Releases
Gemini 3 Flash
Google has released the smaller, cheaper, faster version of their Gemini 3 Pro model, Gemini 3 Flash.
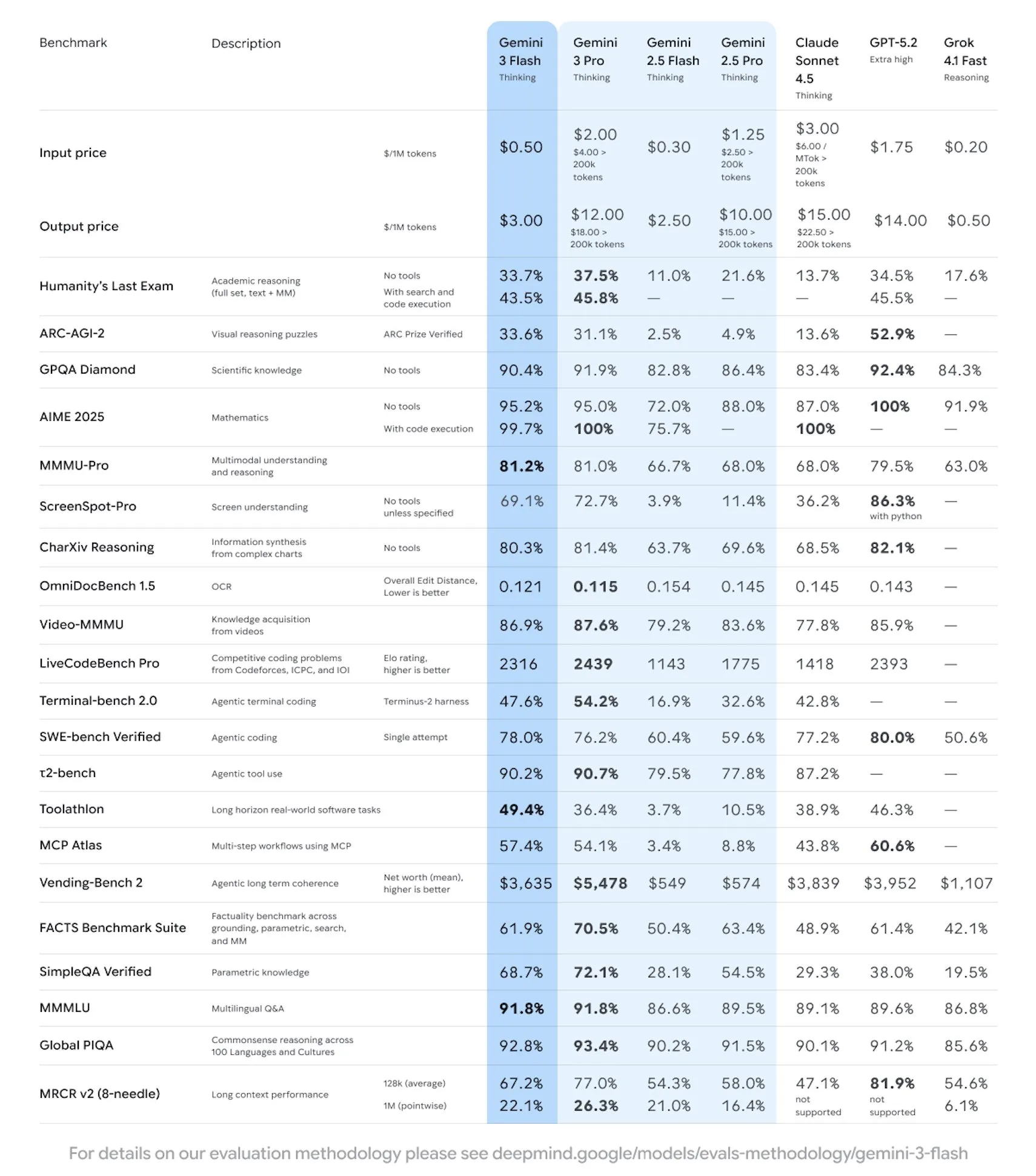
It is a strong model, especially given its pricing. For most tasks it will be passable, if not equal to many of the top models out there right now.
It is on the Pareto frontier for intelligence per dollar.
