Releases
Gemini 3
Google’s long awaited Gemini 3 model is finally here.
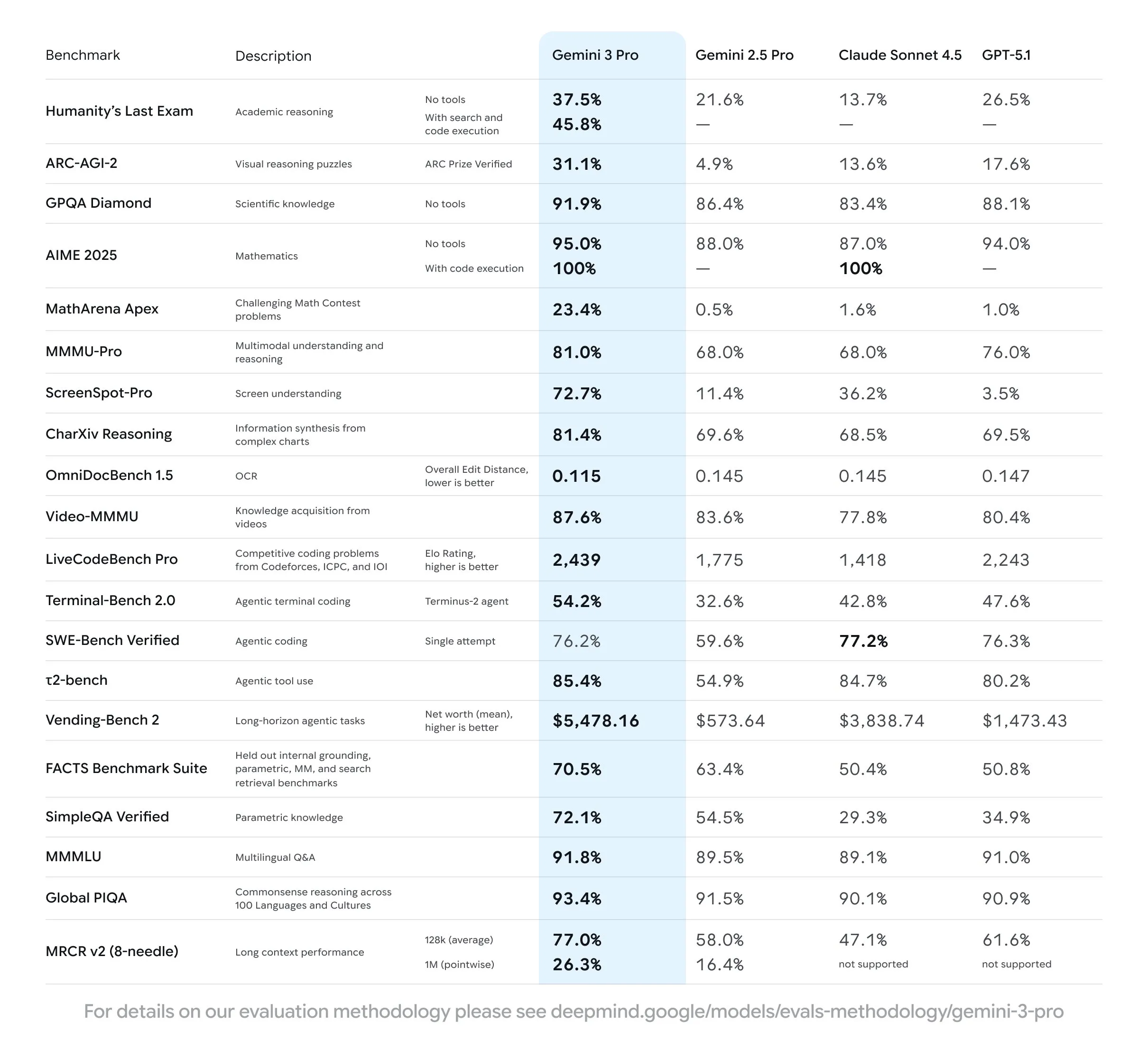
A nice array of benchmarks, much better than what we have seen from the GPT 5 and Sonnet 4.5 releases
Let’s start with the good. What categories is Gemini 3 the definitive best in?
The first and most apparent is frontend design.
In the frontend design arena, it is a full 100 ELO higher than the next best model.
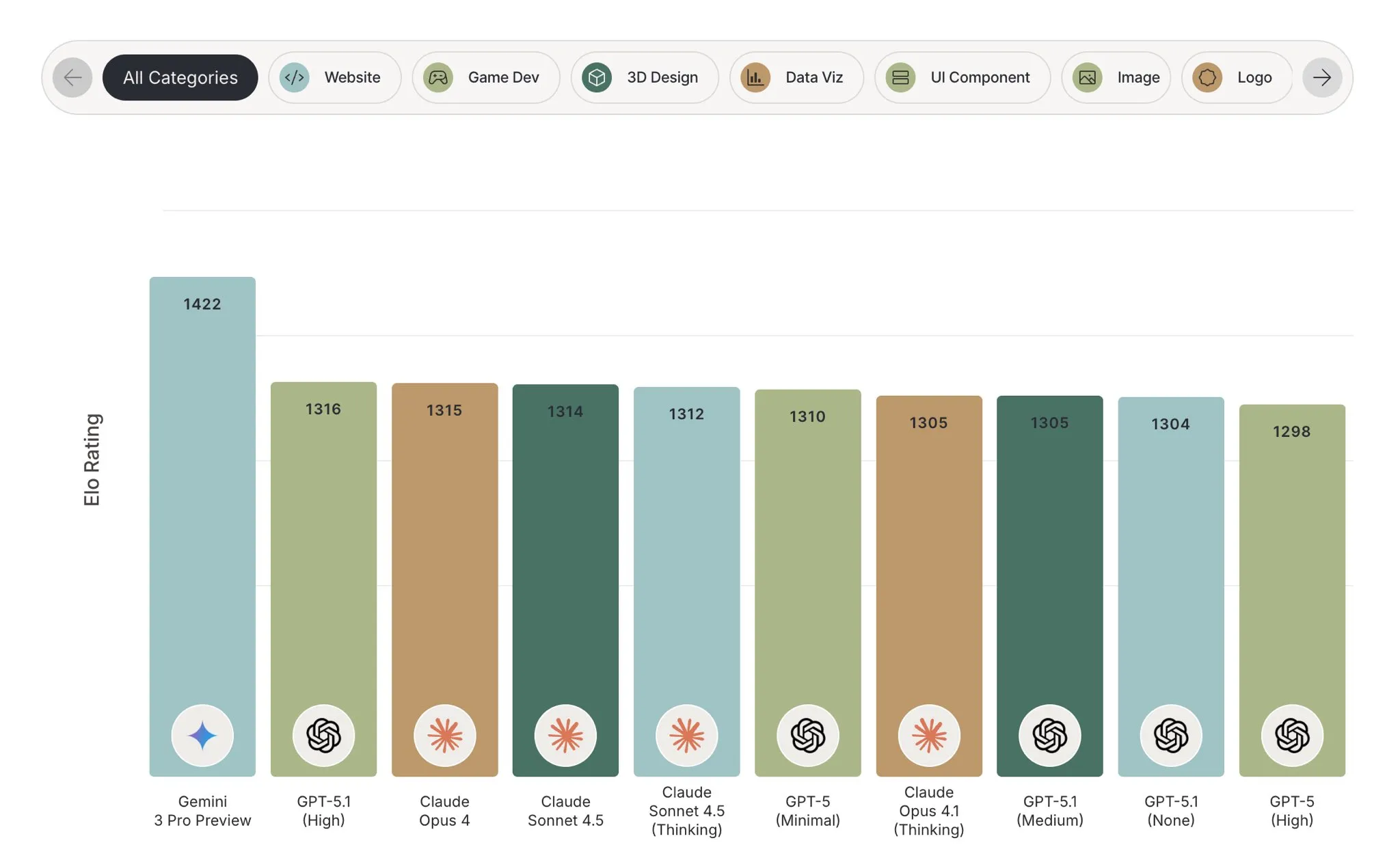
Example website made by Gemini 3 from Twitter
The next category is multimodal understanding, which is unsurprising since Gemini 2.5 was already SOTA for this.
