This week’s AI news is also available in audio form (spoken by me, a human, and not an AI) on Spotify! Be sure to check it out and give it a follow if you are illiterate like me.
We also are releasing a Discord for our community which you can join using this invite link.
News
Veo3 is free to use on Youtube Shorts
Google has figured out the economics, and are now giving users free access to their powerful Veo3 model. Access is being rolled out now across the US, Canada, and a few other countries. You can access it in the Youtube Creator Studio.
”Tap the create button, then the sparkle icon in the top right corner to find our latest gen AI creation tools including Veo 3.”
- Youtube Announcement Blog”
This is a great way to access the Veo3 model, as previously it had cost 15 cents per second. The model does text-to-video, image-to-video, and video-to-video generation and generates the audio for the clips as well, making it an all-in-one solution for your video creation needs.
This does come with the expected cost of seeing a lot more AI slop videos on your YouTube Shorts feed. And long term, there are concerns of this model frying people’s brains even more than regular short form content, as it gets better and is able to learn exactly what people want to see and is able to make custom videos catered directly for them.
OpenAI Codex Update
I have been using OpenAI’s Codex CLI as my main programming tool for the last few weeks now. It has been noticeably better for my coding use cases versus Claude Code with Sonnet 4 while already being a part of my ChatGPT subscription.
This week they released an update to their whole suite of Codex products, further increasing their lead in the agentic coding field.
The headliner is the release of a new model, GPT-5-Codex, which is a finetuned version of GPT-5 made specifically for use in the Codex framework. It shows strong performance increases in real world coding benchmarks, can write better documentation and comments, and can dynamically control how much or how little reasoning it does, so easy questions get answered quickly and hard questions can be thought through deeply.
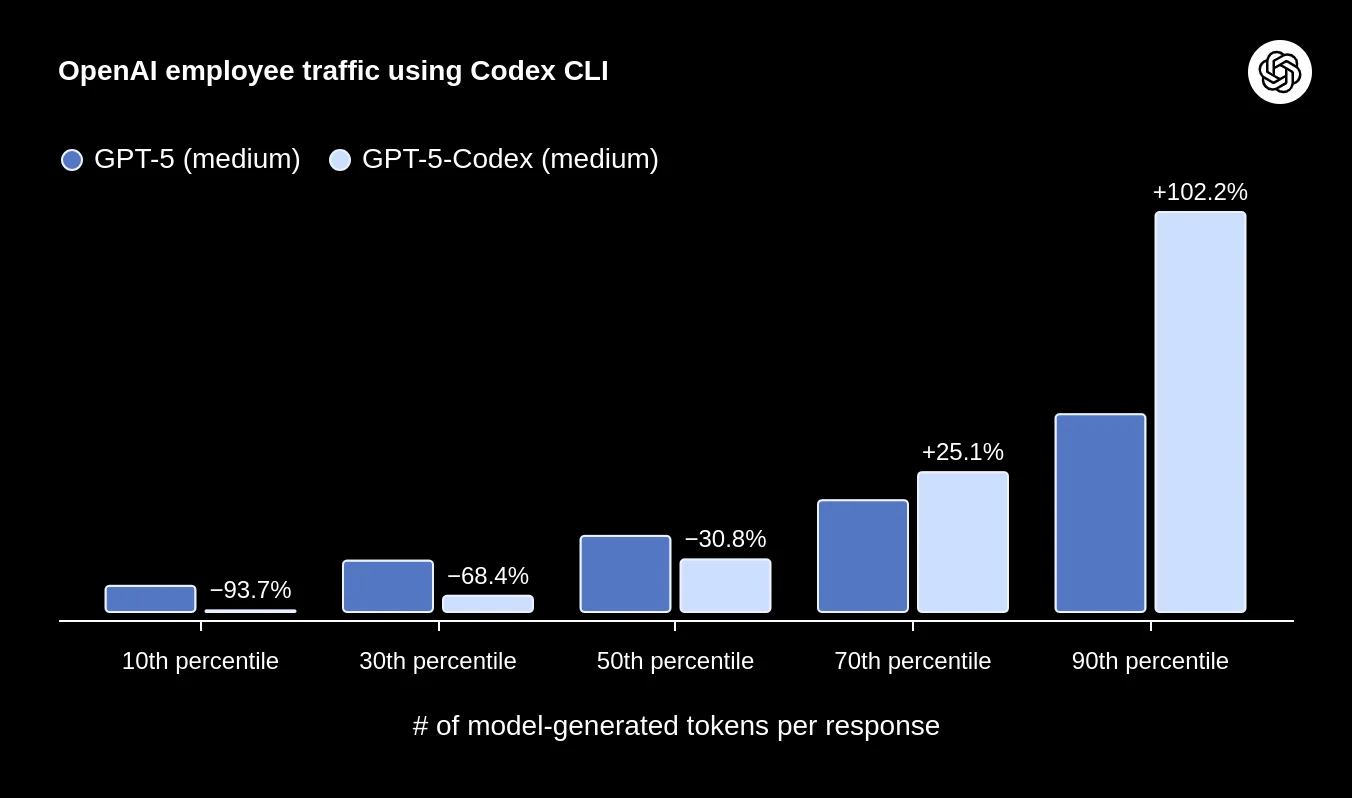
GPT-5-Codex can dynamically change the number of tokens it uses depending on how hard the question is
