News
Anthropic gets lucky?
We had previously covered how Anthropic was getting sued for copyright infrinegemnt due to their illegal procurement of books to be used as training data (they pirated them).
The potential range for the fine was from $1 billion all the way up to $750 billion (theoretically, no judge would actually delivery that harsh of a fine).
This week the actual number was made known to the public, and it was $1.5 billion. In the grand sceme of things, this is a relatively good outcome for Anthropic, as its very close to the minimum they could have bene fined, but also it is still the largest copyright lawsuit of all time.
This totals to about $3000 per work that they pirated, which doesnt sound all that bad on its own until you relaize that they pirated around 500,000 books (and other materials) that were under copyright protections. The payments will not being going to any large corporations, but rather the individual authors whose books were involved as a part of the class action lawsuit.
This fine, while big, will not cripple Anthropic, especially considering that they just raised a $13 billion series F at a $183 billion valuation.
This does however send a message to the rest of the AI world, letting them know that they can and will get fined for illegally aquairing the datasets that they train on.
I don’t think this will cause a change in their actions however, they will just take their OpSec around their data gathering practices far more seriously in the future instead of stopping since the value they get from this extra data is immense.
Smaller companies will have to monitor their data much more closely, as they cannot absorb a fine of this size, but all of the large competitors like Google and OpenAI can absorb a fine like this far more easily, making it a much less risky play for them.
Releases
$3/month Claude Code subscription?
Claude Code was released back in May of 2025 and since then has gained a large userbase, due to the clean terminal interface and top tier preformance as the environment was custom made for Claude.
As time has gone on however, we have seen a variety of competitors, inlcuding GPT 5 and the Codex CLI, and also open source models like GLM 4.5, Qwen3 Coder, and Kimi K2 that all claim similar if not better performance that Sonnnet in Claude Code.
To add to the enticing offerings, Z.ai, the company that made GLM 4.5, are now offering a monthly subscription plan similar to Claude code, except at over 5x lower cost.

Just $3 a month for a high quality model with generous limits is an incredible deal
For just $3 a month, they are offering 3x the usage of the $20/month plan from Anthropic. This also comes with very clear usage limits of 120 messages every 5 hours, something that Anthropic has not defined and is very vauge about, so you are unsure how much you will be able to use Claude for a given session.
They have updated their endpoints to be directly compatible with Claude Code, so you just need to set two environment variables as shown in their docs and then you can be off to the races coding with GLM 4.5.
I have found GLM 4.5 to be the best open source competitor to Claude Sonnet, and also much faster as well, which has been corroborated by others. GLM 4.5 also topped the Berkley Function-Calling Leaderboard this week, further showing its tool use prowess, which is a big indicator for real world coding performance.
If you have not had a chance to try out GLM 4.5 or Claude Code yet, this is a great opportunity to get your feet wet with the new model and coding framework!
Qwen3 Max
Qwen has decided to drop a doozy for their weekly release, adding the biggest model to their Qwen 3 lineup of models, a 1 trillion parameter beast called Qwen Max.
The model is a departure from their typical releases as it is closed source for now, although they say that it will be released as open source in the future, as this current iteration is just a preview.