Like Gemini 2.5, it can handle image, audio, and video inputs.
OpenAI and Anthropic don’t seem very keen on multimodal capabilities for their models, allowing Gemini to easily take the throne.
The final category is overall world knowledge. We will go more into depth on this in the new hallucination benchmark news later on, but essentially world knowledge seems to be directly correlated with model size, meaning that Gemini is most likely the largest model that you can use right now.
Gemini has the most awareness of what has happened in the past, and also its knowledge of obscure facts is also the best of any model, most likely due to the pretraining data that Google has been able to put together for it along with its very large size.
Despite its presumed size, it is actually a fairly fast model, with about double the tokens per second as GPT-5. This is most likely due to the MoE architecture that they are using, and also potentially the performance difference of TPUs vs GPUs, but that is mostly speculation since we don’t have any way to measure the underlying model’s size from the outside.
As for pricing, it falls in between Sonnet 4.5 and GPT-5, while being noticeably faster than both.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5 | $1.50 | $10 | 34 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
This is via the API, unlike Anthropic and OpenAI, Google gives out a decent amount of free usage through AIStudio for chatting and the Gemini CLI for agentic coding. The specific rate limits for these are not known yet as they are just getting rolled out, but seem to be fairly generous in my testing so far.
For coding, the model seems to be very usable, around the level of Sonnet 4.5, but it is missing the insane attention to detail that GPT 5.1 Codex has. Like I mentioned before it is by far the best model out there for frontend design, so I would use it for that at the very least.
The model is definitely still a Gemini model, as it still has the depressed tendencies that Gemini 2.5 had when it was unable to solve a problem, and in general is an LLM that is not afraid to let the user know its frustrations.
As for most of its other capabilities, it is around the frontier level of GPT-5.1 and Sonnet 4.5. You can see this sentiment in this Twitter thread, where you can find users with complete opposite opinions as one another for many of its more general capabilities, showing that it is dependent on prompt and output style more than the model’s direct capabilities. I talk more about this phenomenon at the end of my Kimi K2 Thinking review if you want to read more about it.
A final note, one of the researchers said that the increase in capabilities for Gemini 3 is just due to better pre- and post-training, and there was nothing that fancy used to make the model, showing that the scaling laws that we have been using the past few years still hold as we enter the realm of truly massive LLMs.
GPT-5.1 Codex Max
In response to the Gemini release this week, OpenAI released an updated version of their GPT-5.1 Codex models called GPT-5.1 Codex Max.
Despite the name, it is not a single model but the new flagship family of models to be used in Codex.
It comes in the usual variants of low, medium, or high reasoning, which means the full name of each model is something like GPT-5.1 Codex Max High (not a confusing naming scheme at all).
In addition to the usual reasoning variants, they also released an extra high reasoning version for the hardest tasks.
The medium reasoning is still recommended as the default go to, and what I personally use, but if you find the model struggling you can bump it up to the higher reasoning levels using the /model command in the Codex CLI.
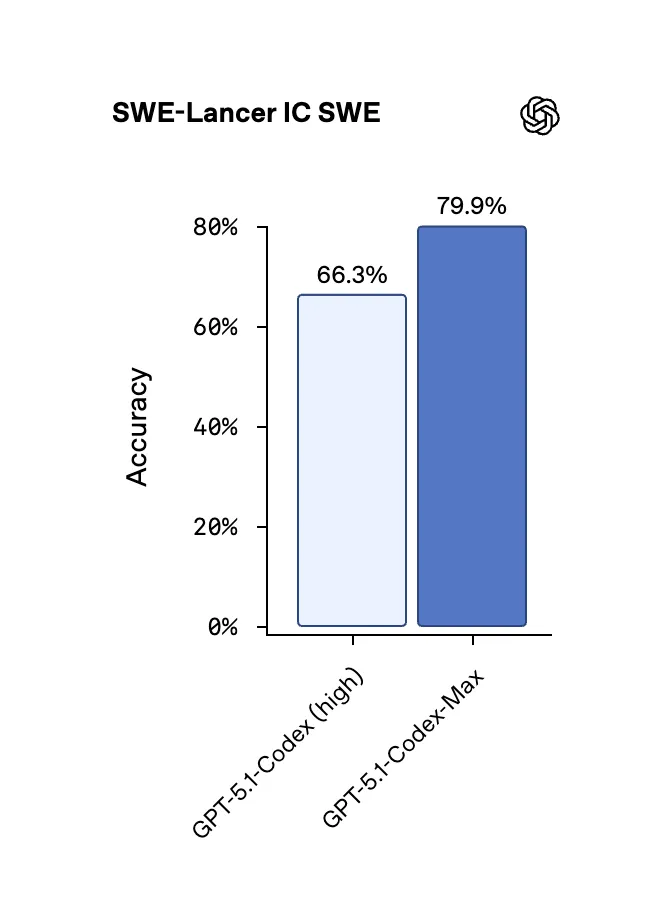
SWE Lancer is a much better benchmark than the usual SWE Bench Verified. It covers 1,400 real world tasks that were requested on UpWork, and total $1 million dollars in payouts.
