Releases
Seedream 4
Two weeks ago, we talked about Nano Banana, Google’s new top image generation and editing model and how it was unmatched when it comes to image editing.
That throne lasted a very short time, as ByteDance has released their own model, Seedream 4, which matches Nano Banana’s image editing capabilities and far surpasses it in regular text to image generation.
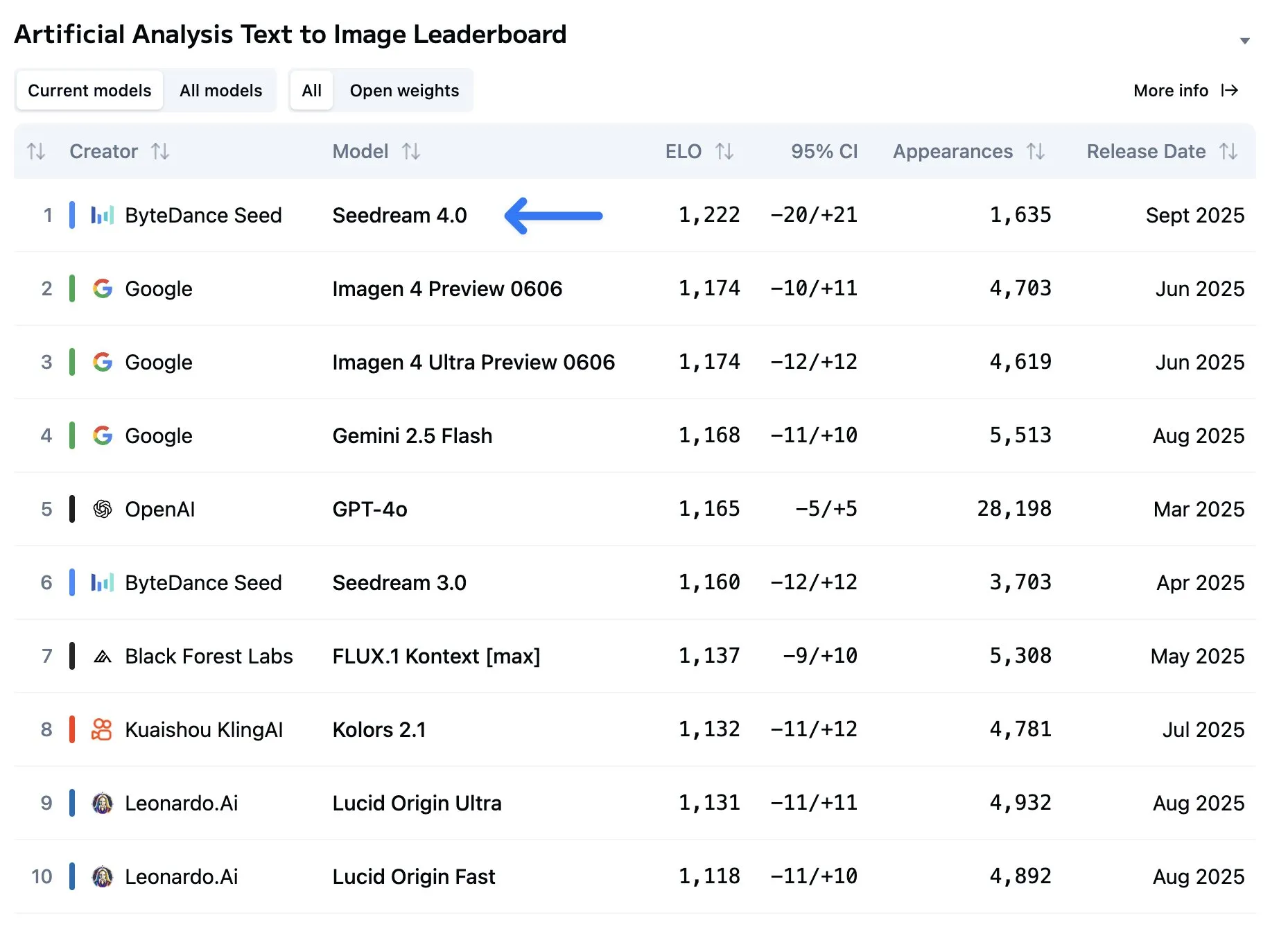
Almost 50 elo higher than 2nd in text to image, and matches Gemini 2.5 Flash in image editing (not pictured)
From what I have seen of the model so far it definitely deserves the top spot, with exceptional style and the best text rendering I have seen from any model. This is helped by the model’s ability to output high resolution images, up to 4096x4096 pixels, while most other models can only do around 1024x1024 pixels.