If you are looking for an alternative to the cheap Chinese LLM’s this is a great option to look at, as it seems to be just as good if not better across the board.
For coding it is definitely usable for easy and maybe even medium difficulty tasks.
You may notice in some of the coding benchmarks it actually outdoes Gemini 3 Pro.
According to the team at Google, this is because they were able to spend more time RL’ing the model before release.
This does not seem to translate to real world performance however, and is just a bit of benchmaxxing.
| Model | $ per million (input) | $ per million (output) | Tokens per second |
|---|
| GLM 4.6 | $0.60 | $2.20 | 90 |
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5.2 | $1.75 | $14 | 34 |
| Kimi K2 Thinking | $0.6 | $2.50 | 25 |
| Gemini 3 Pro | $2 | $12 | 80 |
| Gemini 3 Flash | $0.50 | $3 | 75 |
Numbers from OpenRouter. I am unsure why Gemini 3 Flash is listed as slower than Gemini 3 Pro. According to Artificial Analysis it should be 35% faster.
Overall a very solid model that I would check out if you are looking for a good quality LLM that is fast and cheap.
Nemotron 3 Nano
Nvidia has been turning up the open source releases as of late, releasing the first model in their new Nemotron 3 series.
The model is the smallest in the family, called Nemotron 3 Nano and is a mixture of experts model with 30 billion parameters with 3 billion active, putting it at the same size as the Qwen3 30B model.
Where it differs from its Qwen3 counterpart is its architecture. Instead of using the usual transformer layers with quadratic attention, it is using a linear variant called Mamba-2, which allows it to have much better speeds as the sequence length increases.
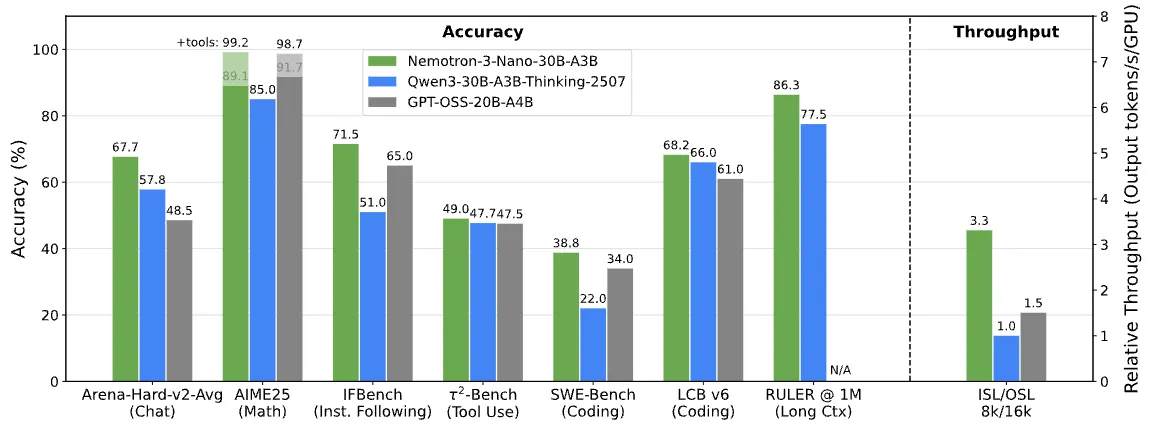
For the throughput numbers, ISL is input sequence length (how many tokens are in the prompt) and OSL is output sequence length (how many tokens the model generated)
Unlike the Qwen models, which only have the model open sourced, but none of the training infrastructure or data, Nemotron 3 has everything available, including the pretraining data, supervised finetuning data, and reinforcement learning environments.
In the real world, people seem to prefer Nemotron over Qwen, which was the previous best model for its size.
This is also reflected in some of the internal benchmarks I have been making (official release coming soon), as it has almost triple the real world knowledge that Qwen 30B has.
If you run models at home, I would definitely recommend checking out this model if you haven’t already.
Also expect releases of its two bigger brothers in the near future, which will be ~120 billion and ~480 billion parameters each.
GPT 5.2 Codex
OpenAI has released the coding focused version of their GPT 5.2 model.
It is finetuned specifically for using their Codex coding framework, hence the name GPT 5.2 Codex.