Alongside the new models, they released updates to the different Codex frameworks (CLI, IDE extension, and Cloud), allowing them to all seamlessly interact on the same project. Some additional features include automatic Github pull request code reviews, MCP and web search support, and support for image inputs.
The one caveat for using Codex is that it is not as good at handling very vague prompts compared to Claude Sonnet 4. If you want to get the most out of the model, you will want to be as specific as you can with your instructions.
Releases
Wan 2.2 Animate
The top open source video generation model Wan 2.2, has had a new variant released by the Alibaba Wan team.
The model is Wan2.2 Animate, which as the name suggests, is meant for character animation based on an input video.
It has 2 modes:
- Move mode, which animates the character in the reference image with the movements in the input video.
- Mix mode, which replaces the character in the input video with the character in the input image.
The way I think of it, if you want to use the background in the reference image, use move mode, and if you want to use the background from the reference video, use mix mode.
Example of move mode with a variety of different characters
This model is definitely the strongest in the Wan 2.2 lineup, as it is competitive, if not better, than most of the closed source models trying to do the same.
The model comes in two variants similar to the rest of the WAN 2.2 lineup, there is a dense 5 billion parameter model for low resource users and quick iteration, and then the 28 billion parameter mixture of experts model.
You should be able to run the big 28B model if you have a GPU with more than 16 GB of vram.
The models work with the lightning loras made for the rest of the Wan 2.2 lineup, allowing for 10x faster generation speeds (otherwise a single video would take over 20 minutes to generate on a 3090).
If you want to see more examples of the model in action, you can check out their blog page.
Qwen (Tongyi) DeepResearch
The Qwen team has decided to take a break this week from any releases, but that did not stop their parent lab, Tongyi, from releasing a model of their own.
The model is a fine-tune of the Qwen 30B MoE model made specifically for deep research applications, called Tongyi DeepResearch.