Despite the weird model naming, this is a non-trivial step up in performance, both in terms of quality and also speed.
One of the main gripes that I and many other people have had with Codex is its slow speed when compared to other models like Claude 4.5 or GLM 4.6.
With this latest version however, I no longer have the 10+ minute waiting time for the model to finish working, and now instead the average time is around 2-3 minutes for similarly difficult prompts. It manages to do this while still keeping its attention to detail and thoroughness that make it the best model out there right now.
Nano Banana Pro
Gemini was not the only major release Google had this week, as they also dropped an updated version of their popular Nano Banana model.
The new pro version frankly blows ever other image generator and editor out of the water, beating the second best model by over 40 ELO in image editing and 80 ELO in image generation.

Using the LM Arena leaderboard since Artificial Analysis hasn’t released their scores yet. The relative elo values tend to be similar across the two platforms.
The model is built on Gemini 3, so it has great world knowledge. Because it’s based on an LLM, it can also use tools (like search the internet) to get more info for the image it will generate. For instance people have been using it to make detailed infographics of research topics or sports games that happened the previous night. It also can make architecture diagrams based on your code base. It also has limited safety features right now (for better or worse), allowing you to make images of famous politicians and celebrities.
The one downside of the new model is its cost.
The original Nano Banana cost just under $0.04 per image, while the new version is now $0.15 per image, making it one of the pricier image generation models out there.
It can also generate 4K images, similar to Seedream 4, but those will cost double, at $0.30 per image.
I will leave you with a selection of examples from the model, there are also a bunch of examples on Twitter right now if you want to see more.

Prompt: A photo of the sci-fi books I should read — from Fofr

Prompt: Amateur photograph from 1998 of a middle-aged artist copying an image by hand from a computer screen to an oil painting on stretched canvas, but the image is itself the photo of the artist painting the recursive image — from Riley Goodside
Diagram based on a paper — from Anders Sandberg
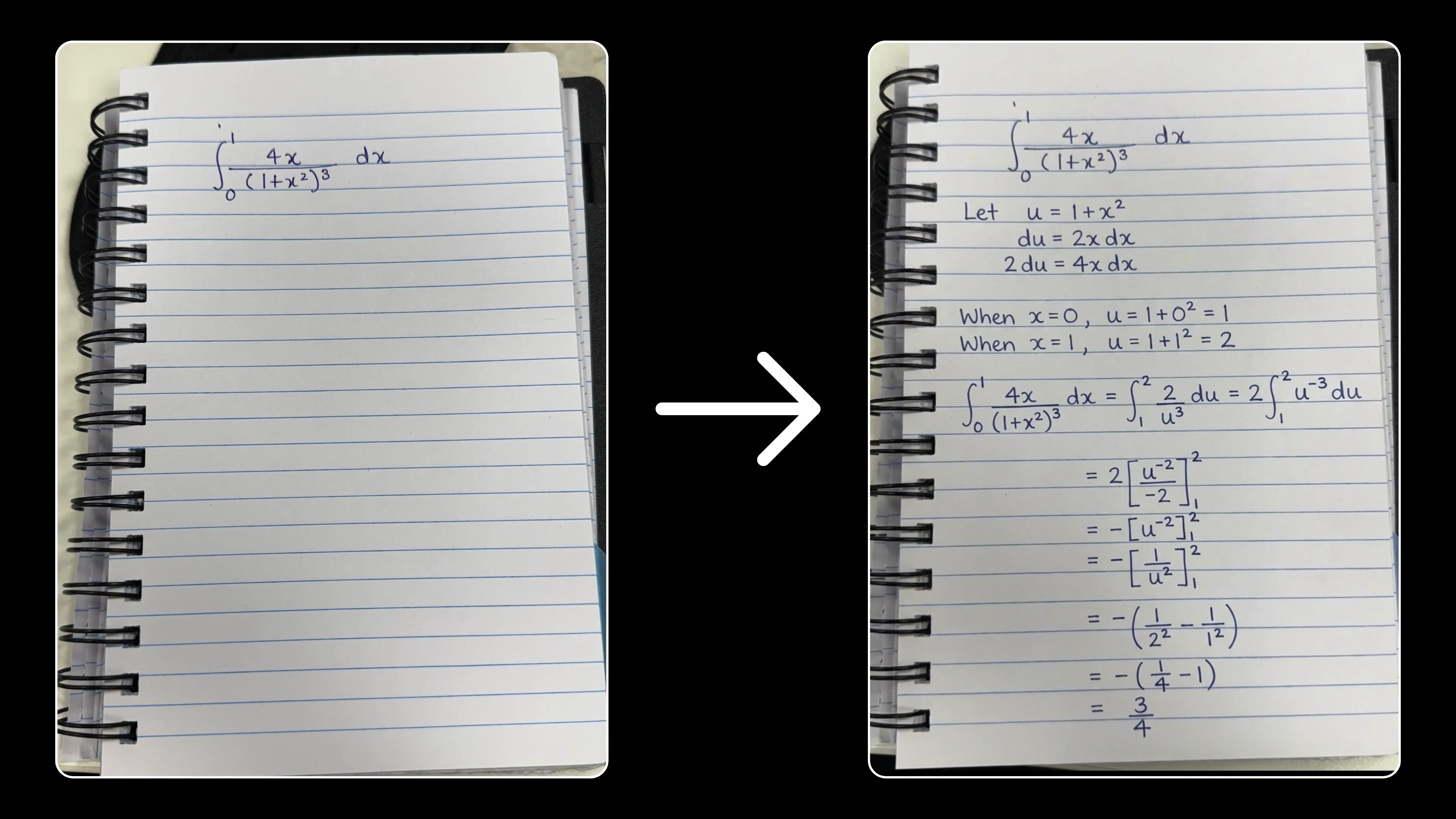
Completing a math problem using the user’s handwriting — from Sid
Research
Hallucination Benchmark
Hallucinations are a big problem with LLM’s, and we have very few public benchmarks that try to measure this.
The gang at Artificial Analysis have noticed this as well, and have released their own benchmark to try and measure this themselves with their AA-Omniscience benchmark.