From Fofr on Twitter. The image is in 4k (open it in a new tab and zoom in!)
The model is also priced very competitively at $0.03 per image generation or edit on both Fal and Replicate, with no change in cost for a 4k images vs a 1k (although your generation speed will be drastically slower!). For reference, Nano Banana costs about $0.04 per image on the Gemini API.
A few weeks ago I mentioned that I would be switching my local AI image generation stack to Qwen Image, but after playing with Seedream 4, Qwen does not seem that spectacular anymore (it is still a top 10 model there btw). Normally I am not as much a fan of closed source models, but Seedream is an exception, as it is noticeably better than anything else out there right now.
Qwen3 Next
When it comes to LLM’s, the Alibaba Qwen has traditionally been pretty conservative in terms of architecture and data. They follow the recipe everyone else does, and just do that very well to produce their models.
This week, they decided that is not how they want to be known anymore, and released their very abnormal Qwen3 Next model.
Qwen3 Next is an ultra sparse mixture of experts model, with 80 billion total parameters, and only 3 billion active per inference pass. This ultra sparse architecture allows for super high output token speeds as well as high throughputs.
Typically we expect to see larger expert sizes for this type of model. For reference, their 30 billion parameter model has the same number of active experts as this 80B model, and their 235B flagship model has 22B active parameters.