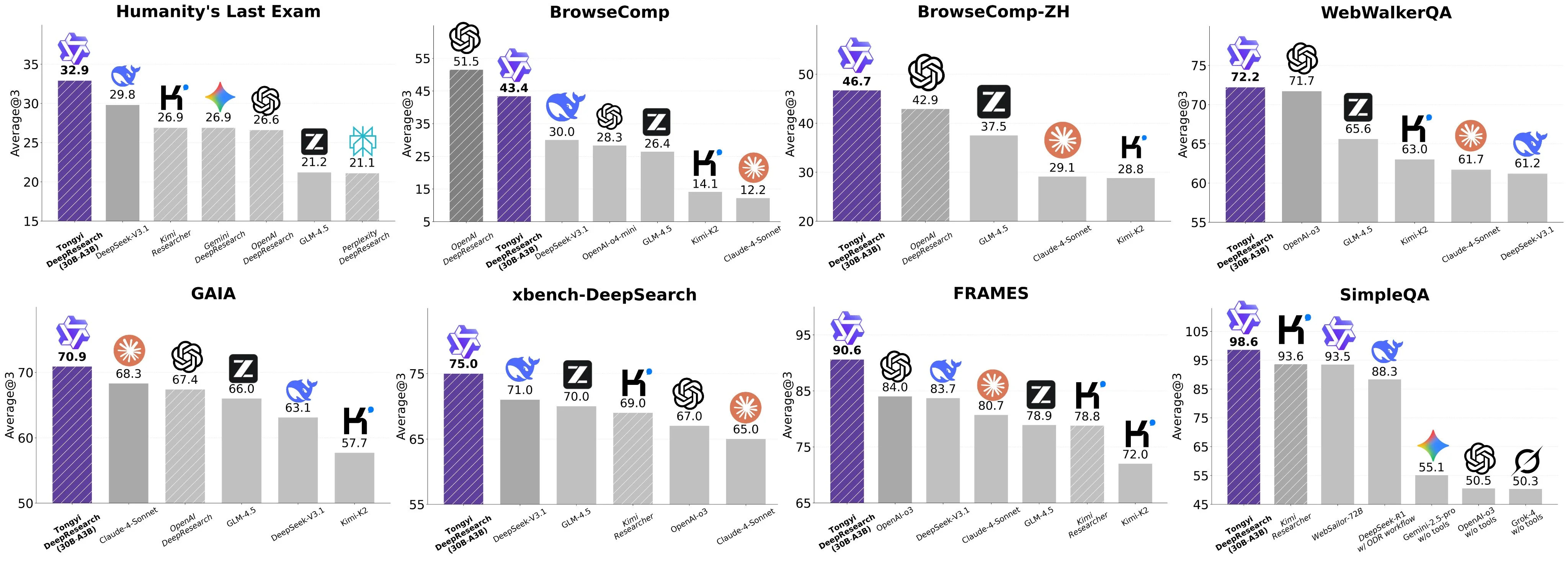
The model benchmarks well, but almost too well, as some users on Twitter have reported that they’ve been unable to reproduce the model’s very high scores across some of the benchmarks.
That being said, for its size, it is still a very strong model, even if it is only half as good as the reported benchmarks claim that it is.
I plan on integrating it into my local AI setup, and will hopefully have more to say about its real world performance in the coming weeks. Also look out for Qwen3-VL coming out next week as well.
A pair of image understanding models
We got not just one but two small image understanding LLM releases this week.
Moondream 3 Preview
Moondream 3-Preview is a 9 billion parameter MoE model with 2 billion active parameters that has state of the art visual understanding and reasoning capabilities.
It is a hybrid reasoning model capable of doing visually grounded reasoning where the model references objects in spatial positions in the image while it’s doing its reasoning.
The model has both point and detect (draw bounding box) functionality built into it by default that you can use.

The team behind Moondream is very detail-oriented. So I suspect very little overfitting on benchmarks and that it actually does have state-of-the-art performance that matches the much larger closed models.
You can try it out for free with no account on their playground.
Isaac 0.1
The second is from the former meta chameleon team which have left informed their own company Perception AI.
They have released a model called Isaac 0.1 which is a 2 billion parameter open weights model that performs equally if not better than Gemini 2.5 Flash on spatial intelligence and visual reasoning benchmarks.