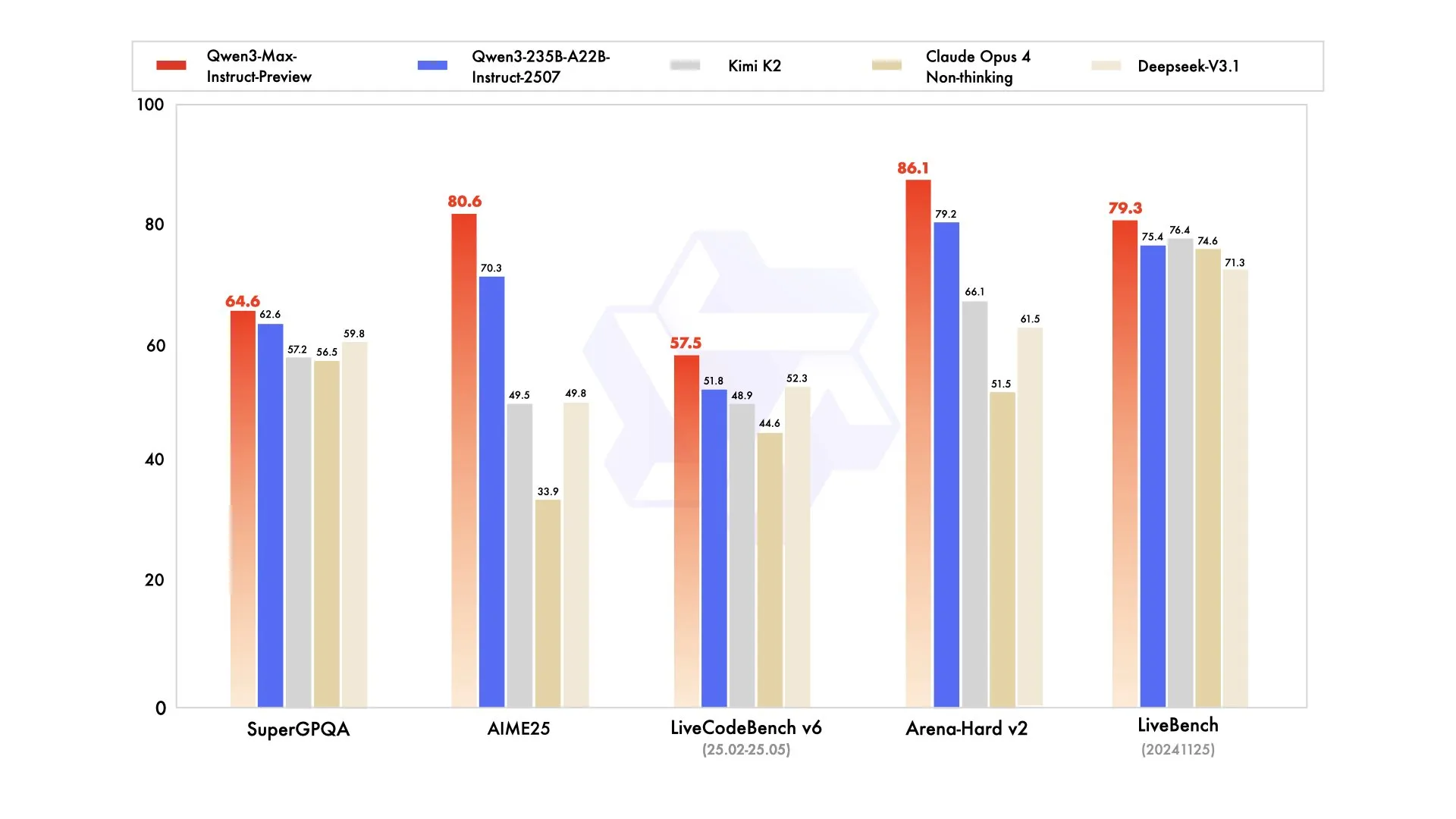
The Qwen team say that this model gives them hope for scaling both now in the future in terms of model size and also data size, and that the Qwen Max model is much smarter than even the benchmarks reflect.
Kimi K2 Update
The Moonshot AI team has released an update to their already very strong Kimi K2 model. This update focused primarily on coding abilities and increasing its context length, which allows it to have better performance in different agentic coding scaffolds like Claude Code or Roo code.
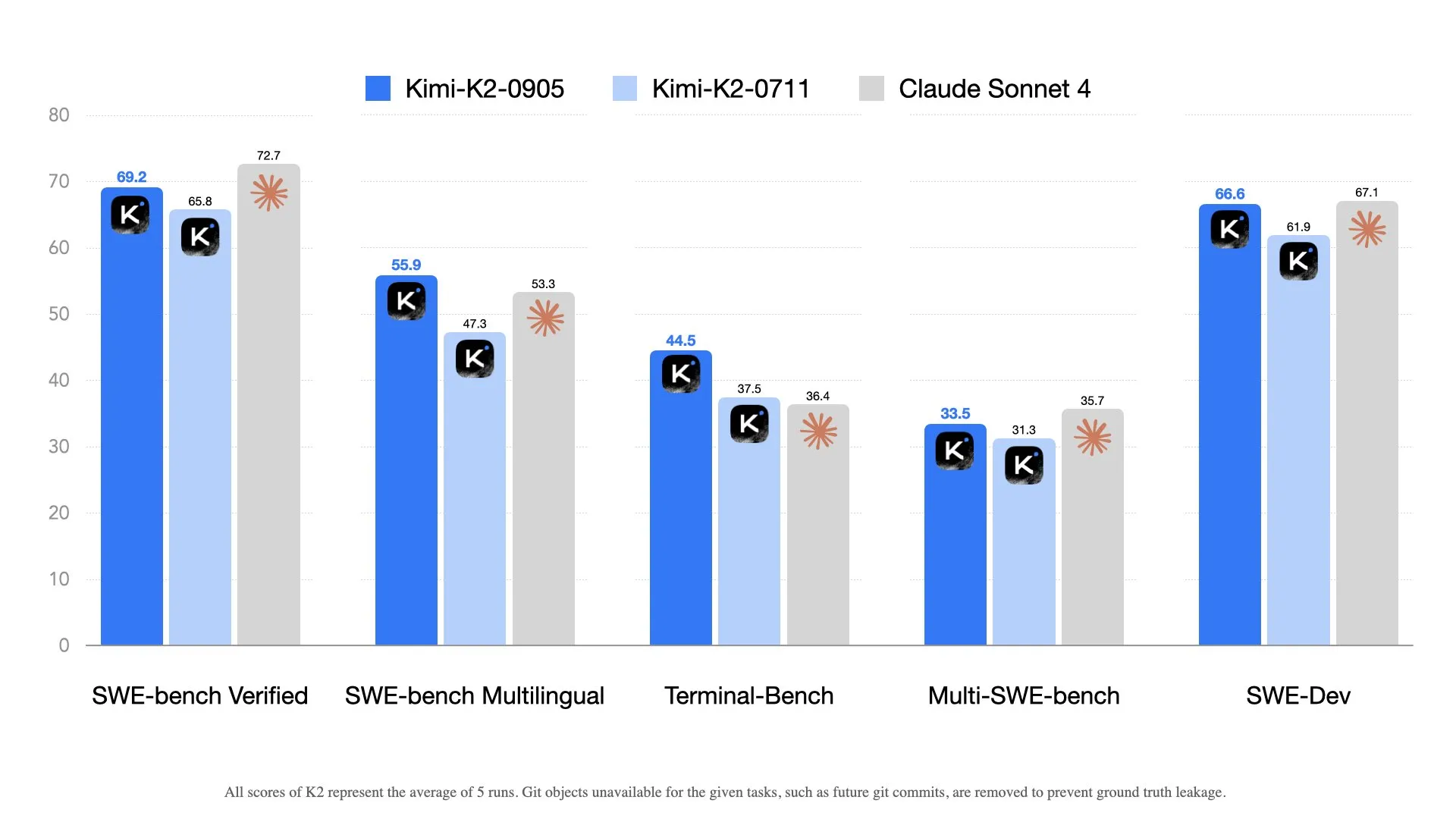
This release comes in a response to both DeepSeek and Z.ai’s recent releases, which have directly targeted agentic coding capabilities.
Research
New agentic coding benchmark
