News
Chinese AI labs go public
In the quest for more funding to train their LLMs, two large Chinese labs have gone public this week.
The first is Z.ai, known for their GLM series of models.
Their most recent model, GLM 4.7 is a very strong agentic model, around Sonnet 4.5 quality, while being 7 times cheaper, and fully open source.
The other is MiniMax, known for their slightly smaller flagship model MiniMax M2.1.
This model is around the same quality as GLM 4.7, while being half the total parameters.
Both companies are listed on the Hong Kong Stock Exchange, which you can trade through most brokers if you live in the US.
They both had strong first days, with Z.ai gaining 32% in the first 2 days of trading reaching a market cap of almost $9 billion USD, and Minimax more than doubling in its first day, ending on a valuation of $13.5 billion USD.
Of note, on the Hong Kong Stock Exchange, you need to buy a minimum of 100 shares, which equates to about $2k USD for Z.ai and $4500 for MiniMax.
Releases
LFM 2.5
Liquid AI has unveiled their new series of small foundation models meant for on-device deployment.
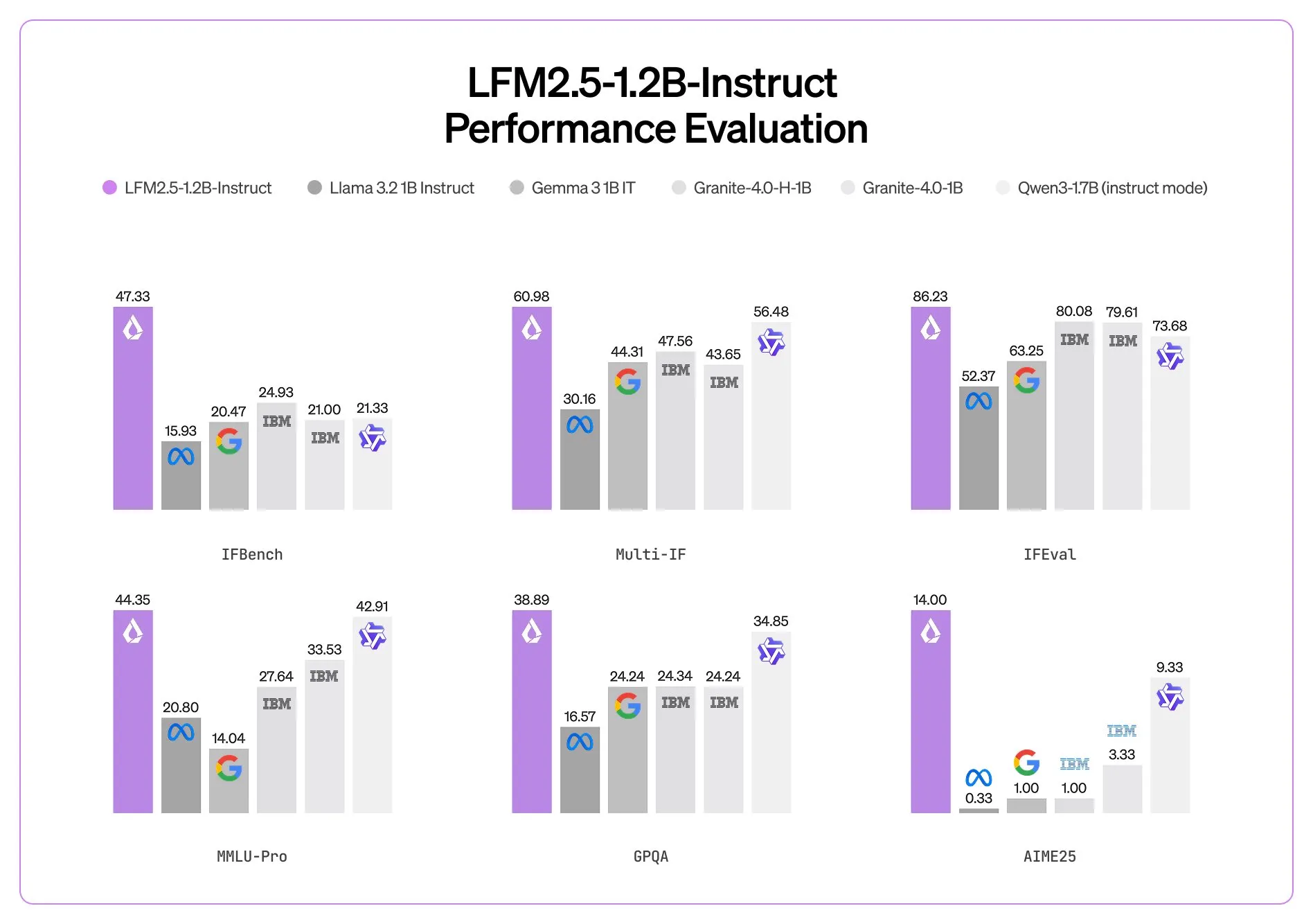
The model’s benchmark scores are comparable to the original GPT-4. It is crazy to see how far we have come in only 3 years.