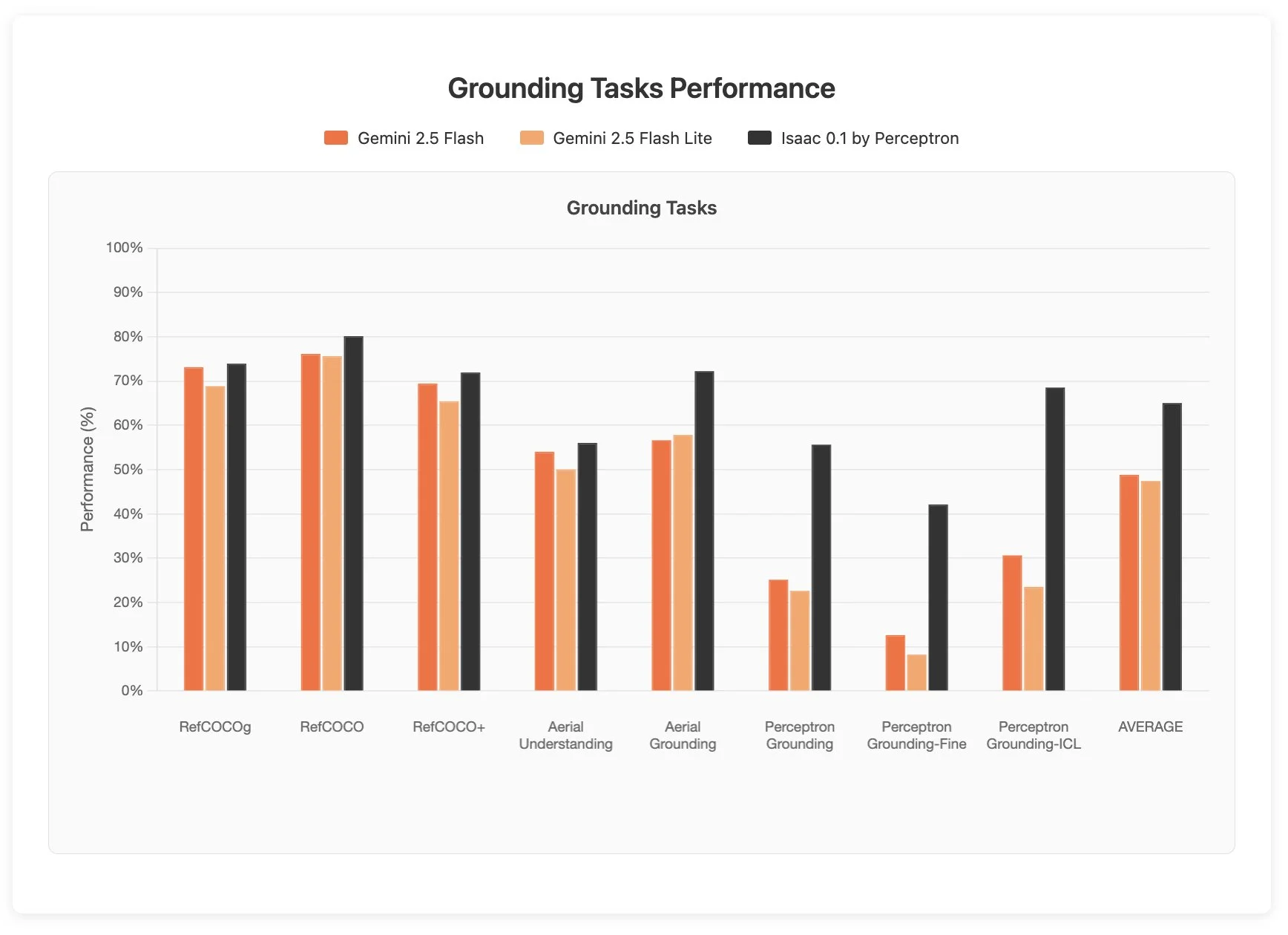
Normally this is not a model that I would cover, except that in testing, it managed to pass some of my internal vision understanding tests that no other multimodal model has been able to do up to this point, including Moondream 3, Gemini 2.5 Pro, and GPT-5.
It is still very much rough around the edges, running into infinite loops and hallucinating many outputs. But there are moments where you can see that it is truly a very powerful model. I look forward to what this team is able to build in the future and eagerly await the release of Isaac 1.0.