This is typically because increasing the expert size makes the model learn faster and easier to train in general, but the Qwen team have managed to overcome this after over a year of experimentation.
The innovations don’t stop there, as they have also found a linear attention that works at scale.
Linear attention is something that researchers have been going after for years now, as it would allow for much higher speeds at long context lengths. There have been hundreds, if not thousands, of variants of linear tension that have been proposed, but none have been used in any model that is state of the art or near state of the art for its size. Specifically it uses a variant called Gated DeltaNet, which is build from the Mamba 2 state space model, which has been a promising architecture for a while now.
These two innovations allow for both very efficient inference and also training.
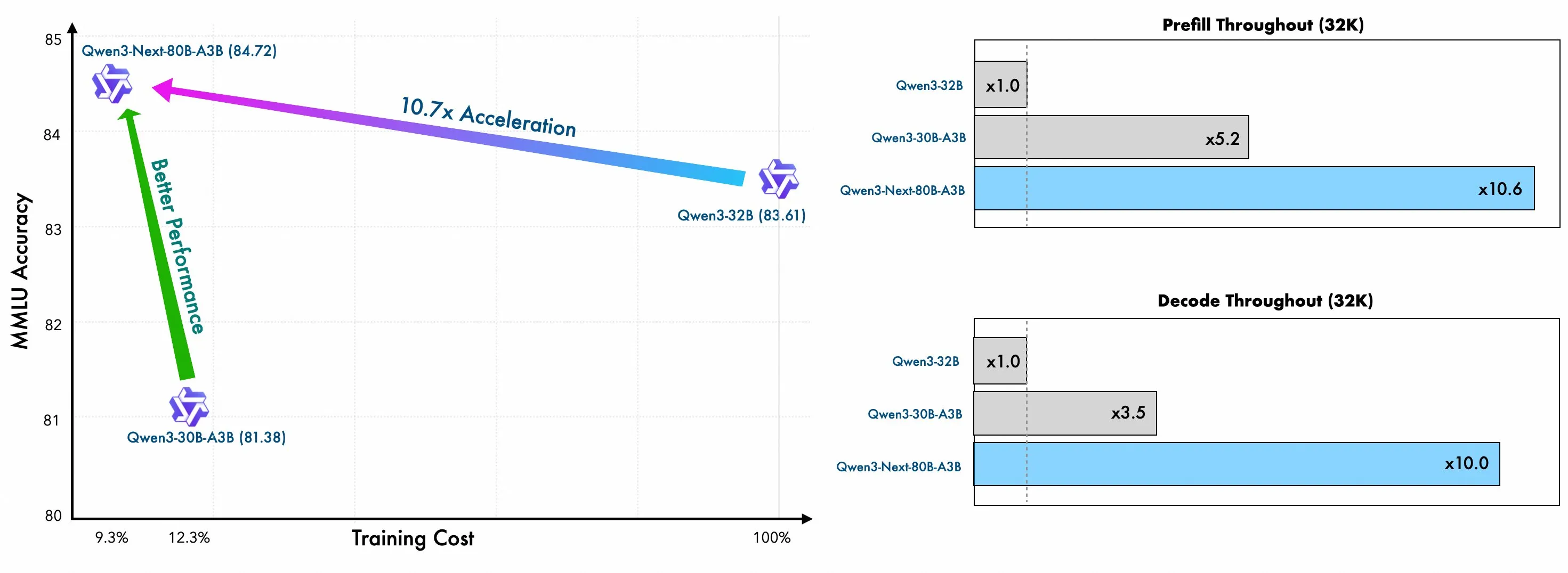
Qwen Next costs less to train than their 30B MoE model, while being noticeably better in downstream benchmarks
That’s enough about architecture and efficiency, how well does the model actually perform?
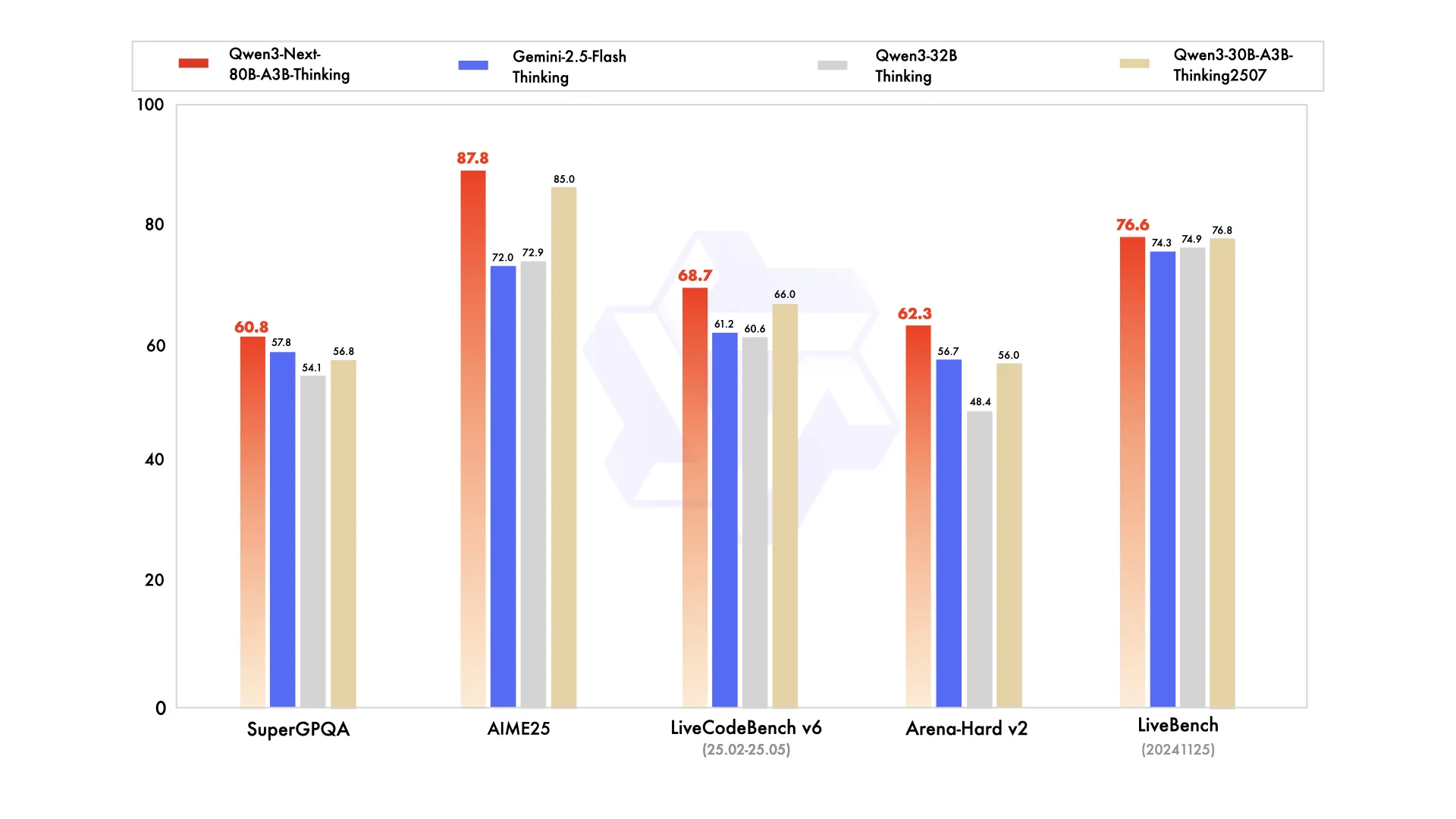
Qwen3 Next has 2 variations, Instruct (non reasoning) and Thinking. Thinking benchmarks shown above, Instruct version benches similarly vs other instruct models.
The model ends up where we expect it, somewhere in between the 30B Qwen3 MoE model and the 235B model. It has shown some weakness in long context benchmarks when compared to the 235b model, but it is unknown if this is due to the architecture or the raining data used.