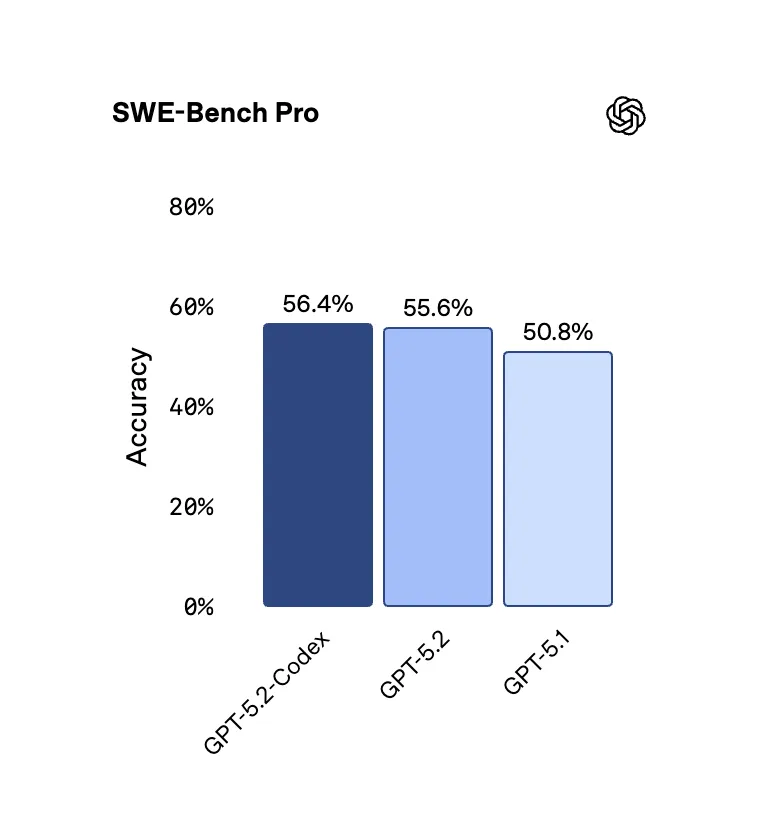
There is not much that stands out about the model on the benchmark side of things.
It is most likely just more reliable in the Codex harness than they have for it.
For GPT 5.2, what I have been seeing people say is that it excels for very hard tasks, but for day to day coding it is slow and depending on the task still may not be better than Opus 4.5.
I recently have switched to Opus 4.5 on the Claude Max plan ($100/month) and have yet to run into anything that Opus was unable to crush in one or two prompts for me.
Quick Hits
SOTA Open Source TTS
The open source TTS community has been falling behind companies like ElevenLabs, especially when it comes to voice cloning.
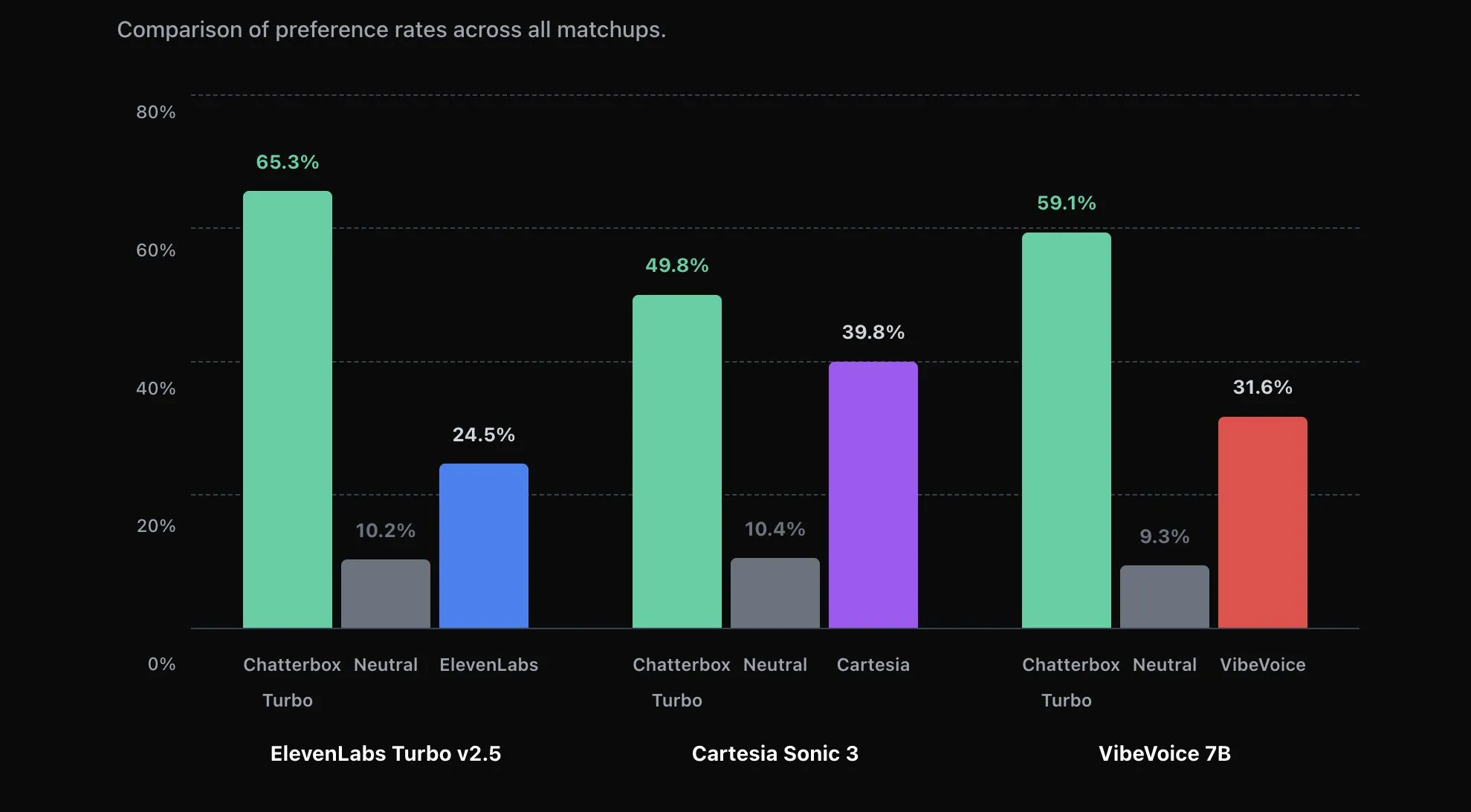
We no longer have that issue as Resemble AI has released their Chatterbox Turbo TTS model.
It is an MIT licensed open source model that can do voice cloning off of just 5 seconds of audio, has better performance that Eleven Labs Turbo v2.5, and has 150ms time to first utterance.
I used it to clone my own voice on Huggingface and it did a very good job. It is definitely far above any other open source model I have used, and is just as good as Eleven Labs v3 was for cloning my voice.
Qwen Image Layered
When has released an interesting new image model based on their Qwen Image and Edit lineup.
This model is a layer decomposition model, which allows you to take your reference image and split into multiple layers for you to edit like you would in Photoshop.
The model can then be used to edit each layer for you as well, similar to Qwen Image Edit, giving you much more fine grained control over your images.
Like the other Qwen Image models, it is open source under an Apache 2 license.
Claude Code can use Chrome
A small quality of life improvement for those using Claude Code.
If you run the /chrome command, you can set up Claude to be able to use Chrome directly using an extension, which will allow it to view and debug frontend issues all by itself.
Function Gemma
Alongside the Gemini 3 Flash release, Google also released a small 270 million parameter model called Function Gemma that has been trained specifically for function calling.
You are meant to finetune it for your specific task, since it is not a very general model given its small size.
Its size does allow it to be deployed pretty much anywhere and will be able to run faster than pretty much any other edge LLM out there.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Algorithmic art by yuruyurau on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Gemini 3 Flash
O Google lançou a versão menor, mais barata e mais rápida do seu modelo Gemini 3 Pro, Gemini 3 Flash.
É um modelo robusto, especialmente considerando seu preço. Para a maioria das tarefas será aceitável, se não igual a muitos dos principais modelos disponíveis atualmente.
Ele está na fronteira de Pareto para inteligência por dólar.