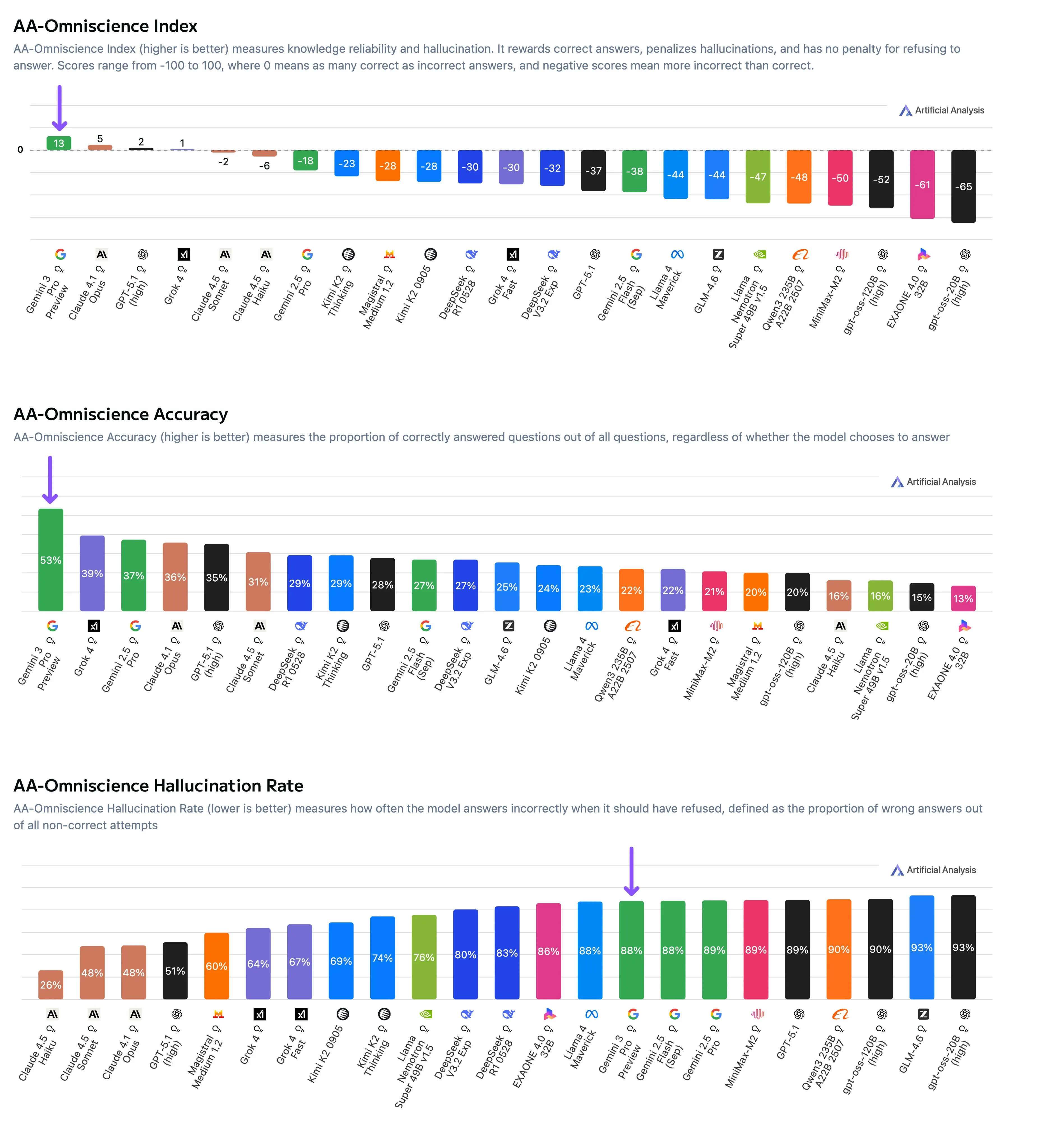
Benchmark results, Gemini 3 highlighted
The benchmark consists of 6000 questions across 6 domains and 42 topics. The models do not get access to any tools, and must answer (or not answer) based on their internal knowledge.
The models are measured across 2 different axes, the first being accuracy, and the second being hallucination rate, which is defined as the model answering a question incorrectly instead of saying “I don’t know”.
These 2 scores are combined together, with a correct answer being worth 1 point, a hallucination being worth -1 points, and not answering a question is worth 0, so a positive score means the model answered correctly more often than it hallucinated.
They found that only 4 models got a positive score, and most models had a hallucination rate over 50%.
The top scoring Gemini 3 rates the highest on the benchmark, not due to its low hallucination rate, but instead its vast world knowledge.
An interesting insight the team found was that for the open source models (where we know the size of the model), the size of the model directly correlated with accuracy, while the hallucination rate did not, which shows that world knowledge in LLMs is a function of size, while hallucinations are based more on the data itself.
This means that small, local models will not have a large amount of world knowledge, but we should still be able to train them to have a low hallucination rate.
Quick Hits
Sam 3(D)
Meta has released a new version of the Segment Anything models (SAM), called SAM 3D.
The release has 2 model types, one for object and scene reconstruction, and another for human body pose and shape estimation.
These models are much heavier weight than the previous SAM 2 models, so they cannot really be used on edge devices or deployed for real time applications.
That being said, they are able to do 3D reconstruction from a 2D image better than any other model out there right now, on top of also being the best 2d segmentation model as well.
Olmo 3
Allen AI, an American open source AI research lab, has released their Olmo 3 series of models.
They are as good as the Qwen3 models, while being fully open in their training, meaning all of the data and checkpoints are public to look at.