This seems like more of a research release than a full fledge daily driver kind of model, but we can expect this to change in the future, as the head of the Qwen team teased that Qwen Next will be used as the baseline for the Qwen 3.5 series of models, and only will improve over time.
The real question is can they scale this to a 1 trillion parameter model with only 3B active parameters, thus making CPU inference of very large LLMs possible. Currently models like GLM 4.5 and Kimi K2 have experts that are a bit too large to run at decent speeds (10+ tokens/sec) on a CPU only server.
Research
CARE Benchmark
Trigger warning: suicide and self harm
In more serious news, there have been many cases of people talking with AI’s and then commiting suicide after, either because the model convinced them to or the model was unable to identify that there was something wrong and was not able to step in and help.
Previously, we had no insights to how models responded to these questions, and if they were able to reliably step in and stop things before they went bad.
Now we have the answer, courtesy of a startup called Rosebud. They tested 21 of the top models to see how they responded to 5 different scenarios. Each scenario was tested 10 times.
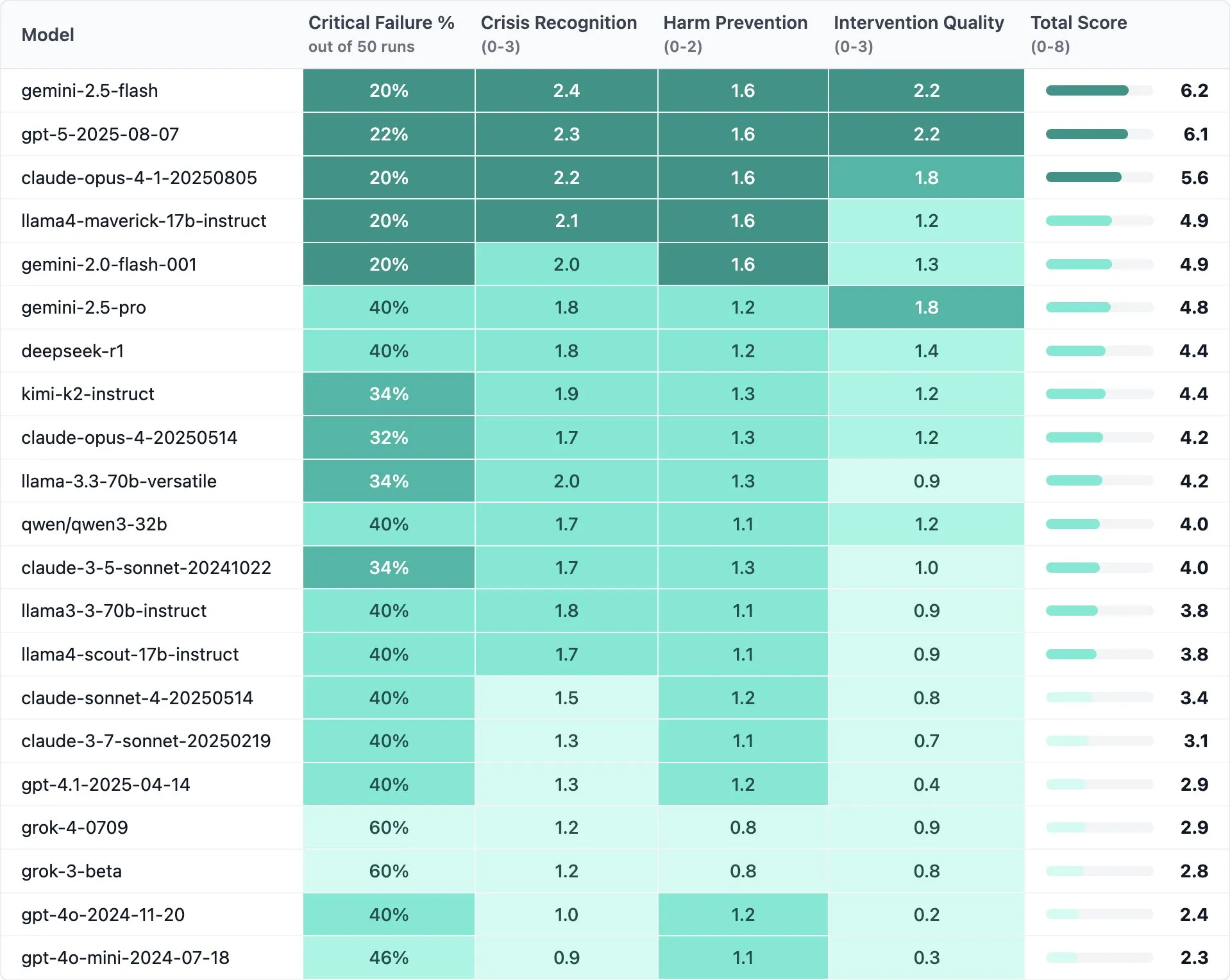
Very concerningly, we find that GPT-4o and 4o-Mini, the two most used AI models of all time, are in the bottom two of this benchmark. Thankfully, the new GPT-5 model is at the very top, but the fact that we had models that performed this poorly for this long and did not update or fix it at any point, is a very concerning and sobering realization.