Se você está procurando uma alternativa aos LLMs chineses baratos, esta é uma ótima opção para considerar, pois parece ser tão bom ou até melhor em todos os aspectos.
Para programação, é definitivamente utilizável para tarefas fáceis e talvez até de dificuldade média.
Você pode notar em alguns dos benchmarks de programação que ele realmente supera o Gemini 3 Pro.
De acordo com a equipe do Google, isso ocorre porque eles conseguiram dedicar mais tempo ao RL do modelo antes do lançamento.
No entanto, isso não parece se traduzir em desempenho no mundo real, sendo apenas um pouco de benchmaxxing.
| Model | $ por milhão (entrada) | $ por milhão (saída) | Tokens por segundo |
|---|
| GLM 4.6 | $0.60 | $2.20 | 90 |
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5.2 | $1.75 | $14 | 34 |
| Kimi K2 Thinking | $0.6 | $2.50 | 25 |
| Gemini 3 Pro | $2 | $12 | 80 |
| Gemini 3 Flash | $0.50 | $3 | 75 |
Números do OpenRouter. Não tenho certeza do porquê o Gemini 3 Flash está listado como mais lento que o Gemini 3 Pro. De acordo com Artificial Analysis, ele deveria ser 35% mais rápido.
No geral, um modelo muito sólido que eu recomendaria verificar se você está procurando um LLM de boa qualidade que seja rápido e barato.
Nemotron 3 Nano
A Nvidia tem intensificado os lançamentos open source recentemente, lançando o primeiro modelo da sua nova série Nemotron 3.
O modelo é o menor da família, chamado Nemotron 3 Nano e é um modelo mixture of experts com 30 bilhões de parâmetros com 3 bilhões ativos, colocando-o no mesmo tamanho do modelo Qwen3 30B.
Onde ele difere de sua contraparte Qwen3 é em sua arquitetura. Em vez de usar as camadas transformer usuais com atenção quadrática, ele está usando uma variante linear chamada Mamba-2, que permite ter velocidades muito melhores à medida que o comprimento da sequência aumenta.
Para os números de throughput, ISL é input sequence length (quantos tokens estão no prompt) e OSL é output sequence length (quantos tokens o modelo gerou)
Ao contrário dos modelos Qwen, que apenas têm o modelo open source, mas nenhuma infraestrutura de treinamento ou dados, o Nemotron 3 tem tudo disponível, incluindo os dados de pré-treinamento, dados de ajuste fino supervisionado e ambientes de aprendizado por reforço.
No mundo real, as pessoas parecem preferir o Nemotron sobre o Qwen, que era o melhor modelo anterior para esse tamanho.
Isso também se reflete em alguns dos benchmarks internos que tenho feito (lançamento oficial em breve), pois ele tem quase o triplo do conhecimento do mundo real que o Qwen 30B possui.
Se você roda modelos em casa, eu definitivamente recomendaria verificar este modelo se ainda não o fez.
Também espere lançamentos de seus dois irmãos maiores em um futuro próximo, que terão ~120 bilhões e ~480 bilhões de parâmetros cada.
GPT 5.2 Codex
A OpenAI lançou a versão focada em programação do seu modelo GPT 5.2.
Ele é ajustado especificamente para usar seu framework de programação Codex, daí o nome GPT 5.2 Codex.
Não há muito que se destaque sobre o modelo no lado dos benchmarks.
É muito provável que seja apenas mais confiável no harness Codex do que eles têm para ele.
Para o GPT 5.2, o que tenho visto as pessoas dizerem é que ele se destaca para tarefas muito difíceis, mas para programação do dia a dia é lento e, dependendo da tarefa, ainda pode não ser melhor que o Opus 4.5.
Recentemente mudei para o Opus 4.5 no plano Claude Max ($100/mês) e ainda não encontrei nada que o Opus não conseguisse resolver em um ou dois prompts para mim.
Destaques Rápidos
TTS Open Source SOTA
A comunidade de TTS open source tem ficado para trás de empresas como ElevenLabs, especialmente quando se trata de clonagem de voz.
Não temos mais esse problema, pois a Resemble AI lançou seu modelo TTS Chatterbox Turbo.
É um modelo open source licenciado MIT que pode fazer clonagem de voz com apenas 5 segundos de áudio, tem melhor desempenho que o Eleven Labs Turbo v2.5, e tem 150ms de tempo até a primeira pronúncia.
