Releases
Gemma 4
Google has re-entered the open source model race with their Gemma 4 series of models.
The Gemma 4 series comes in 4 sizes, 5 billion, 8 billion, 26 billion (MoE, 4 billion active params), and 31 billion (dense).
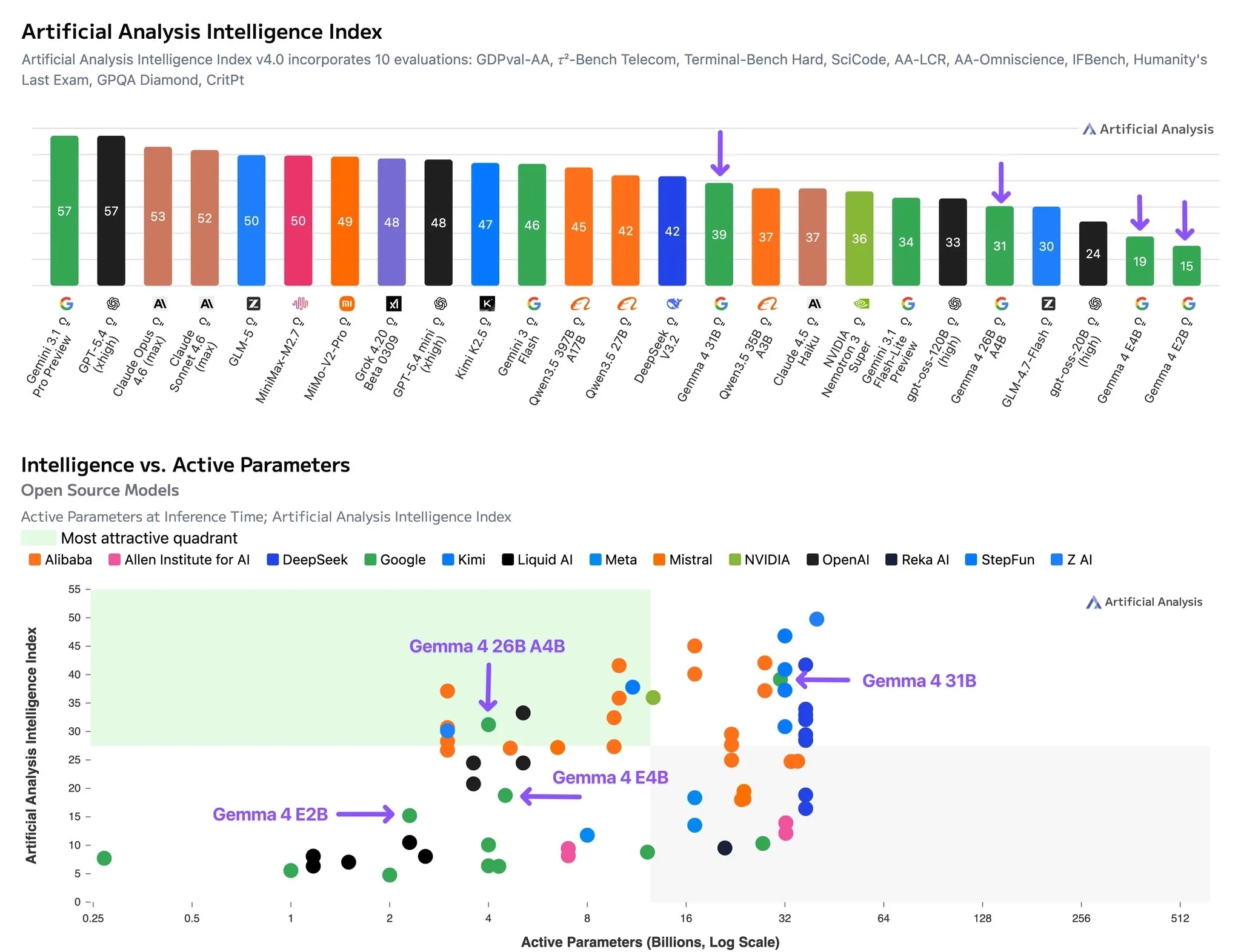
The smaller 5B and 8B models follow the Gemma 3n architecture, which is to say, completely different than any other LLM out there right now, making them much more efficient than their parameter count would suggest (about 2x faster and more efficient).