This model is also freely available to play around with on the Perception AI website.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Wan2.2 Animate Move mode example — from bdsqlsz on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
As notícias de IA desta semana também estão disponíveis em formato de áudio (narrado por mim, um humano, e não uma IA) no Spotify! Não deixe de conferir e seguir se você é analfabeto como eu.
Também estamos lançando um Discord para nossa comunidade que você pode participar usando este link de convite.
Notícias
Veo3 está disponível gratuitamente no Youtube Shorts
O Google descobriu a economia, e agora está oferecendo aos usuários acesso gratuito ao seu poderoso modelo Veo3. O acesso está sendo liberado agora nos EUA, Canadá e alguns outros países. Você pode acessá-lo no Youtube Creator Studio.
”Toque no botão criar, depois no ícone de estrela no canto superior direito para encontrar nossas mais recentes ferramentas de criação de IA generativa, incluindo o Veo 3.”
- Blog de Anúncios do Youtube”
Esta é uma ótima maneira de acessar o modelo Veo3, pois anteriormente custava 15 centavos por segundo. O modelo faz geração de texto para vídeo, imagem para vídeo e vídeo para vídeo, e gera o áudio para os clipes também, tornando-o uma solução completa para suas necessidades de criação de vídeo.
Isso vem com o custo esperado de ver muito mais vídeos de conteúdo gerado por IA de baixa qualidade no seu feed do YouTube Shorts. E a longo prazo, há preocupações de que este modelo possa fritar o cérebro das pessoas ainda mais do que o conteúdo de formato curto comum, à medida que melhora e consegue aprender exatamente o que as pessoas querem ver e é capaz de fazer vídeos personalizados feitos diretamente para elas.
Atualização do OpenAI Codex
Tenho usado o CLI Codex da OpenAI como minha principal ferramenta de programação nas últimas semanas. Ele tem sido notavelmente melhor para meus casos de uso de codificação em comparação com o Claude Code com Sonnet 4, enquanto já faz parte da minha assinatura do ChatGPT.
Esta semana eles lançaram uma atualização para todo o seu conjunto de produtos Codex, aumentando ainda mais sua liderança no campo de codificação agêntica.
O destaque é o lançamento de um novo modelo, GPT-5-Codex, que é uma versão ajustada do GPT-5 feita especificamente para uso no framework Codex. Ele mostra fortes aumentos de desempenho em benchmarks de codificação do mundo real, pode escrever melhor documentação e comentários, e pode controlar dinamicamente quanto raciocínio ele faz, para que perguntas fáceis sejam respondidas rapidamente e perguntas difíceis possam ser pensadas profundamente.
O GPT-5-Codex pode mudar dinamicamente o número de tokens que usa dependendo da dificuldade da pergunta
Junto com os novos modelos, eles lançaram atualizações para os diferentes frameworks Codex (CLI, extensão IDE e Cloud), permitindo que todos interajam perfeitamente no mesmo projeto. Alguns recursos adicionais incluem revisões automáticas de código em pull requests do Github, suporte para MCP e busca na web, e suporte para entradas de imagem.
A única ressalva para usar o Codex é que ele não é tão bom em lidar com prompts muito vagos em comparação com o Claude Sonnet 4. Se você quiser aproveitar ao máximo o modelo, você vai querer ser o mais específico possível com suas instruções.
Lançamentos
Wan 2.2 Animate
O principal modelo de geração de vídeo de código aberto Wan 2.2, teve uma nova variante lançada pela equipe Alibaba Wan.
O modelo é Wan2.2 Animate, que como o nome sugere, é feito para animação de personagens baseada em um vídeo de entrada.
Ele tem 2 modos:
- Modo Move, que anima o personagem na imagem de referência com os movimentos no vídeo de entrada.
- Modo Mix, que substitui o personagem no vídeo de entrada pelo personagem na imagem de entrada.
A maneira como eu penso nisso, se você quiser usar o fundo na imagem de referência, use o modo move, e se você quiser usar o fundo do vídeo de referência, use o modo mix.