With coding being one of the largest use cases for LLMs right now, we are constantly in need for more benchmarks to measure the differences between all of these models claiming to be the best.
We have got one of these benchmarks with SWE-Rebench being released comparing a wide range of top closed and open source coding models.
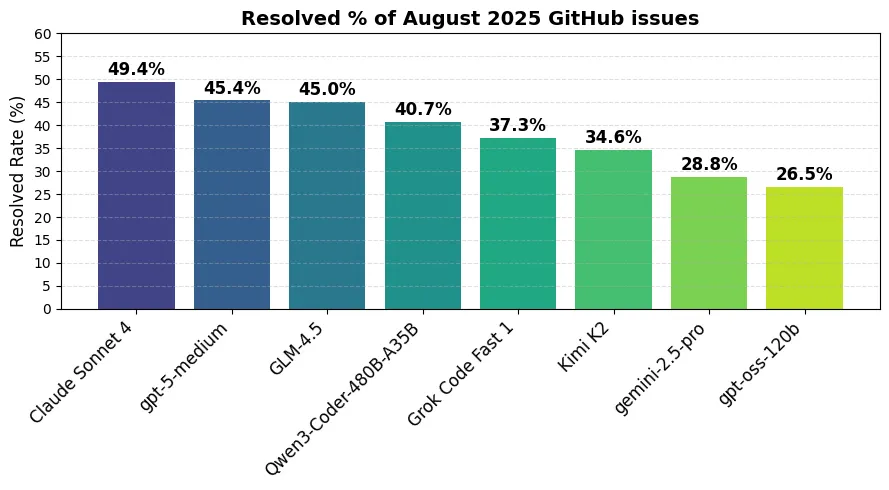
Claude remains the best model, but is closely followed behind by GPT-5 and GLM 4.5. What is interesting to see is how cheap GPT-5 is compared to the open source models. Usually we expect closed source models like Claude and GPT-5 to be much more expensive than models like GLM 4.5 or To be much more expensive than models like GLM 4.5 or Qwen3 Coder. But for this benchmark, we see that GLM 4.5 is roughly the same cost as GPT-5 Medium.