The models are meant to compete with their Qwen 3.5 counterparts, which they are mostly able to do.
The smaller models falls bit behind, but will be better for low resource edge deployments due to their very efficient architecture.
The larger models are a closer match, being ahead on coding benchmarks but behind on more general agentic tasks.
They also are more efficient reasoners than Qwen3.5, with token usage in reasoning mode being comparable to the Qwen3.5 models in non-reasoning mode (and 3-5x less than Qwen3.5 with reasoning on).
This once again makes it good for local or fast inference due to the limited amount of thinking that the models do, which the Qwen3.5 models tend to overthink very heavily.
Overall the Gemma 4 models are solid, if you are looking for low cost models or models that you can run at home, I would definitely check them out and compare them to the Qwen3.5 models for your use cases.
Quick Hits
Trinity Large Thinking
Arcee AI released their Trinity series of open source American models a few months ago, but they had a rather hastily done post training.
Now they have updated the post training for the Trinity large model (MoE, 398B total, 13B active params), and the results are looking good.
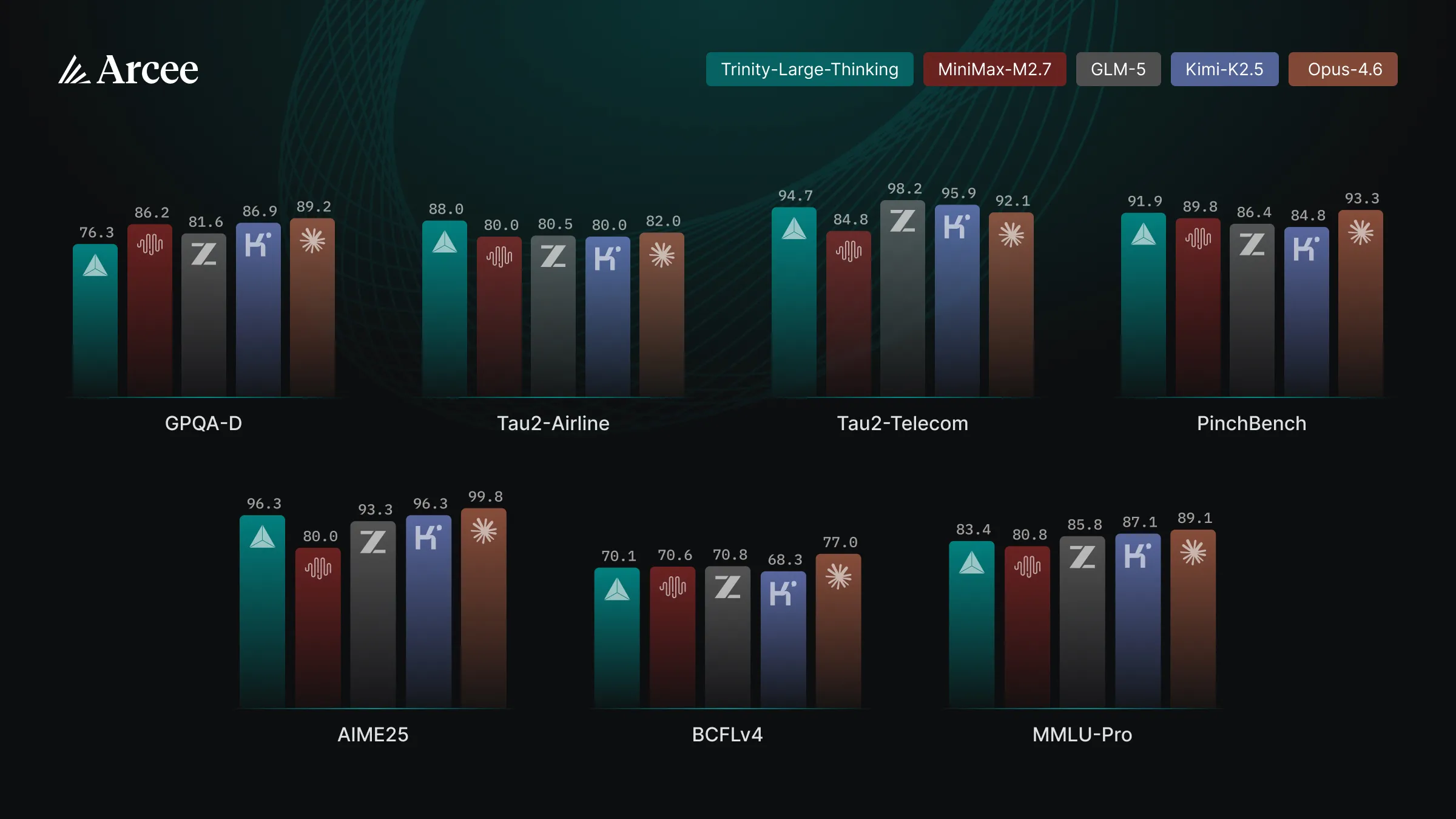
They are competitive with the top open models from China on benchmarks.