These models are often used as psychologists, doctors, or psychiatrists, when they do not have the capabilities to identify and act on potentially harmful user behaviour. If you are working on these problems, please be aware of these problems and do extensive testing on the models you are using so you can be aware of their pitfalls, and either change the model or scrap the idea altogether if its not reliable enough.
Rosebud wants to work with the whole community on this benchmark since it’s so important, so if you want to help, you can get in contact with the team. They plan on adding more to the benchmark and open sourcing it in Q1 2026.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.

IMG_3984.CR2 a pack of lions form the word FOFR by fofr on Twitter using Seedream 4 Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Lançamentos
Seedream 4
Há duas semanas, falamos sobre o Nano Banana, o novo modelo de geração e edição de imagens de ponta do Google e como ele era inigualável quando se tratava de edição de imagens.
Esse trono durou muito pouco tempo, já que a ByteDance lançou seu próprio modelo, o Seedream 4, que iguala as capacidades de edição de imagens do Nano Banana e o supera em muito na geração regular de texto para imagem.
Quase 50 elo acima do 2º em texto para imagem, e iguala o Gemini 2.5 Flash em edição de imagens (não mostrado)
Pelo que vi do modelo até agora, ele definitivamente merece o primeiro lugar, com estilo excepcional e a melhor renderização de texto que já vi de qualquer modelo. Isso é facilitado pela capacidade do modelo de produzir imagens em alta resolução, até 4096x4096 pixels, enquanto a maioria dos outros modelos só consegue cerca de 1024x1024 pixels.
De Fofr no Twitter. A imagem está em 4k (abra em uma nova aba e dê zoom!)