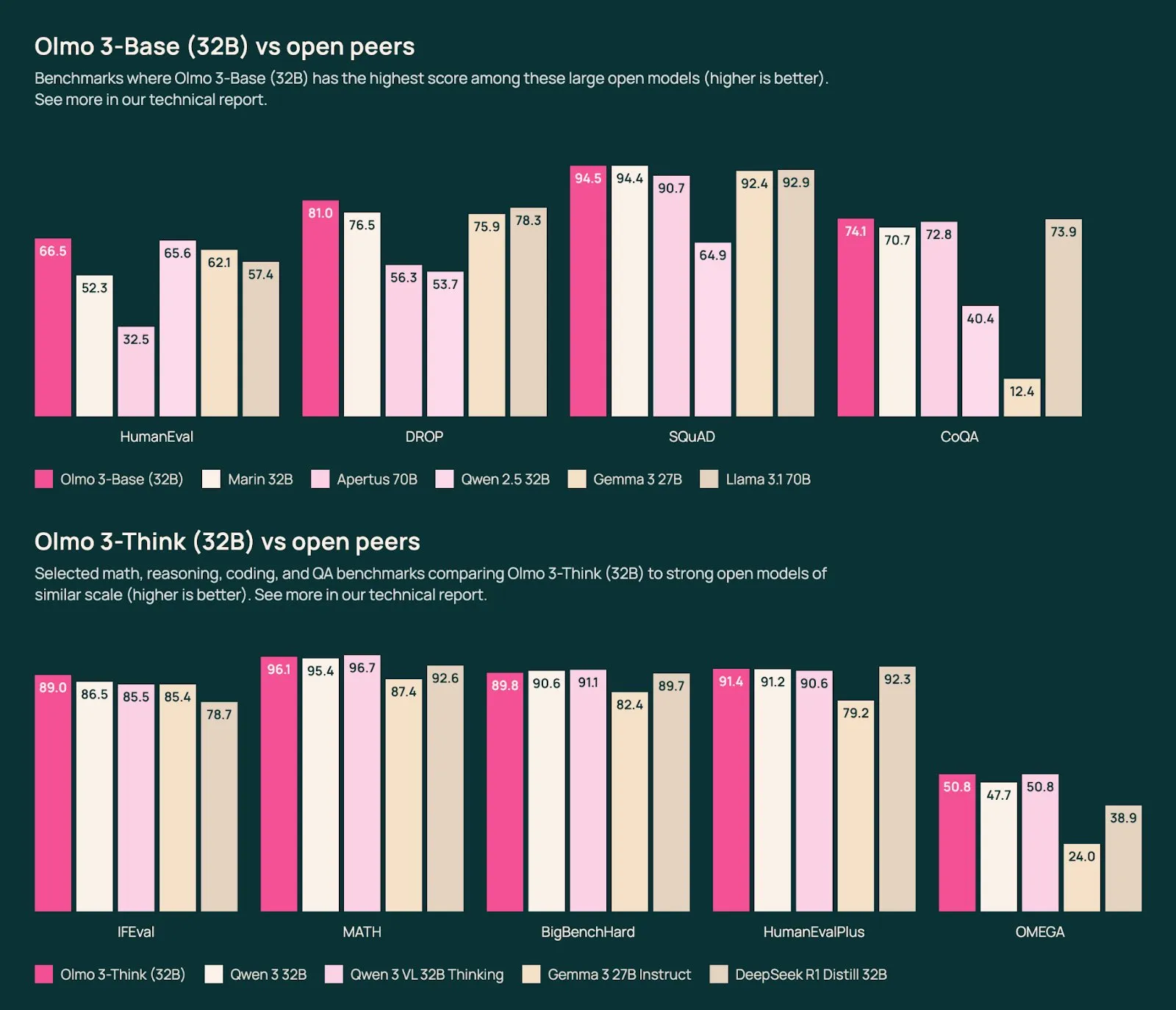
Olmo 3 is able to compete with the frontier models for its size(s)
In a quieter week of AI news this would have a full writeup, so I highly suggest reading more about it if you are interested in frontier model training, or want to run open source models made in the US instead of China.
Also check out the 8B parameter Deep Research model they open sourced which is similar quality to ChatGPT Deep Research.
Misalignment from reward hacking
Anthropic released a blog showing that when a model learns to reward hack in a given RL environment, it causes much broader misalignment for the model as a whole, very similar to what many AI doomers said would happen.
Anthropic then found that this behavior is very easy to mitigate, as you can just adjust the system prompt to avoid broader misalignment.

Top most addendum have best results, bottom the worst
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Gemini 3
O tão aguardado modelo Gemini 3 do Google finalmente chegou.
Uma bela variedade de benchmarks, muito melhor do que vimos nos lançamentos do GPT 5 e Sonnet 4.5
Vamos começar com o lado bom. Em quais categorias o Gemini 3 é definitivamente o melhor?
A primeira e mais evidente é design frontend.
Na arena de design frontend, está 100 ELO acima do próximo melhor modelo.
Exemplo de website feito pelo Gemini 3 do Twitter
A próxima categoria é compreensão multimodal, o que não é surpreendente já que o Gemini 2.5 já era SOTA para isso.
Como o Gemini 2.5, ele pode lidar com entradas de imagem, áudio e vídeo.
OpenAI e Anthropic não parecem muito interessados em capacidades multimodais para seus modelos, permitindo que o Gemini tome facilmente o trono.
A categoria final é conhecimento geral do mundo. Entraremos mais em profundidade sobre isso nas notícias sobre o novo benchmark de alucinação mais adiante, mas essencialmente o conhecimento do mundo parece estar diretamente correlacionado com o tamanho do modelo, o que significa que o Gemini é provavelmente o maior modelo que você pode usar agora.
O Gemini tem a maior consciência do que aconteceu no passado, e seu conhecimento de fatos obscuros também é o melhor de qualquer modelo, muito provavelmente devido aos dados de pré-treinamento que o Google conseguiu reunir para ele, juntamente com seu tamanho muito grande.
Apesar de seu tamanho presumido, é na verdade um modelo bastante rápido, com cerca de o dobro de tokens por segundo que o GPT-5. Isso provavelmente se deve à arquitetura MoE que estão usando, e também potencialmente à diferença de desempenho entre TPUs vs GPUs, mas isso é principalmente especulação, já que não temos como medir o tamanho do modelo subjacente do lado de fora.
Quanto ao preço, fica entre o Sonnet 4.5 e o GPT-5, sendo visivelmente mais rápido que ambos.
| Modelo | $ por milhão (entrada) | $ por milhão (saída) | Tokens por segundo |
|---|
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5 | $1.50 | $10 | 34 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
Isso é via API, diferentemente de Anthropic e OpenAI, o Google fornece uma quantidade decente de uso gratuito através do AIStudio para chat e o Gemini CLI para codificação agêntica. Os limites de taxa específicos para esses ainda não são conhecidos, pois estão sendo lançados agora, mas parecem ser bastante generosos nos meus testes até agora.
Para codificação, o modelo parece ser muito utilizável, aproximadamente no nível do Sonnet 4.5, mas falta a atenção insana aos detalhes que o GPT 5.1 Codex tem. Como mencionei antes, é de longe o melhor modelo por aí para design frontend, então eu o usaria para isso no mínimo.
O modelo é definitivamente ainda um modelo Gemini, pois ainda tem as tendências depressivas que o Gemini 2.5 tinha quando não conseguia resolver um problema, e em geral é um LLM que não tem medo de deixar o usuário saber suas frustrações.
Quanto à maioria de suas outras capacidades, está em torno do nível de fronteira do GPT-5.1 e Sonnet 4.5. Você pode ver esse sentimento nesta thread do Twitter, onde você pode encontrar usuários com opiniões completamente opostas uma da outra para muitas de suas capacidades mais gerais, mostrando que depende mais do prompt e do estilo de saída do que das capacidades diretas do modelo. Falo mais sobre esse fenômeno no final da minha análise do Kimi K2 Thinking se você quiser ler mais sobre isso.