What was also surprising was the performance of GPT-5 Mini coming in fifth place right behind GLM 4.5 and ahead of Qwen3 Coder.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

By seatedro on Twitter Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Notícias
Anthropic teve sorte?
Nós cobrimos anteriormente como a Anthropic estava sendo processada por violação de direitos autorais devido à sua aquisição ilegal de livros para serem usados como dados de treinamento (eles os piratearam).
A faixa potencial para a multa era de US$ 1 bilhão até US$ 750 bilhões (teoricamente, nenhum juiz realmente aplicaria uma multa tão severa).
Esta semana o número real foi divulgado ao público, e foi de US$ 1,5 bilhão. No grande esquema das coisas, este é um resultado relativamente bom para a Anthropic, pois está muito próximo do mínimo que eles poderiam ter sido multados, mas também ainda é a maior ação judicial de direitos autorais de todos os tempos.
Isso totaliza cerca de US$ 3.000 por obra que eles piratearam, o que não parece tão ruim por si só até você perceber que eles piratearam cerca de 500.000 livros (e outros materiais) que estavam sob proteção de direitos autorais. Os pagamentos não irão para nenhuma grande corporação, mas sim para os autores individuais cujos livros foram envolvidos como parte da ação coletiva.
Esta multa, embora grande, não prejudicará a Anthropic, especialmente considerando que eles acabaram de levantar uma série F de US$ 13 bilhões com uma avaliação de US$ 183 bilhões.
Isso, no entanto, envia uma mensagem para o resto do mundo da IA, deixando-os saber que eles podem e serão multados por adquirir ilegalmente os conjuntos de dados nos quais treinam.
Eu não acho que isso causará uma mudança em suas ações, no entanto, eles apenas levarão sua segurança operacional em torno de suas práticas de coleta de dados muito mais a sério no futuro, em vez de parar, já que o valor que eles obtêm desses dados extras é imenso.
Empresas menores terão que monitorar seus dados muito mais de perto, pois não podem absorver uma multa deste tamanho, mas todos os grandes concorrentes como Google e OpenAI podem absorver uma multa como esta muito mais facilmente, tornando-a uma jogada muito menos arriscada para eles.
Lançamentos
Assinatura do Claude Code por US$ 3/mês?
O Claude Code foi lançado em maio de 2025 e desde então ganhou uma grande base de usuários, devido à interface de terminal limpa e desempenho de primeira linha, já que o ambiente foi feito sob medida para o Claude.
Conforme o tempo passou, no entanto, vimos uma variedade de concorrentes, incluindo GPT 5 e o Codex CLI, e também modelos de código aberto como GLM 4.5, Qwen3 Coder e Kimi K2 que todos alegam desempenho semelhante, se não melhor, que o Sonnet no Claude Code.
Para adicionar às ofertas tentadoras, a Z.ai, a empresa que fez o GLM 4.5, agora está oferecendo um plano de assinatura mensal semelhante ao Claude Code, exceto a um custo mais de 5x menor.
Apenas US$ 3 por mês por um modelo de alta qualidade com limites generosos é um negócio incrível
Por apenas US$ 3 por mês, eles estão oferecendo 3x o uso do plano de US$ 20/mês da Anthropic. Isso também vem com limites de uso muito claros de 120 mensagens a cada 5 horas, algo que a Anthropic não definiu e é muito vago sobre, então você não tem certeza de quanto poderá usar o Claude para uma determinada sessão.
Eles atualizaram seus endpoints para serem diretamente compatíveis com o Claude Code, então você só precisa definir duas variáveis de ambiente conforme mostrado em seus documentos e então você pode começar a programar com o GLM 4.5.
Eu descobri que o GLM 4.5 é o melhor concorrente de código aberto ao Claude Sonnet, e também muito mais rápido, o que foi corroborado por outros. O GLM 4.5 também liderou o Berkley Function-Calling Leaderboard esta semana, mostrando ainda mais sua proeza no uso de ferramentas, que é um grande indicador de desempenho de codificação no mundo real.