The first model that they have unveiled is the LFM 2.5 1.2B instruct model. Like their previous LFM models, it utilizes an efficient transformer architecture, using both regular transformer layers and also Mamba linear attention layers. This makes the model up to 2x faster than the similar sized Qwen3 1.7B model.
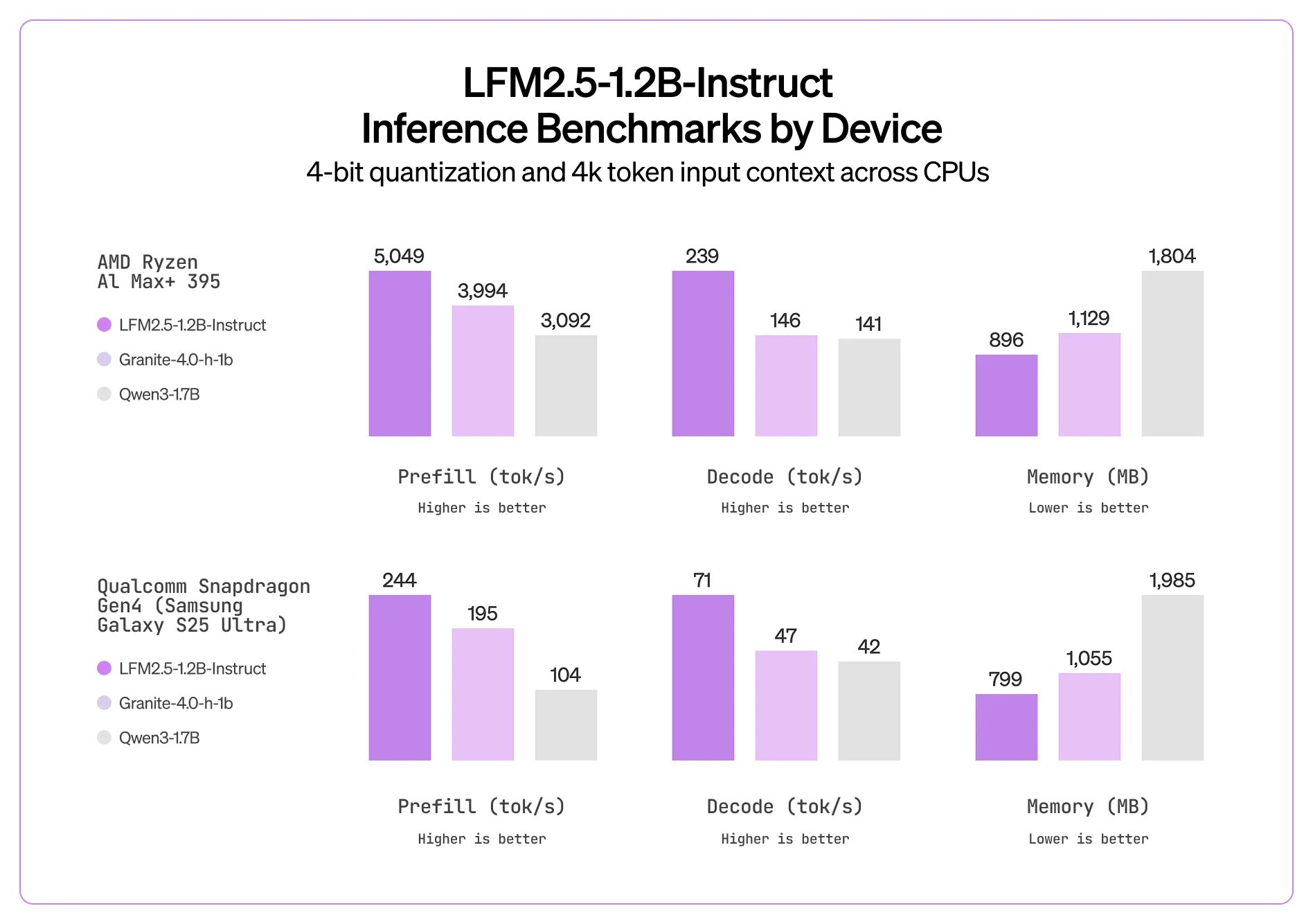
In terms of real world quality, I have heard nothing but good things so far from the community. It punches above its weight in terms of quality and can be deployed anywhere.
When using it yourself, know that it will excel at basic agent tasks (web search), data extraction, and RAG; basically any task where instructing following is needed based on its context window. It will however fail when it comes to knowledge intensive tasks (world knowledge in LLMs is directly correlated to number of parameters, and this model doesn’t have many of those) and also coding tasks.
Quick Hits
How Anthropic does agent evals
As you use more and more agents in your day to day life and start deploying them to production, evaluating them becomes a critical task.
To help with this, Anthropic has released an in-depth post going over everything you need to consider when making an agent eval. It goes over what the eval space looks like, how to design a high quality eval, and what pitfalls you should avoid.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Notícias
Laboratórios de IA chineses abrem capital
Na busca por mais financiamento para treinar seus LLMs, dois grandes laboratórios chineses abriram capital esta semana.