They were also the top American model on OpenRouter for the past few months, and that was before this much better post training that they have given the model.
I have been a fan of Arcee AI for a while now. Watching them go from finetuning small models to training their own frontier models in ~1 year has been super cool to see, and I would recommend checking out this model if you want to support American open source AI.
LFM2.5 350M
LiquidAI continues their quest to make the smallest, fastest models that are still somewhat usable for agentic tasks, this time coming out with a 350M perameter model that has been trained on 28 trillion tokens, making it the most overtrained model that we know of (based on Chinchilla scaling laws)
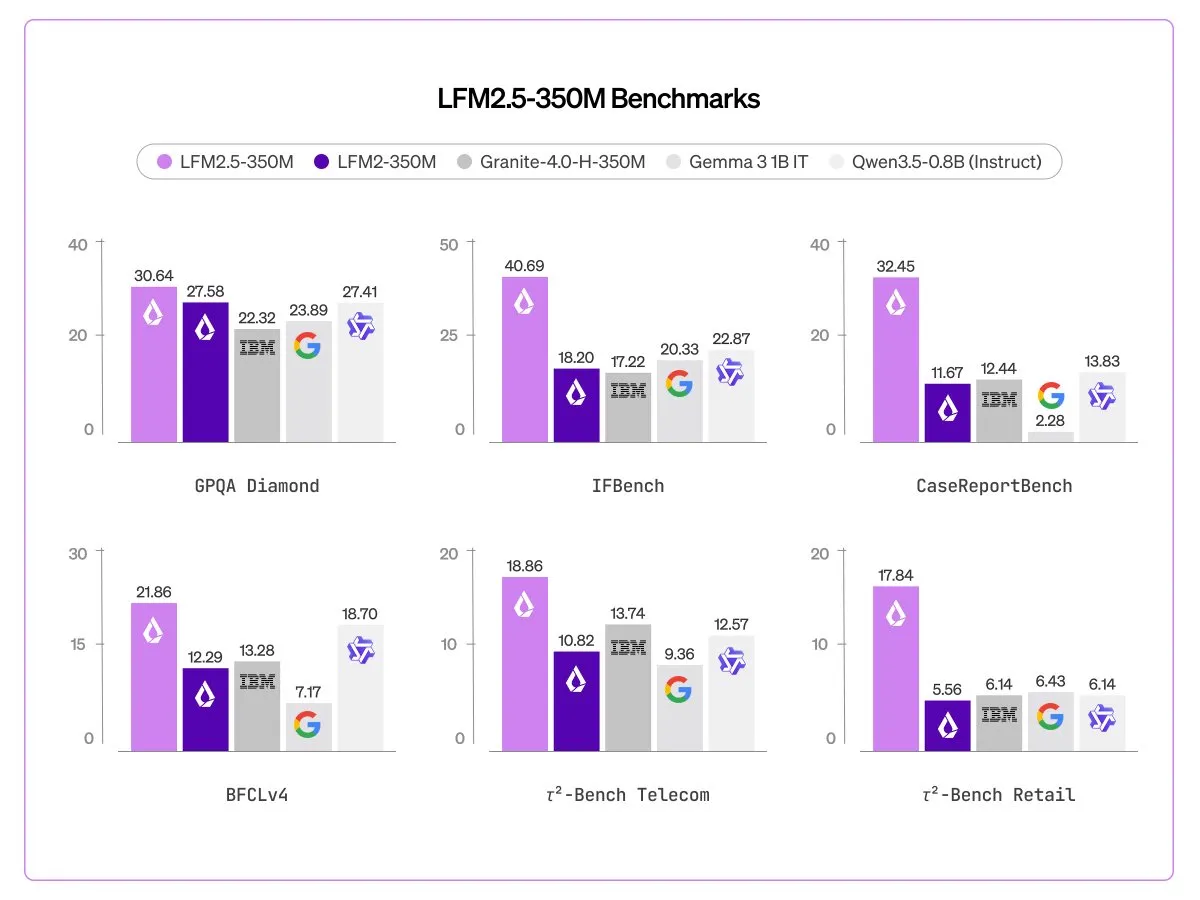
When quantized this model will take up only about 300MB of memory, allowing it to be deployed almost anywhere.