Eu o usei para clonar minha própria voz no Huggingface e fez um trabalho muito bom. Definitivamente está muito acima de qualquer outro modelo open source que já usei, e é tão bom quanto o Eleven Labs v3 foi para clonar minha voz.
Qwen Image Layered
A Qwen lançou um novo modelo de imagem interessante baseado em sua linha Qwen Image and Edit.
Este modelo é um modelo de decomposição em camadas, que permite pegar sua imagem de referência e dividi-la em múltiplas camadas para você editar como faria no Photoshop.
O modelo pode então ser usado para editar cada camada para você também, semelhante ao Qwen Image Edit, dando-lhe controle muito mais refinado sobre suas imagens.
Como os outros modelos Qwen Image, é open source sob uma licença Apache 2.
Claude Code pode usar Chrome
Uma pequena melhoria de qualidade de vida para aqueles que usam Claude Code.
Se você executar o comando /chrome, pode configurar o Claude para usar o Chrome diretamente usando uma extensão, o que permitirá que ele visualize e depure problemas de frontend sozinho.
Function Gemma
Juntamente com o lançamento do Gemini 3 Flash, o Google também lançou um pequeno modelo de 270 milhões de parâmetros chamado Function Gemma que foi treinado especificamente para chamadas de função.
Você deve fazer o ajuste fino dele para sua tarefa específica, já que não é um modelo muito geral dado seu tamanho pequeno.
Seu tamanho permite que seja implantado praticamente em qualquer lugar e será capaz de rodar mais rápido que praticamente qualquer outro LLM de edge por aí.
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, certifique-se de se inscrever em nossa lista de e-mails abaixo.
Arte algorítmica por yuruyurau no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Gemini 3 Flash
Google ha lanzado la versión más pequeña, económica y rápida de su modelo Gemini 3 Pro, Gemini 3 Flash.
Es un modelo sólido, especialmente teniendo en cuenta su precio. Para la mayoría de tareas será aceptable, si no igual a muchos de los mejores modelos disponibles en este momento.
Se encuentra en la frontera de Pareto en términos de inteligencia por dólar.
Si estás buscando una alternativa a los LLMs chinos económicos, esta es una excelente opción a considerar, ya que parece ser igual de bueno o mejor en todos los aspectos.
Para programación es definitivamente utilizable para tareas fáciles e incluso de dificultad media.
Puede que notes en algunos de los benchmarks de programación que supera a Gemini 3 Pro.
Según el equipo de Google, esto se debe a que pudieron dedicar más tiempo al entrenamiento por refuerzo (RL) del modelo antes del lanzamiento.
Sin embargo, esto no parece traducirse al rendimiento en el mundo real, y es solo un poco de optimización para benchmarks.
| Modelo | $ por millón (entrada) | $ por millón (salida) | Tokens por segundo |
|---|
| GLM 4.6 | $0.60 | $2.20 | 90 |
| Claude Sonnet 4.5 | $3 | $15 | 57 |
| GPT 5.2 | $1.75 | $14 | 34 |
| Kimi K2 Thinking | $0.6 | $2.50 | 25 |
| Gemini 3 Pro | $2 | $12 | 80 |
| Gemini 3 Flash | $0.50 | $3 | 75 |
Números de OpenRouter. No estoy seguro de por qué Gemini 3 Flash aparece como más lento que Gemini 3 Pro. Según Artificial Analysis debería ser un 35% más rápido.
En general, un modelo muy sólido que recomendaría revisar si estás buscando un LLM de buena calidad que sea rápido y económico.
Nemotron 3 Nano
Nvidia ha estado aumentando sus lanzamientos de código abierto últimamente, publicando el primer modelo de su nueva serie Nemotron 3.
El modelo es el más pequeño de la familia, llamado Nemotron 3 Nano y es un modelo de mezcla de expertos con 30 mil millones de parámetros con 3 mil millones activos, ubicándolo en el mismo tamaño que el modelo Qwen3 30B.
Donde difiere de su contraparte Qwen3 es en su arquitectura. En lugar de usar las capas de transformador habituales con atención cuadrática, está usando una variante lineal llamada Mamba-2, que le permite tener velocidades mucho mejores a medida que aumenta la longitud de la secuencia.