O primeiro é Z.ai, conhecido por sua série de modelos GLM.
Seu modelo mais recente, GLM 4.7, é um modelo agêntico muito forte, com qualidade próxima ao Sonnet 4.5, sendo 7 vezes mais barato e totalmente open source.
O outro é MiniMax, conhecido por seu modelo principal ligeiramente menor, MiniMax M2.1.
Este modelo tem aproximadamente a mesma qualidade do GLM 4.7, com metade do total de parâmetros.
Ambas as empresas estão listadas na Bolsa de Valores de Hong Kong, que você pode negociar através da maioria das corretoras se você mora nos EUA.
Ambas tiveram primeiros dias fortes, com Z.ai ganhando 32% nos primeiros 2 dias de negociação, atingindo uma capitalização de mercado de quase US$ 9 bilhões, e Minimax mais que dobrando em seu primeiro dia, terminando com uma avaliação de US$ 13,5 bilhões.
Lançamentos
LFM 2.5
A Liquid AI revelou sua nova série de modelos fundamentais pequenos destinados à implementação em dispositivos.
As pontuações de benchmark do modelo são comparáveis ao GPT-4 original. É incrível ver o quanto avançamos em apenas 3 anos.
O primeiro modelo que eles revelaram é o modelo LFM 2.5 1.2B instruct. Como seus modelos LFM anteriores, ele utiliza uma arquitetura transformer eficiente, usando tanto camadas transformer regulares quanto camadas de atenção linear Mamba. Isso torna o modelo até 2x mais rápido que o modelo Qwen3 1.7B de tamanho semelhante.
Em termos de qualidade no mundo real, não ouvi nada além de coisas boas da comunidade até agora. Ele supera seu peso em termos de qualidade e pode ser implementado em qualquer lugar.