Exemplo do modo move com uma variedade de personagens diferentes
Este modelo é definitivamente o mais forte na linha Wan 2.2, pois é competitivo, se não melhor, do que a maioria dos modelos de código fechado tentando fazer o mesmo.
O modelo vem em duas variantes semelhantes ao resto da linha WAN 2.2, há um modelo denso de 5 bilhões de parâmetros para usuários com poucos recursos e iteração rápida, e depois o modelo mixture of experts de 28 bilhões de parâmetros.
Você deve ser capaz de executar o grande modelo 28B se tiver uma GPU com mais de 16 GB de vram.
Os modelos funcionam com os lightning loras feitos para o resto da linha Wan 2.2, permitindo velocidades de geração 10x mais rápidas (caso contrário, um único vídeo levaria mais de 20 minutos para gerar em uma 3090).
Se você quiser ver mais exemplos do modelo em ação, pode conferir a página do blog deles.
Qwen (Tongyi) DeepResearch
A equipe Qwen decidiu dar uma pausa esta semana de qualquer lançamento, mas isso não impediu seu laboratório pai, Tongyi, de lançar um modelo próprio.
O modelo é um ajuste fino do modelo Qwen 30B MoE feito especificamente para aplicações de pesquisa profunda, chamado Tongyi DeepResearch.
O modelo tem bons resultados em benchmarks, mas quase bons demais, já que alguns usuários no Twitter relataram que não conseguiram reproduzir as pontuações muito altas do modelo em alguns dos benchmarks.
Dito isso, para seu tamanho, ainda é um modelo muito forte, mesmo que seja apenas metade do que os benchmarks relatados afirmam que ele é.
Eu planejo integrá-lo na minha configuração de IA local, e espero ter mais a dizer sobre seu desempenho no mundo real nas próximas semanas. Também fique atento ao Qwen3-VL que sairá na próxima semana também.
Um par de modelos de compreensão de imagem
Tivemos não apenas um, mas dois lançamentos de pequenos LLMs de compreensão de imagem esta semana.
Moondream 3 Preview
Moondream 3-Preview é um modelo MoE de 9 bilhões de parâmetros com 2 bilhões de parâmetros ativos que tem capacidades de compreensão visual e raciocínio de última geração.
É um modelo de raciocínio híbrido capaz de fazer raciocínio visualmente fundamentado onde o modelo referencia objetos em posições espaciais na imagem enquanto está fazendo seu raciocínio.
O modelo tem funcionalidade de apontar e detectar (desenhar caixa delimitadora) incorporada nele por padrão que você pode usar.
A equipe por trás do Moondream é muito orientada para detalhes. Então eu suspeito de muito pouco overfitting em benchmarks e que ele realmente tem desempenho de última geração que corresponde aos modelos fechados muito maiores.
Você pode experimentá-lo gratuitamente sem conta no playground deles.
Isaac 0.1
O segundo é da antiga equipe chameleon da Meta que saiu e formou sua própria empresa Perception AI.
Eles lançaram um modelo chamado Isaac 0.1 que é um modelo de pesos abertos de 2 bilhões de parâmetros que performa igualmente, se não melhor, do que o Gemini 2.5 Flash em benchmarks de inteligência espacial e raciocínio visual.
Normalmente este não é um modelo que eu cobriria, exceto que nos testes, ele conseguiu passar alguns dos meus testes internos de compreensão de visão que nenhum outro modelo multimodal foi capaz de fazer até este ponto, incluindo Moondream 3, Gemini 2.5 Pro e GPT-5.
Ele ainda está muito áspero nas bordas, caindo em loops infinitos e alucinando muitas saídas. Mas há momentos em que você pode ver que é verdadeiramente um modelo muito poderoso. Estou ansioso pelo que esta equipe é capaz de construir no futuro e aguardo ansiosamente o lançamento do Isaac 1.0.
Este modelo também está disponível gratuitamente para experimentar no site da Perception AI.
Fim
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, certifique-se de se juntar à nossa lista de e-mails abaixo.
