto que esto en realidad no mejora el modelo en absoluto, y puede incluso perjudicar el rendimiento.
**
Sin embargo, sí cambia el estilo de la salida, lo que puede ser útil dependiendo de lo que estés buscando. Por ejemplo, puedes querer más o menos comentarios en tu código.
Si esto es lo que quieres, deberías decirle que responda para una audiencia específica en su lugar.
OfficeQA
Databricks ha lanzado un benchmark que mide el rendimiento de modelos en tareas del mundo real que se esperaría que modelos y agentes hagan en un entorno empresarial, incluyendo análisis de datos, razonamiento sobre PDFs grandes, comprensión de gráficos y búsqueda web.
Descubren que incluso los modelos de frontera tienen dificultades en estas tareas del mundo real y todavía hay mucho espacio para crecer incluso para preguntas más fáciles.
Fin
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.