Historically this model size has been considered only for toy models that researchers use, so the fact that Liquid have been able to make something that is somewhat useful is extremely impressive.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

From Tomislav on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Gemma 4
O Google voltou à corrida dos modelos de código aberto com sua série de modelos Gemma 4.
A série Gemma 4 vem em 4 tamanhos: 5 bilhões, 8 bilhões, 26 bilhões (MoE, 4 bilhões de parâmetros ativos) e 31 bilhões (denso).
Os modelos menores de 5B e 8B seguem a arquitetura Gemma 3n, ou seja, são completamente diferentes de qualquer outro LLM existente atualmente, tornando-os muito mais eficientes do que sua contagem de parâmetros sugeriria (cerca de 2x mais rápidos e eficientes).
Os modelos foram desenvolvidos para competir com seus equivalentes no Qwen 3.5, o que conseguem fazer em grande parte.
Os modelos menores ficam um pouco para trás, mas serão melhores para implantações de borda com poucos recursos, graças à sua arquitetura altamente eficiente.
Os modelos maiores são uma correspondência mais próxima, estando à frente nos benchmarks de programação, mas atrás em tarefas agênticas mais gerais.
Eles também são raciocínadores mais eficientes do que o Qwen3.5, com o uso de tokens no modo de raciocínio sendo comparável aos modelos Qwen3.5 no modo sem raciocínio (e 3 a 5x menor do que o Qwen3.5 com raciocínio ativado).
Isso novamente os torna adequados para inferência local ou rápida, devido à quantidade limitada de “pensamento” que os modelos realizam — algo que os modelos Qwen3.5 tendem a exagerar bastante.
No geral, os modelos Gemma 4 são sólidos. Se você está procurando modelos de baixo custo ou modelos que possa rodar em casa, recomendo fortemente experimentá-los e compará-los com os modelos Qwen3.5 para seus casos de uso.
Destaques Rápidos
Trinity Large Thinking
A Arcee AI lançou sua série Trinity de modelos americanos de código aberto há alguns meses, mas o pós-treinamento foi feito de forma um tanto apressada.
Agora eles atualizaram o pós-treinamento do modelo Trinity large (MoE, 398B total, 13B de parâmetros ativos), e os resultados estão promissores.
Eles são competitivos com os principais modelos abertos da China nos benchmarks.
Também foram o principal modelo americano no OpenRouter nos últimos meses — e isso antes deste pós-treinamento muito aprimorado que receberam.
Sou fã da Arcee AI há algum tempo. Acompanhar sua evolução, de fazer fine-tuning em modelos pequenos ao treinamento de seus próprios modelos de fronteira em cerca de 1 ano, tem sido incrível de observar. Recomendo que você experimente este modelo se quiser apoiar a IA americana de código aberto.
LFM2.5 350M
A LiquidAI continua sua missão de criar os modelos menores e mais rápidos que ainda sejam minimamente utilizáveis para tarefas agênticas — desta vez lançando um modelo de 350M de parâmetros treinado em 28 trilhões de tokens, tornando-o o modelo mais “sobre-treinado” de que temos conhecimento (com base nas leis de escalonamento Chinchilla).