Exemplo do modo Move do Wan2.2 Animate — de bdsqlsz no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Las noticias de IA de esta semana también están disponibles en formato de audio (hablado por mí, un humano, y no una IA) en Spotify! Asegúrate de escucharlo y darle seguimiento si eres analfabeto como yo.
También estamos lanzando un Discord para nuestra comunidad al que puedes unirte usando este enlace de invitación.
Noticias
Veo3 es gratis en Youtube Shorts
Google ha descubierto cómo funciona la economía, y ahora está dando a los usuarios acceso gratuito a su poderoso modelo Veo3. El acceso se está implementando ahora en Estados Unidos, Canadá y algunos otros países. Puedes acceder a él en el Youtube Creator Studio.
”Toca el botón crear, luego el ícono de estrella en la esquina superior derecha para encontrar nuestras últimas herramientas de creación con IA generativa incluyendo Veo 3.”
- Blog de anuncio de Youtube”
Esta es una excelente manera de acceder al modelo Veo3, ya que anteriormente costaba 15 centavos por segundo. El modelo hace generación de texto a video, imagen a video y video a video, y genera el audio para los clips también, convirtiéndolo en una solución todo en uno para tus necesidades de creación de video.
Esto viene con el costo esperado de ver muchos más videos basura generados por IA en tu feed de YouTube Shorts. Y a largo plazo, existen preocupaciones de que este modelo fría aún más los cerebros de las personas que el contenido de formato corto regular, a medida que mejora y es capaz de aprender exactamente lo que la gente quiere ver y puede hacer videos personalizados diseñados directamente para ellos.
Actualización de OpenAI Codex
He estado usando el CLI de Codex de OpenAI como mi herramienta principal de programación durante las últimas semanas. Ha sido notablemente mejor para mis casos de uso de codificación en comparación con Claude Code con Sonnet 4, mientras que ya es parte de mi suscripción de ChatGPT.
Esta semana lanzaron una actualización para toda su suite de productos Codex, aumentando aún más su liderazgo en el campo de la codificación agéntica.
Lo más destacado es el lanzamiento de un nuevo modelo, GPT-5-Codex, que es una versión ajustada de GPT-5 hecha específicamente para usar en el framework de Codex. Muestra fuertes aumentos de rendimiento en benchmarks de codificación del mundo real, puede escribir mejor documentación y comentarios, y puede controlar dinámicamente cuánto o qué tan poco razonamiento hace, por lo que las preguntas fáciles se responden rápidamente y las preguntas difíciles se pueden pensar profundamente.
GPT-5-Codex puede cambiar dinámicamente el número de tokens que usa dependiendo de qué tan difícil sea la pregunta
Junto con los nuevos modelos, lanzaron actualizaciones a los diferentes frameworks de Codex (CLI, extensión IDE y Cloud), permitiéndoles interactuar sin problemas en el mismo proyecto. Algunas características adicionales incluyen revisiones automáticas de código de pull requests de Github, soporte de MCP y búsqueda web, y soporte para entradas de imágenes.
La única salvedad para usar Codex es que no es tan bueno manejando prompts muy vagos en comparación con Claude Sonnet 4. Si quieres sacar el máximo provecho del modelo, querrás ser lo más específico posible con tus instrucciones.
Lanzamientos
Wan 2.2 Animate
El mejor modelo de generación de video de código abierto Wan 2.2, ha tenido una nueva variante lanzada por el equipo de Alibaba Wan.
El modelo es Wan2.2 Animate, que como sugiere el nombre, está destinado a la animación de personajes basada en un video de entrada.
Tiene 2 modos:
- Modo Move, que anima el personaje en la imagen de referencia con los movimientos en el video de entrada.
- Modo Mix, que reemplaza el personaje en el video de entrada con el personaje en la imagen de entrada.
La forma en que lo pienso, si quieres usar el fondo en la imagen de referencia, usa el modo move, y si quieres usar el fondo del video de referencia, usa el modo mix.