Ao usá-lo você mesmo, saiba que ele se destacará em tarefas básicas de agentes (pesquisa web), extração de dados e RAG; basicamente qualquer tarefa onde seja necessário seguir instruções com base em sua janela de contexto. No entanto, ele falhará quando se trata de tarefas intensivas em conhecimento (o conhecimento de mundo em LLMs está diretamente correlacionado ao número de parâmetros, e este modelo não tem muitos deles) e também em tarefas de codificação.
Destaques Rápidos
Como a Anthropic faz avaliações de agentes
À medida que você usa cada vez mais agentes no seu dia a dia e começa a implantá-los em produção, avaliá-los se torna uma tarefa crítica.
Para ajudar com isso, a Anthropic lançou um post detalhado abordando tudo o que você precisa considerar ao fazer uma avaliação de agente. Ele aborda como é o espaço de avaliação, como projetar uma avaliação de alta qualidade e quais armadilhas você deve evitar.
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, não deixe de participar da nossa lista de e-mails abaixo.
Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Noticias
Laboratorios de IA chinos salen a bolsa
En la búsqueda de más financiación para entrenar sus LLMs, dos grandes laboratorios chinos han salido a bolsa esta semana.
El primero es Z.ai, conocido por su serie de modelos GLM.
Su modelo más reciente, GLM 4.7, es un modelo agéntico muy potente, de calidad similar a Sonnet 4.5, siendo 7 veces más económico y totalmente de código abierto.
El otro es MiniMax, conocido por su modelo insignia ligeramente más pequeño MiniMax M2.1.
Este modelo tiene aproximadamente la misma calidad que GLM 4.7, siendo la mitad de los parámetros totales.
Ambas compañías cotizan en la Bolsa de Valores de Hong Kong, a la cual puedes acceder a través de la mayoría de los brokers si vives en Estados Unidos.
Ambas tuvieron días de debut fuertes, con Z.ai ganando un 32% en los primeros 2 días de negociación alcanzando una capitalización de mercado de casi $9 mil millones de dólares, y Minimax más que duplicándose en su primer día, terminando con una valoración de $13.5 mil millones de dólares.
Lanzamientos
LFM 2.5
Liquid AI ha presentado su nueva serie de modelos fundamentales pequeños destinados al despliegue en dispositivos.
Las puntuaciones de benchmark del modelo son comparables al GPT-4 original. Es increíble ver hasta dónde hemos llegado en solo 3 años.
El primer modelo que han presentado es el modelo LFM 2.5 1.2B instruct. Como sus modelos LFM anteriores, utiliza una arquitectura transformer eficiente, usando tanto capas transformer regulares como capas de atención lineal Mamba. Esto hace que el modelo sea hasta 2 veces más rápido que el modelo Qwen3 1.7B de tamaño similar.
En términos de calidad en el mundo real, hasta ahora solo he escuchado cosas buenas de la comunidad. Supera su peso en términos de calidad y se puede desplegar en cualquier lugar.
Al usarlo tú mismo, debes saber que sobresaldrá en tareas agénticas básicas (búsqueda web), extracción de datos y RAG; básicamente cualquier tarea donde se necesite seguimiento de instrucciones basado en su ventana de contexto. Sin embargo, fallará cuando se trate de tareas intensivas en conocimiento (el conocimiento mundial en los LLMs está directamente correlacionado con el número de parámetros, y este modelo no tiene muchos) y también en tareas de programación.
Breves
Cómo Anthropic hace evaluaciones de agentes
A medida que usas más y más agentes en tu día a día y comienzas a desplegarlos en producción, evaluarlos se convierte en una tarea crítica.
Para ayudar con esto, Anthropic ha publicado un artículo en profundidad que repasa todo lo que necesitas considerar al hacer una evaluación de agentes. Cubre cómo es el espacio de evaluación, cómo diseñar una evaluación de alta calidad y qué obstáculos debes evitar.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.