Se você ainda não teve a chance de experimentar o GLM 4.5 ou o Claude Code, esta é uma ótima oportunidade para se familiarizar com o novo modelo e framework de codificação!
Qwen3 Max
A Qwen decidiu lançar uma bomba para seu lançamento semanal, adicionando o maior modelo à sua linha de modelos Qwen 3, uma fera de 1 trilhão de parâmetros chamada Qwen Max.
O modelo é uma partida de seus lançamentos típicos, pois é de código fechado por enquanto, embora eles digam que será lançado como código aberto no futuro, já que esta iteração atual é apenas uma prévia.
A equipe Qwen diz que este modelo lhes dá esperança para o dimensionamento tanto agora quanto no futuro em termos de tamanho do modelo e também tamanho dos dados, e que o modelo Qwen Max é muito mais inteligente do que até mesmo os benchmarks refletem.
Atualização do Kimi K2
A equipe da Moonshot AI lançou uma atualização para seu modelo Kimi K2 já muito forte. Esta atualização focou principalmente em capacidades de codificação e aumentar sua extensão de contexto, o que permite ter melhor desempenho em diferentes estruturas de codificação agêntica como Claude Code ou Roo code.
Este lançamento vem em resposta aos lançamentos recentes da DeepSeek e da Z.ai, que têm direcionado diretamente capacidades de codificação agêntica.
Pesquisa
Novo benchmark de codificação agêntica
Com a codificação sendo um dos maiores casos de uso para LLMs agora, estamos constantemente precisando de mais benchmarks para medir as diferenças entre todos esses modelos que afirmam ser os melhores.
Nós temos um desses benchmarks com o SWE-Rebench sendo lançado comparando uma ampla gama dos melhores modelos de codificação de código aberto e fechado.
O Claude permanece o melhor modelo, mas é seguido de perto pelo GPT-5 e GLM 4.5. O que é interessante de ver é quão barato o GPT-5 é comparado aos modelos de código aberto. Normalmente esperamos que modelos de código fechado como Claude e GPT-5 sejam muito mais caros do que modelos como GLM 4.5 ou Qwen3 Coder. Mas para este benchmark, vemos que o GLM 4.5 tem aproximadamente o mesmo custo que o GPT-5 Medium.
O que também foi surpreendente foi o desempenho do GPT-5 Mini chegando em quinto lugar logo atrás do GLM 4.5 e à frente do Qwen3 Coder.
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias todas as semanas, não deixe de se juntar à nossa lista de e-mails abaixo.
Por seatedro no Twitter Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Noticias
¿Anthropic tuvo suerte?
Anteriormente habíamos cubierto cómo Anthropic estaba siendo demandada por violación de derechos de autor debido a su adquisición ilegal de libros para ser utilizados como datos de entrenamiento (los piratearon).
El rango potencial de la multa iba desde $1 mil millones hasta $750 mil millones (teóricamente, ningún juez entregaría realmente una multa tan severa).
Esta semana se dio a conocer al público el número real, y fue de $1.5 mil millones. En el gran esquema de las cosas, este es un resultado relativamente bueno para Anthropic, ya que está muy cerca del mínimo que podrían haber sido multados, pero también sigue siendo la demanda por derechos de autor más grande de todos los tiempos.
Esto totaliza aproximadamente $3000 por obra que piratearon, lo cual no suena tan malo por sí solo hasta que te das cuenta de que piratearon alrededor de 500,000 libros (y otros materiales) que estaban bajo protecciones de derechos de autor. Los pagos no irán a ninguna gran corporación, sino a los autores individuales cuyos libros estuvieron involucrados como parte de la demanda colectiva.
Esta multa, aunque grande, no paralizará a Anthropic, especialmente considerando que acaban de recaudar una Serie F de $13 mil millones con una valoración de $183 mil millones.
Sin embargo, esto envía un mensaje al resto del mundo de la IA, haciéndoles saber que pueden y serán multados por adquirir ilegalmente los conjuntos de datos con los que entrenan.
No creo que esto cause un cambio en sus acciones, sin embargo, simplemente tomarán su OpSec en torno a sus prácticas de recopilación de datos mucho más en serio en el futuro en lugar de detenerse, ya que el valor que obtienen de estos datos adicionales es inmenso.
Las empresas más pequeñas tendrán que monitorear sus datos mucho más de cerca, ya que no pueden absorber una multa de este tamaño, pero todos los grandes competidores como Google y OpenAI pueden absorber una multa como esta mucho más fácilmente, lo que la convierte en una jugada mucho menos riesgosa para ellos.