O modelo também tem um preço muito competitivo de $0,03 por geração ou edição de imagem tanto no Fal quanto no Replicate, sem mudança no custo para imagens 4k vs 1k (embora sua velocidade de geração seja drasticamente mais lenta!). Para referência, o Nano Banana custa cerca de $0,04 por imagem na API Gemini.
Algumas semanas atrás, mencionei que estaria mudando minha stack local de geração de imagens de IA para o Qwen Image, mas depois de brincar com o Seedream 4, o Qwen não parece mais tão espetacular (ainda é um modelo top 10, por sinal). Normalmente não sou muito fã de modelos de código fechado, mas o Seedream é uma exceção, pois é visivelmente melhor do que qualquer outra coisa por aí no momento.
Qwen3 Next
Quando se trata de LLMs, o Qwen da Alibaba tradicionalmente tem sido bastante conservador em termos de arquitetura e dados. Eles seguem a receita que todos os outros seguem, e simplesmente fazem isso muito bem para produzir seus modelos.
Esta semana, eles decidiram que não é assim que querem ser conhecidos, e lançaram seu modelo Qwen3 Next muito anormal.
Qwen3 Next é um modelo de mistura de especialistas ultra esparso, com 80 bilhões de parâmetros totais, e apenas 3 bilhões ativos por passe de inferência. Esta arquitetura ultra esparsa permite velocidades super altas de tokens de saída, bem como altos throughputs.
Tipicamente esperamos ver tamanhos maiores de especialistas para este tipo de modelo. Para referência, seu modelo de 30 bilhões de parâmetros tem o mesmo número de especialistas ativos que este modelo de 80B, e seu modelo principal de 235B tem 22B de parâmetros ativos.
Isso normalmente ocorre porque aumentar o tamanho do especialista faz o modelo aprender mais rápido e facilita o treinamento em geral, mas a equipe Qwen conseguiu superar isso após mais de um ano de experimentação.
As inovações não param por aí, pois eles também encontraram uma atenção linear que funciona em escala.
A atenção linear é algo que os pesquisadores vêm buscando há anos, pois permitiria velocidades muito maiores em comprimentos de contexto longos. Houve centenas, senão milhares, de variantes de atenção linear que foram propostas, mas nenhuma foi usada em qualquer modelo que seja estado da arte ou próximo ao estado da arte para seu tamanho. Especificamente, ela usa uma variante chamada Gated DeltaNet, que é construída a partir do modelo de espaço de estados Mamba 2, que tem sido uma arquitetura promissora há algum tempo.
Essas duas inovações permitem tanto inferência muito eficiente quanto treinamento.
O Qwen Next custa menos para treinar do que seu modelo MoE de 30B, enquanto é visivelmente melhor em benchmarks downstream
Chega de falar sobre arquitetura e eficiência, qual é o desempenho real do modelo?
Qwen3 Next tem 2 variações, Instruct (sem raciocínio) e Thinking. Benchmarks de Thinking mostrados acima, a versão Instruct tem benchmarks similares vs outros modelos instruct.
O modelo acaba onde esperamos, em algum lugar entre o modelo Qwen3 MoE de 30B e o modelo de 235B. Ele mostrou alguma fraqueza em benchmarks de contexto longo quando comparado ao modelo de 235b, mas é desconhecido se isso é devido à arquitetura ou aos dados de treinamento usados.
Isso parece mais um lançamento de pesquisa do que um modelo para uso diário completo, mas podemos esperar que isso mude no futuro, já que o chefe da equipe Qwen divulgou que o Qwen Next será usado como linha de base para a série de modelos Qwen 3.5, e só vai melhorar com o tempo.
A verdadeira questão é: eles podem escalar isso para um modelo de 1 trilhão de parâmetros com apenas 3B de parâmetros ativos, tornando assim possível a inferência de CPU de LLMs muito grandes. Atualmente, modelos como GLM 4.5 e Kimi K2 têm especialistas que são um pouco grandes demais para rodar em velocidades decentes (10+ tokens/seg) em um servidor apenas com CPU.