Quando quantizado, este modelo ocupará apenas cerca de 300MB de memória, permitindo que seja implantado em praticamente qualquer lugar.
Historicamente, esse tamanho de modelo era considerado apenas para modelos experimentais usados por pesquisadores, por isso o fato de a Liquid ter conseguido criar algo minimamente útil é extremamente impressionante.
Conclusão
Espero que você tenha gostado das novidades desta semana. Se quiser receber as notícias toda semana, não deixe de se inscrever em nossa lista de e-mails abaixo.
De Tomislav no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Gemma 4
Google ha vuelto a entrar en la carrera de modelos de código abierto con su serie de modelos Gemma 4.
La serie Gemma 4 viene en 4 tamaños: 5 mil millones, 8 mil millones, 26 mil millones (MoE, 4 mil millones de parámetros activos) y 31 mil millones (denso).
Los modelos más pequeños de 5B y 8B siguen la arquitectura Gemma 3n, es decir, son completamente diferentes a cualquier otro LLM disponible actualmente, lo que los hace mucho más eficientes de lo que su cantidad de parámetros sugeriría (aproximadamente 2 veces más rápidos y eficientes).
Los modelos están diseñados para competir con sus contrapartes Qwen 3.5, algo que logran en gran medida.
Los modelos más pequeños se quedan un poco atrás, pero serán mejores para implementaciones en dispositivos de bajos recursos gracias a su arquitectura altamente eficiente.
Los modelos más grandes son una competencia más cercana, siendo superiores en benchmarks de programación pero inferiores en tareas agénticas más generales.
También son razonadores más eficientes que Qwen3.5, con un uso de tokens en modo de razonamiento comparable al de los modelos Qwen3.5 en modo sin razonamiento (y entre 3 y 5 veces menos que Qwen3.5 con el razonamiento activado).
Esto los hace nuevamente ideales para inferencia local o rápida debido a la cantidad limitada de “pensamiento” que realizan los modelos, mientras que los modelos Qwen3.5 tienden a pensar en exceso de manera muy marcada.
En general, los modelos Gemma 4 son sólidos. Si buscas modelos de bajo costo o modelos que puedas ejecutar en casa, definitivamente te recomendaría probarlos y compararlos con los modelos Qwen3.5 para tus casos de uso.
Noticias Breves
Trinity Large Thinking
Arcee AI lanzó su serie Trinity de modelos estadounidenses de código abierto hace unos meses, aunque con un post-entrenamiento realizado de forma bastante apresurada.
Ahora han actualizado el post-entrenamiento del modelo Trinity Large (MoE, 398B parámetros totales, 13B parámetros activos), y los resultados se ven prometedores.
Son competitivos con los mejores modelos abiertos de China en benchmarks.
También fueron el modelo estadounidense mejor valorado en OpenRouter durante los últimos meses, y eso fue antes de este post-entrenamiento mucho mejor que le han dado al modelo.
He sido fanático de Arcee AI por un tiempo. Ver cómo pasaron de hacer fine-tuning de modelos pequeños a entrenar sus propios modelos de frontera en aproximadamente 1 año ha sido increíblemente emocionante, y recomendaría probar este modelo si quieres apoyar la IA estadounidense de código abierto.
LFM2.5 350M
LiquidAI continúa su búsqueda de hacer los modelos más pequeños y rápidos que aún sean mínimamente utilizables para tareas agénticas, esta vez presentando un modelo de 350M parámetros que ha sido entrenado con 28 billones de tokens, convirtiéndolo en el modelo más sobre-entrenado que conocemos (basado en las leyes de escala de Chinchilla).
Cuando se cuantiza, este modelo ocupará solo alrededor de 300MB de memoria, lo que permite desplegarlo en casi cualquier lugar.
Históricamente, este tamaño de modelo se ha considerado solo para modelos de juguete utilizados por investigadores, por lo que el hecho de que Liquid haya logrado crear algo mínimamente útil es extremadamente impresionante.
Cierre
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
De Tomislav en Twitter