Uma nota final, um dos pesquisadores disse que o aumento nas capacidades do Gemini 3 é apenas devido a melhor pré e pós-treinamento, e não havia nada de muito sofisticado usado para fazer o modelo, mostrando que as leis de escala que temos usado nos últimos anos ainda se mantêm à medida que entramos no reino de LLMs verdadeiramente massivos.
GPT-5.1 Codex Max
Em resposta ao lançamento do Gemini esta semana, a OpenAI lançou uma versão atualizada de seus modelos GPT-5.1 Codex chamada GPT-5.1 Codex Max.
Apesar do nome, não é um único modelo, mas a nova família principal de modelos a serem usados no Codex.
Vem nas variantes usuais de raciocínio baixo, médio ou alto, o que significa que o nome completo de cada modelo é algo como GPT-5.1 Codex Max High (não é um esquema de nomenclatura confuso de jeito nenhum).
Além das variantes de raciocínio usuais, eles também lançaram uma versão de raciocínio extra alto para as tarefas mais difíceis.
O raciocínio médio ainda é recomendado como o padrão a ser usado, e o que eu pessoalmente uso, mas se você achar que o modelo está com dificuldades, pode aumentar para os níveis de raciocínio mais altos usando o comando /model no Codex CLI.
SWE Lancer é um benchmark muito melhor do que o usual SWE Bench Verified. Cobre 1.400 tarefas do mundo real que foram solicitadas no UpWork, e totaliza $1 milhão de dólares em pagamentos.
Apesar da nomenclatura estranha do modelo, este é um aumento não trivial de desempenho, tanto em termos de qualidade quanto de velocidade.
Uma das principais reclamações que eu e muitas outras pessoas tivemos com o Codex é sua velocidade lenta quando comparado a outros modelos como Claude 4.5 ou GLM 4.6.
Com esta versão mais recente, no entanto, não tenho mais o tempo de espera de mais de 10 minutos para o modelo terminar de trabalhar, e agora o tempo médio é de cerca de 2-3 minutos para prompts igualmente difíceis. Ele consegue fazer isso enquanto ainda mantém sua atenção aos detalhes e minuciosidade que o tornam o melhor modelo por aí agora.
Nano Banana Pro
O Gemini não foi o único grande lançamento que o Google teve esta semana, pois eles também lançaram uma versão atualizada de seu popular modelo Nano Banana.
A nova versão pro francamente deixa qualquer outro gerador e editor de imagens para trás, vencendo o segundo melhor modelo por mais de 40 ELO em edição de imagens e 80 ELO em geração de imagens.
Usando a tabela de classificação do LM Arena já que Artificial Analysis ainda não lançou suas pontuações. Os valores relativos de elo tendem a ser similares nas duas plataformas.
O modelo é construído sobre o Gemini 3, então tem ótimo conhecimento do mundo. Por ser baseado em um LLM, ele também pode usar ferramentas (como pesquisar na internet) para obter mais informações para a imagem que vai gerar. Por exemplo, as pessoas têm usado para fazer infográficos detalhados de tópicos de pesquisa ou jogos esportivos que aconteceram na noite anterior. Também pode fazer diagramas de arquitetura baseados em sua base de código. Também tem recursos de segurança limitados agora (para melhor ou pior), permitindo que você faça imagens de políticos famosos e celebridades.
A única desvantagem do novo modelo é seu custo.
O Nano Banana original custava pouco menos de $0.04 por imagem, enquanto a nova versão agora custa $0.15 por imagem, tornando-o um dos modelos de geração de imagem mais caros por aí.
Ele também pode gerar imagens 4K, semelhante ao Seedream 4, mas essas custarão o dobro, a $0.30 por imagem.
Deixarei você com uma seleção de exemplos do modelo, também há vários exemplos no Twitter agora se você quiser ver mais.
Prompt: Uma foto dos livros de ficção científica que eu deveria ler — de Fofr
Prompt: Fotografia amadora de 1998 de um artista de meia-idade copiando uma imagem à mão de uma tela de computador para uma pintura a óleo em tela esticada, mas a imagem é ela própria a foto do artista pintando a imagem recursiva — de Riley Goodside
Diagrama baseado em um artigo — de Anders Sandberg
Completando um problema de matemática usando a caligrafia do usuário — de Sid
Pesquisa
Benchmark de Alucinação
Alucinações são um grande problema com LLMs, e temos muito poucos benchmarks públicos que tentam medir isso.
A turma do Artificial Analysis também notou isso, e lançou seu próprio benchmark para tentar medir isso eles mesmos com seu benchmark AA-Omniscience.
Resultados do benchmark, Gemini 3 destacado
O benchmark consiste em 6000 perguntas em 6 domínios e 42 tópicos. Os modelos não têm acesso a nenhuma ferramenta, e devem responder (ou não responder) com base em seu conhecimento interno.
Os modelos são medidos em 2 eixos diferentes, o primeiro sendo precisão, e o segundo sendo taxa de alucinação, que é definida como o modelo respondendo uma pergunta incorretamente em vez de dizer “Eu não sei”.
Essas 2 pontuações são combinadas, com uma resposta correta valendo 1 ponto, uma alucinação valendo -1 ponto, e não responder uma pergunta vale 0, então uma pontuação positiva significa que o modelo respondeu corretamente mais vezes do que alucinou.
Eles descobriram que apenas 4 modelos obtiveram uma pontuação positiva, e a maioria dos modelos teve uma taxa de alucinação acima de 50%.
O Gemini 3, com a maior pontuação, classifica-se no topo do benchmark, não devido à sua baixa taxa de alucinação, mas sim ao seu vasto conhecimento do mundo.
Uma percepção interessante que a equipe encontrou foi que para os modelos de código aberto (onde conhecemos o tamanho do modelo), o tamanho do modelo correlacionou-se diretamente com a precisão, enquanto a taxa de alucinação não, o que mostra que o conhecimento do mundo em LLMs é uma função do tamanho, enquanto as alucinações são baseadas mais nos dados em si.
Isso significa que modelos pequenos e locais não terão uma grande quantidade de conhecimento do mundo, mas ainda deveríamos ser capazes de treiná-los para ter uma baixa taxa de alucinação.
Destaques Rápidos
Sam 3(D)
A Meta lançou uma nova versão dos modelos Segment Anything (SAM), chamada SAM 3D.
O lançamento tem 2 tipos de modelo, um para reconstrução de objetos e cenas, e outro para estimativa de pose e forma do corpo humano.
Esses modelos são muito mais pesados que os modelos SAM 2 anteriores, então eles realmente não podem ser usados em dispositivos de borda ou implantados para aplicações em tempo real.
Dito isso, eles são capazes de fazer reconstrução 3D a partir de uma imagem 2D melhor do que qualquer outro modelo por aí agora, além de também serem o melhor modelo de segmentação 2D também.