Para los números de rendimiento, ISL es la longitud de secuencia de entrada (cuántos tokens hay en el prompt) y OSL es la longitud de secuencia de salida (cuántos tokens generó el modelo)
A diferencia de los modelos Qwen, que solo tienen el modelo de código abierto, pero ninguna de la infraestructura de entrenamiento o datos, Nemotron 3 tiene todo disponible, incluyendo los datos de preentrenamiento, datos de ajuste fino supervisado y entornos de aprendizaje por refuerzo.
En el mundo real, la gente parece preferir Nemotron sobre Qwen, que era el mejor modelo anterior para su tamaño.
Esto también se refleja en algunos de los benchmarks internos que he estado haciendo (lanzamiento oficial próximamente), ya que tiene casi el triple del conocimiento del mundo real que tiene Qwen 30B.
Si ejecutas modelos en casa, definitivamente recomendaría revisar este modelo si aún no lo has hecho.
También espera lanzamientos de sus dos hermanos mayores en un futuro cercano, que tendrán ~120 mil millones y ~480 mil millones de parámetros cada uno.
GPT 5.2 Codex
OpenAI ha lanzado la versión enfocada en programación de su modelo GPT 5.2.
Está ajustado específicamente para usar su framework de programación Codex, de ahí el nombre GPT 5.2 Codex.
No hay mucho que destaque sobre el modelo en el lado de los benchmarks.
Lo más probable es que sea simplemente más confiable en el harness de Codex que tienen para él.
Para GPT 5.2, lo que he visto que la gente dice es que sobresale para tareas muy difíciles, pero para programación del día a día es lento y dependiendo de la tarea puede que aún no sea mejor que Opus 4.5.
Recientemente he cambiado a Opus 4.5 en el plan Claude Max ($100/mes) y aún no me he encontrado con nada que Opus no pudiera resolver para mí en uno o dos prompts.
Noticias Rápidas
TTS de Código Abierto que Alcanza el Estado del Arte
La comunidad de TTS de código abierto se había estado quedando atrás de empresas como ElevenLabs, especialmente cuando se trata de clonación de voz.
Ya no tenemos ese problema ya que Resemble AI ha lanzado su modelo TTS Chatterbox Turbo.
Es un modelo de código abierto con licencia MIT que puede hacer clonación de voz con solo 5 segundos de audio, tiene mejor rendimiento que Eleven Labs Turbo v2.5, y tiene 150ms de tiempo hasta la primera emisión.
Lo usé para clonar mi propia voz en Huggingface e hizo un muy buen trabajo. Definitivamente está muy por encima de cualquier otro modelo de código abierto que haya usado, y es tan bueno como Eleven Labs v3 para clonar mi voz.
Qwen Image Layered
Qwen ha lanzado un nuevo e interesante modelo de imagen basado en su línea Qwen Image and Edit.
Este modelo es un modelo de descomposición de capas, que te permite tomar tu imagen de referencia y dividirla en múltiples capas para que las edites como lo harías en Photoshop.
El modelo puede entonces ser usado para editar cada capa por ti también, similar a Qwen Image Edit, dándote un control mucho más fino sobre tus imágenes.
Como los otros modelos Qwen Image, es de código abierto bajo una licencia Apache 2.
Claude Code puede usar Chrome
Una pequeña mejora de calidad de vida para quienes usan Claude Code.
Si ejecutas el comando /chrome, puedes configurar a Claude para que pueda usar Chrome directamente usando una extensión, lo que le permitirá ver y depurar problemas de frontend por sí mismo.
Function Gemma
Junto con el lanzamiento de Gemini 3 Flash, Google también lanzó un pequeño modelo de 270 millones de parámetros llamado Function Gemma que ha sido entrenado específicamente para llamadas a funciones.
Está destinado a que lo ajustes para tu tarea específica, ya que no es un modelo muy general dado su pequeño tamaño.
Su tamaño le permite ser desplegado prácticamente en cualquier lugar y podrá ejecutarse más rápido que prácticamente cualquier otro LLM de edge disponible.
Finalización
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Arte algorítmico por yuruyurau en Twitter