Ejemplo del modo move con una variedad de personajes diferentes
Este modelo es definitivamente el más fuerte en la línea Wan 2.2, ya que es competitivo, si no mejor, que la mayoría de los modelos de código cerrado que intentan hacer lo mismo.
El modelo viene en dos variantes similares al resto de la línea WAN 2.2, hay un modelo denso de 5 mil millones de parámetros para usuarios de bajos recursos e iteración rápida, y luego el modelo de mezcla de expertos de 28 mil millones de parámetros.
Deberías poder ejecutar el modelo grande de 28B si tienes una GPU con más de 16 GB de vram.
Los modelos funcionan con los lightning loras hechos para el resto de la línea Wan 2.2, permitiendo velocidades de generación 10 veces más rápidas (de lo contrario, un solo video tomaría más de 20 minutos en generarse en una 3090).
Si quieres ver más ejemplos del modelo en acción, puedes revisar su página de blog.
Qwen (Tongyi) DeepResearch
El equipo de Qwen ha decidido tomarse un descanso esta semana de cualquier lanzamiento, pero eso no impidió que su laboratorio padre, Tongyi, lanzara un modelo propio.
El modelo es un ajuste fino del modelo Qwen 30B MoE hecho específicamente para aplicaciones de investigación profunda, llamado Tongyi DeepResearch.
El modelo tiene buenos benchmarks, pero casi demasiado buenos, ya que algunos usuarios en Twitter han reportado que no han podido reproducir las puntuaciones muy altas del modelo en algunos de los benchmarks.
Dicho esto, para su tamaño, sigue siendo un modelo muy fuerte, incluso si es solo la mitad de bueno de lo que afirman los benchmarks reportados.
Planeo integrarlo en mi configuración local de IA, y espero tener más que decir sobre su rendimiento en el mundo real en las próximas semanas. También estate atento a Qwen3-VL que saldrá la próxima semana también.
Un par de modelos de comprensión de imágenes
Obtuvimos no solo uno sino dos lanzamientos de LLM pequeños de comprensión de imágenes esta semana.
Moondream 3 Preview
Moondream 3-Preview es un modelo MoE de 9 mil millones de parámetros con 2 mil millones de parámetros activos que tiene capacidades de vanguardia en comprensión visual y razonamiento.
Es un modelo de razonamiento híbrido capaz de hacer razonamiento visualmente fundamentado donde el modelo referencia objetos en posiciones espaciales en la imagen mientras está haciendo su razonamiento.
El modelo tiene funcionalidad de punto y detección (dibujar caja delimitadora) incorporada por defecto que puedes usar.
El equipo detrás de Moondream es muy detallista. Así que sospecho muy poco sobreajuste en los benchmarks y que realmente tiene un rendimiento de vanguardia que iguala a los modelos cerrados mucho más grandes.
Puedes probarlo gratis sin cuenta en su playground.
Isaac 0.1
El segundo es del antiguo equipo de chameleon de meta que se ha ido para formar su propia compañía Perception AI.
Han lanzado un modelo llamado Isaac 0.1 que es un modelo de pesos abiertos de 2 mil millones de parámetros que se desempeña igual o mejor que Gemini 2.5 Flash en benchmarks de inteligencia espacial y razonamiento visual.
Normalmente este no es un modelo que cubriría, excepto que en las pruebas, logró pasar algunas de mis pruebas internas de comprensión de visión que ningún otro modelo multimodal ha podido hacer hasta este momento, incluyendo Moondream 3, Gemini 2.5 Pro, y GPT-5.
Todavía tiene bordes muy ásperos, entrando en bucles infinitos y alucinando muchas salidas. Pero hay momentos en los que puedes ver que realmente es un modelo muy poderoso. Espero con ansias lo que este equipo sea capaz de construir en el futuro y espero ansiosamente el lanzamiento de Isaac 1.0.
Este modelo también está disponible gratuitamente para jugar en el sitio web de Perception AI.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo abajo.
Ejemplo del modo Move de Wan2.2 Animate — de bdsqlsz en Twitter