Olmo 3
Allen AI, um laboratório americano de pesquisa em IA de código aberto, lançou sua série de modelos Olmo 3.
Eles são tão bons quanto os modelos Qwen3, sendo totalmente abertos em seu treinamento, o que significa que todos os dados e checkpoints são públicos para visualização.
Olmo 3 é capaz de competir com os modelos de fronteira para seu(s) tamanho(s)
Em uma semana mais calma de notícias de IA, isso teria uma análise completa, então eu recomendo fortemente ler mais sobre isso se você estiver interessado em treinamento de modelos de fronteira, ou quiser executar modelos de código aberto feitos nos EUA em vez da China.
Também confira o modelo Deep Research de 8B parâmetros que eles lançaram em código aberto, que é de qualidade similar ao ChatGPT Deep Research.
Desalinhamento por exploração de recompensa
A Anthropic lançou um blog mostrando que quando um modelo aprende a explorar recompensas em um determinado ambiente de RL, isso causa um desalinhamento muito mais amplo para o modelo como um todo, muito similar ao que muitos pessimistas da IA disseram que aconteceria.
A Anthropic então descobriu que esse comportamento é muito fácil de mitigar, pois você pode simplesmente ajustar o prompt do sistema para evitar um desalinhamento mais amplo.
Os adendos superiores têm os melhores resultados, os inferiores os piores
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, certifique-se de se juntar à nossa lista de e-mails abaixo.
Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Gemini 3
El tan esperado modelo Gemini 3 de Google finalmente está aquí.
Una excelente selección de benchmarks, mucho mejor que lo que hemos visto en los lanzamientos de GPT 5 y Sonnet 4.5
Comencemos con lo bueno. ¿En qué categorías es Gemini 3 definitivamente el mejor?
La primera y más evidente es el diseño frontend.
En la arena de diseño frontend, está 100 ELO completo por encima del siguiente mejor modelo.
Ejemplo de sitio web hecho por Gemini 3 de Twitter
La siguiente categoría es comprensión multimodal, lo cual no es sorprendente ya que Gemini 2.5 ya era SOTA para esto.
Al igual que Gemini 2.5, puede manejar entradas de imagen, audio y video.
OpenAI y Anthropic no parecen muy interesados en capacidades multimodales para sus modelos, permitiendo que Gemini tome fácilmente el trono.
La categoría final es conocimiento general del mundo. Profundizaremos más en esto en las noticias del nuevo benchmark de alucinaciones más adelante, pero esencialmente el conocimiento del mundo parece estar directamente correlacionado con el tamaño del modelo, lo que significa que Gemini es muy probablemente el modelo más grande que puedes usar en este momento.
Gemini tiene la mayor conciencia de lo que ha sucedido en el pasado, y también su conocimiento de hechos oscuros es también el mejor de cualquier modelo, muy probablemente debido a los datos de preentrenamiento que Google ha podido reunir para él junto con su tamaño muy grande.
A pesar de su supuesto tamaño, en realidad es un modelo bastante rápido, con aproximadamente el doble de tokens por segundo que GPT-5. Esto se debe probablemente a la arquitectura MoE que están usando, y también potencialmente la diferencia de rendimiento de TPUs vs GPUs, pero eso es principalmente especulación ya que no tenemos forma de medir el tamaño del modelo subyacente desde el exterior.
En cuanto a precios, se sitúa entre Sonnet 4.5 y GPT-5, siendo notablemente más rápido que ambos.
| Modelo | $ por millón (entrada) | $ por millón (salida) | Tokens por segundo |
|---|
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5 | $1.50 | $10 | 34 |
| Gemini 3 Pro Preview | $2 | $12 | 80 |
Esto es a través de la API, a diferencia de Anthropic y OpenAI, Google ofrece una cantidad decente de uso gratuito a través de AIStudio para chatear y el Gemini CLI para codificación agéntica. Los límites de tasa específicos para estos aún no se conocen ya que apenas se están lanzando, pero parecen ser bastante generosos en mis pruebas hasta ahora.
Para codificación, el modelo parece ser muy utilizable, alrededor del nivel de Sonnet 4.5, pero le falta la atención increíble al detalle que tiene GPT 5.1 Codex. Como mencioné antes, es por lejos el mejor modelo para diseño frontend, así que lo usaría para eso como mínimo.
El modelo definitivamente sigue siendo un modelo Gemini, ya que todavía tiene las tendencias depresivas que tenía Gemini 2.5 cuando no podía resolver un problema, y en general es un LLM que no tiene miedo de hacerle saber al usuario sus frustraciones.
En cuanto a la mayoría de sus otras capacidades, está alrededor del nivel fronterizo de GPT-5.1 y Sonnet 4.5. Puedes ver este sentimiento en este hilo de Twitter, donde puedes encontrar usuarios con opiniones completamente opuestas entre sí para muchas de sus capacidades más generales, mostrando que depende del prompt y el estilo de salida más que de las capacidades directas del modelo. Hablo más sobre este fenómeno al final de mi revisión de Kimi K2 Thinking si quieres leer más al respecto.
Una nota final, uno de los investigadores dijo que el aumento en capacidades para Gemini 3 se debe solo a mejor pre y post-entrenamiento, y no se usó nada especialmente sofisticado para hacer el modelo, mostrando que las leyes de escalado que hemos estado usando en los últimos años aún se mantienen a medida que entramos al reino de LLMs verdaderamente masivos.
GPT-5.1 Codex Max
En respuesta al lanzamiento de Gemini esta semana, OpenAI lanzó una versión actualizada de sus modelos GPT-5.1 Codex llamada GPT-5.1 Codex Max.
A pesar del nombre, no es un solo modelo sino la nueva familia insignia de modelos para ser usados en Codex.
Viene en las variantes habituales de razonamiento bajo, medio o alto, lo que significa que el nombre completo de cada modelo es algo como GPT-5.1 Codex Max High (nada confuso como esquema de nomenclatura).
Además de las variantes de razonamiento habituales, también lanzaron una versión de razonamiento extra alto para las tareas más difíciles.
El razonamiento medio todavía se recomienda como el predeterminado, y es lo que yo personalmente uso, pero si encuentras que el modelo tiene dificultades puedes aumentarlo a los niveles de razonamiento más altos usando el comando /model en el Codex CLI.
SWE Lancer es un benchmark mucho mejor que el habitual SWE Bench Verified. Cubre 1,400 tareas del mundo real que fueron solicitadas en UpWork, y totaliza $1 millón de dólares en pagos.
A pesar del extraño nombre del modelo, este es un salto no trivial en rendimiento, tanto en términos de calidad como de velocidad.