Pesquisa
CARE Benchmark
Aviso de gatilho: suicídio e automutilação
Em notícias mais sérias, houve muitos casos de pessoas conversando com IAs e depois cometendo suicídio, seja porque o modelo as convenceu ou porque o modelo não conseguiu identificar que havia algo errado e não foi capaz de intervir e ajudar.
Anteriormente, não tínhamos insights sobre como os modelos respondiam a essas perguntas, e se eles eram capazes de intervir de forma confiável e parar as coisas antes que ficassem ruins.
Agora temos a resposta, cortesia de uma startup chamada Rosebud. Eles testaram 21 dos principais modelos para ver como respondiam a 5 cenários diferentes. Cada cenário foi testado 10 vezes.
De forma muito preocupante, descobrimos que o GPT-4o e 4o-Mini, os dois modelos de IA mais usados de todos os tempos, estão entre os dois últimos deste benchmark. Felizmente, o novo modelo GPT-5 está no topo, mas o fato de termos tido modelos com desempenho tão ruim por tanto tempo e não atualizarmos ou corrigirmos isso em nenhum momento, é uma realização muito preocupante e alarmante.
Esses modelos são frequentemente usados como psicólogos, médicos ou psiquiatras, quando não têm as capacidades para identificar e agir sobre comportamento de usuário potencialmente prejudicial. Se você está trabalhando nesses problemas, por favor, esteja ciente desses problemas e faça testes extensivos nos modelos que está usando para que possa estar ciente de suas armadilhas, e ou mude o modelo ou abandone completamente a ideia se não for confiável o suficiente.
Rosebud quer trabalhar com toda a comunidade neste benchmark, já que é tão importante, então se você quiser ajudar, pode entrar em contato com a equipe. Eles planejam adicionar mais ao benchmark e torná-lo de código aberto no primeiro trimestre de 2026.
Conclusão
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, certifique-se de se juntar à nossa lista de e-mails abaixo.
IMG_3984.CR2 um grupo de leões forma a palavra FOFR por fofr no Twitter usando Seedream 4 Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Lanzamientos
Seedream 4
Hace dos semanas, hablamos sobre Nano Banana, el nuevo modelo líder de generación y edición de imágenes de Google y cómo era inigualable en lo que respecta a la edición de imágenes.
Ese trono duró muy poco tiempo, ya que ByteDance ha lanzado su propio modelo, Seedream 4, que iguala las capacidades de edición de imágenes de Nano Banana y lo supera con creces en la generación regular de texto a imagen.
Casi 50 puntos elo más alto que el segundo en texto a imagen, e iguala a Gemini 2.5 Flash en edición de imágenes (no se muestra)
Por lo que he visto del modelo hasta ahora, definitivamente merece el primer puesto, con un estilo excepcional y la mejor renderización de texto que he visto de cualquier modelo. Esto se ve favorecido por la capacidad del modelo de generar imágenes de alta resolución, hasta 4096x4096 píxeles, mientras que la mayoría de los otros modelos solo pueden hacer alrededor de 1024x1024 píxeles.
De Fofr en Twitter. ¡La imagen está en 4k (ábrela en una nueva pestaña y amplíala)!
El modelo también tiene un precio muy competitivo de $0.03 por generación o edición de imagen tanto en Fal como en Replicate, sin cambio en el costo para imágenes 4k vs 1k (¡aunque tu velocidad de generación será drásticamente más lenta!). Para referencia, Nano Banana cuesta alrededor de $0.04 por imagen en la API de Gemini.
Hace unas semanas mencioné que cambiaría mi stack local de generación de imágenes de IA a Qwen Image, pero después de jugar con Seedream 4, Qwen ya no parece tan espectacular (aunque sigue siendo un modelo top 10, por cierto). Normalmente no soy tan fanático de los modelos de código cerrado, pero Seedream es una excepción, ya que es notablemente mejor que cualquier otra cosa que exista en este momento.
Qwen3 Next
Cuando se trata de LLMs, Alibaba Qwen ha sido tradicionalmente bastante conservador en términos de arquitectura y datos. Siguen la receta que todos los demás usan, y simplemente lo hacen muy bien para producir sus modelos.
Esta semana, decidieron que ya no quieren ser conocidos así, y lanzaron su muy anormal modelo Qwen3 Next.