Lanzamientos
¿Suscripción a Claude Code por $3/mes?
Claude Code fue lanzado en mayo de 2025 y desde entonces ha ganado una gran base de usuarios, debido a la interfaz de terminal limpia y el rendimiento de primer nivel, ya que el entorno fue hecho a medida para Claude.
Sin embargo, a medida que ha pasado el tiempo, hemos visto una variedad de competidores, incluyendo GPT 5 y el Codex CLI, y también modelos de código abierto como GLM 4.5, Qwen3 Coder y Kimi K2 que todos afirman tener un rendimiento similar o incluso mejor que Sonnet en Claude Code.
Para agregar a las ofertas atractivas, Z.ai, la empresa que creó GLM 4.5, ahora está ofreciendo un plan de suscripción mensual similar a Claude Code, excepto que a un costo más de 5 veces menor.
Solo $3 al mes por un modelo de alta calidad con límites generosos es una oferta increíble
Por solo $3 al mes, están ofreciendo 3 veces el uso del plan de $20/mes de Anthropic. Esto también viene con límites de uso muy claros de 120 mensajes cada 5 horas, algo que Anthropic no ha definido y es muy vago al respecto, por lo que no estás seguro de cuánto podrás usar Claude para una sesión determinada.
Han actualizado sus endpoints para ser directamente compatibles con Claude Code, por lo que solo necesitas establecer dos variables de entorno como se muestra en su documentación y luego puedes comenzar a programar con GLM 4.5.
He encontrado que GLM 4.5 es el mejor competidor de código abierto para Claude Sonnet, y también mucho más rápido, lo cual ha sido corroborado por otros. GLM 4.5 también encabezó el Berkley Function-Calling Leaderboard esta semana, mostrando aún más su destreza en el uso de herramientas, que es un gran indicador del rendimiento de codificación en el mundo real.
Si aún no has tenido la oportunidad de probar GLM 4.5 o Claude Code, ¡esta es una gran oportunidad para familiarizarte con el nuevo modelo y framework de codificación!
Qwen3 Max
Qwen ha decidido lanzar una bomba para su lanzamiento semanal, agregando el modelo más grande a su línea de modelos Qwen 3, una bestia de 1 billón de parámetros llamada Qwen Max.
El modelo es una desviación de sus lanzamientos típicos ya que es de código cerrado por ahora, aunque dicen que será lanzado como código abierto en el futuro, ya que esta iteración actual es solo una vista previa.
El equipo de Qwen dice que este modelo les da esperanza para escalar tanto ahora como en el futuro en términos de tamaño del modelo y también tamaño de datos, y que el modelo Qwen Max es mucho más inteligente de lo que incluso reflejan los benchmarks.
Actualización de Kimi K2
El equipo de Moonshot AI ha lanzado una actualización de su ya muy sólido modelo Kimi K2. Esta actualización se centró principalmente en capacidades de codificación y en aumentar su longitud de contexto, lo que le permite tener un mejor rendimiento en diferentes estructuras de codificación agéntica como Claude Code o Roo code.
Este lanzamiento viene como respuesta a los lanzamientos recientes tanto de DeepSeek como de Z.ai, que se han dirigido directamente a capacidades de codificación agéntica.
Investigación
Nuevo benchmark de codificación agéntica
Con la codificación siendo uno de los casos de uso más grandes para los LLMs en este momento, estamos constantemente en necesidad de más benchmarks para medir las diferencias entre todos estos modelos que afirman ser los mejores.
Hemos obtenido uno de estos benchmarks con SWE-Rebench siendo lanzado comparando una amplia gama de los principales modelos de codificación de código cerrado y abierto.
Claude sigue siendo el mejor modelo, pero es seguido de cerca por GPT-5 y GLM 4.5. Lo que es interesante ver es cuán barato es GPT-5 en comparación con los modelos de código abierto. Usualmente esperamos que los modelos de código cerrado como Claude y GPT-5 sean mucho más caros que modelos como GLM 4.5 o Qwen3 Coder. Pero para este benchmark, vemos que GLM 4.5 tiene aproximadamente el mismo costo que GPT-5 Medium.
Lo que también fue sorprendente fue el rendimiento de GPT-5 Mini llegando en quinto lugar justo detrás de GLM 4.5 y por delante de Qwen3 Coder.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Por seatedro en Twitter