Una de las principales quejas que yo y muchas otras personas hemos tenido con Codex es su velocidad lenta en comparación con otros modelos como Claude 4.5 o GLM 4.6.
Sin embargo, con esta última versión, ya no tengo el tiempo de espera de más de 10 minutos para que el modelo termine de trabajar, y ahora en su lugar el tiempo promedio es de alrededor de 2-3 minutos para prompts igualmente difíciles. Logra hacer esto mientras mantiene su atención al detalle y minuciosidad que lo convierten en el mejor modelo disponible en este momento.
Nano Banana Pro
Gemini no fue el único lanzamiento importante que Google tuvo esta semana, ya que también lanzaron una versión actualizada de su popular modelo Nano Banana.
La nueva versión pro francamente supera a cualquier otro generador y editor de imágenes, venciendo al segundo mejor modelo por más de 40 ELO en edición de imágenes y 80 ELO en generación de imágenes.
Usando la tabla de clasificación de LM Arena ya que Artificial Analysis aún no ha publicado sus puntajes. Los valores de ELO relativos tienden a ser similares en ambas plataformas.
El modelo está construido sobre Gemini 3, por lo que tiene un gran conocimiento del mundo. Debido a que está basado en un LLM, también puede usar herramientas (como buscar en internet) para obtener más información para la imagen que generará. Por ejemplo, la gente lo ha estado usando para hacer infografías detalladas de temas de investigación o juegos deportivos que ocurrieron la noche anterior. También puede hacer diagramas de arquitectura basados en tu código base. También tiene características de seguridad limitadas en este momento (para bien o para mal), permitiéndote hacer imágenes de políticos famosos y celebridades.
La única desventaja del nuevo modelo es su costo.
El Nano Banana original costaba poco menos de $0.04 por imagen, mientras que la nueva versión ahora es $0.15 por imagen, convirtiéndolo en uno de los modelos de generación de imágenes más costosos disponibles.
También puede generar imágenes 4K, similar a Seedream 4, pero esas costarán el doble, a $0.30 por imagen.
Los dejaré con una selección de ejemplos del modelo, también hay un montón de ejemplos en Twitter ahora mismo si quieres ver más.
Prompt: Una foto de los libros de ciencia ficción que debería leer — de Fofr
Prompt: Fotografía amateur de 1998 de un artista de mediana edad copiando a mano una imagen de la pantalla de una computadora a una pintura al óleo sobre lienzo estirado, pero la imagen es en sí misma la foto del artista pintando la imagen recursiva — de Riley Goodside
Diagrama basado en un artículo científico — de Anders Sandberg
Completando un problema de matemáticas usando la escritura a mano del usuario — de Sid
Investigación
Benchmark de Alucinaciones
Las alucinaciones son un gran problema con los LLMs, y tenemos muy pocos benchmarks públicos que intenten medir esto.
El equipo de Artificial Analysis también ha notado esto, y han lanzado su propio benchmark para intentar medirlo ellos mismos con su benchmark AA-Omniscience.
Resultados del benchmark, Gemini 3 destacado
El benchmark consiste en 6000 preguntas en 6 dominios y 42 temas. Los modelos no tienen acceso a ninguna herramienta, y deben responder (o no responder) basándose en su conocimiento interno.
Los modelos se miden en 2 ejes diferentes, el primero siendo precisión, y el segundo siendo tasa de alucinación, que se define como el modelo respondiendo una pregunta incorrectamente en lugar de decir “No lo sé”.
Estos 2 puntajes se combinan juntos, con una respuesta correcta valiendo 1 punto, una alucinación valiendo -1 puntos, y no responder una pregunta vale 0, por lo que un puntaje positivo significa que el modelo respondió correctamente más a menudo de lo que alucinó.
Encontraron que solo 4 modelos obtuvieron un puntaje positivo, y la mayoría de los modelos tenían una tasa de alucinación superior al 50%.
El Gemini 3 de mayor puntaje se clasifica más alto en el benchmark, no debido a su baja tasa de alucinación, sino a su vasto conocimiento del mundo.
Un hallazgo interesante que el equipo encontró fue que para los modelos de código abierto (donde conocemos el tamaño del modelo), el tamaño del modelo se correlacionó directamente con la precisión, mientras que la tasa de alucinación no lo hizo, lo que muestra que el conocimiento del mundo en los LLMs es una función del tamaño, mientras que las alucinaciones se basan más en los datos en sí.
Esto significa que los modelos pequeños y locales no tendrán una gran cantidad de conocimiento del mundo, pero aún deberíamos poder entrenarlos para tener una tasa de alucinación baja.
Noticias Breves
Sam 3(D)
Meta ha lanzado una nueva versión de los modelos Segment Anything (SAM), llamada SAM 3D.
El lanzamiento tiene 2 tipos de modelos, uno para reconstrucción de objetos y escenas, y otro para estimación de pose y forma del cuerpo humano.
Estos modelos son mucho más pesados que los modelos SAM 2 anteriores, por lo que realmente no pueden usarse en dispositivos edge o desplegarse para aplicaciones en tiempo real.
Dicho esto, son capaces de hacer reconstrucción 3D a partir de una imagen 2D mejor que cualquier otro modelo disponible en este momento, además de ser también el mejor modelo de segmentación 2D.
Olmo 3
Allen AI, un laboratorio de investigación de IA de código abierto estadounidense, ha lanzado su serie de modelos Olmo 3.
Son tan buenos como los modelos Qwen3, siendo completamente abiertos en su entrenamiento, lo que significa que todos los datos y puntos de control son públicos para consultar.
Olmo 3 es capaz de competir con los modelos fronterizos para su(s) tamaño(s)
En una semana más tranquila de noticias de IA esto tendría un artículo completo, así que sugiero encarecidamente leer más al respecto si estás interesado en el entrenamiento de modelos fronterizos, o quieres ejecutar modelos de código abierto hechos en EE.UU. en lugar de China.
También revisa el modelo Deep Research de 8B parámetros que abrieron como código abierto, que es de calidad similar a ChatGPT Deep Research.
Desalineación por hackeo de recompensas
Anthropic publicó un blog mostrando que cuando un modelo aprende a hackear recompensas en un entorno de RL dado, causa una desalineación mucho más amplia para el modelo en su conjunto, muy similar a lo que muchos pesimistas de IA dijeron que sucedería.
Anthropic luego encontró que este comportamiento es muy fácil de mitigar, ya que simplemente puedes ajustar el prompt del sistema para evitar una desalineación más amplia.
Los apéndices superiores tienen mejores resultados, los inferiores los peores
Final
Espero que hayan disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.