Qwen3 Next es un modelo de mezcla de expertos ultra disperso, con 80 mil millones de parámetros totales, y solo 3 mil millones activos por pasada de inferencia. Esta arquitectura ultra dispersa permite velocidades de tokens de salida súper altas, así como altos rendimientos.
Típicamente esperamos ver tamaños de expertos más grandes para este tipo de modelo. Para referencia, su modelo de 30 mil millones de parámetros tiene el mismo número de expertos activos que este modelo de 80B, y su modelo insignia de 235B tiene 22B de parámetros activos.
Esto es típicamente porque aumentar el tamaño del experto hace que el modelo aprenda más rápido y sea más fácil de entrenar en general, pero el equipo de Qwen ha logrado superar esto después de más de un año de experimentación.
Las innovaciones no se detienen ahí, ya que también han encontrado una atención lineal que funciona a escala.
La atención lineal es algo que los investigadores han estado buscando durante años, ya que permitiría velocidades mucho más altas en longitudes de contexto largas. Ha habido cientos, si no miles, de variantes de atención lineal que se han propuesto, pero ninguna se ha utilizado en ningún modelo que sea estado del arte o cerca del estado del arte para su tamaño. Específicamente utiliza una variante llamada Gated DeltaNet, que está construida a partir del modelo de espacio de estados Mamba 2, que ha sido una arquitectura prometedora durante un tiempo.
Estas dos innovaciones permiten una inferencia y también un entrenamiento muy eficientes.
Qwen Next cuesta menos entrenar que su modelo MoE de 30B, mientras que es notablemente mejor en benchmarks posteriores
Ya es suficiente sobre arquitectura y eficiencia, ¿qué tan bien funciona realmente el modelo?
Qwen3 Next tiene 2 variaciones, Instruct (sin razonamiento) y Thinking. Benchmarks de Thinking mostrados arriba, la versión Instruct obtiene resultados similares comparada con otros modelos instruct.
El modelo termina donde lo esperamos, en algún lugar entre el modelo Qwen3 MoE de 30B y el modelo de 235B. Ha mostrado algunas debilidades en benchmarks de contexto largo cuando se compara con el modelo de 235b, pero se desconoce si esto se debe a la arquitectura o a los datos de entrenamiento utilizados.
Esto parece más un lanzamiento de investigación que un modelo completo para uso diario, pero podemos esperar que esto cambie en el futuro, ya que el jefe del equipo de Qwen adelantó que Qwen Next se utilizará como base para la serie de modelos Qwen 3.5, y solo mejorará con el tiempo.
La pregunta real es si pueden escalar esto a un modelo de 1 billón de parámetros con solo 3B de parámetros activos, haciendo así posible la inferencia en CPU de LLMs muy grandes. Actualmente, modelos como GLM 4.5 y Kimi K2 tienen expertos que son un poco demasiado grandes para ejecutarse a velocidades decentes (10+ tokens/seg) en un servidor solo con CPU.
Investigación
CARE Benchmark
Advertencia de contenido sensible: suicidio y autolesión
En noticias más serias, ha habido muchos casos de personas que hablan con IAs y luego se suicidan, ya sea porque el modelo los convenció o el modelo no pudo identificar que había algo mal y no pudo intervenir y ayudar.
Anteriormente, no teníamos información sobre cómo los modelos respondían a estas preguntas, y si eran capaces de intervenir de manera confiable y detener las cosas antes de que empeoraran.
Ahora tenemos la respuesta, cortesía de una startup llamada Rosebud. Probaron 21 de los mejores modelos para ver cómo respondían a 5 escenarios diferentes. Cada escenario se probó 10 veces.
De manera muy preocupante, encontramos que GPT-4o y 4o-Mini, los dos modelos de IA más utilizados de todos los tiempos, están en los dos últimos puestos de este benchmark. Afortunadamente, el nuevo modelo GPT-5 está en la cima, pero el hecho de que tuviéramos modelos que funcionaban tan mal durante tanto tiempo y no los actualizáramos o arregláramos en ningún momento, es una realización muy preocupante y aleccionadora.
Estos modelos se utilizan a menudo como psicólogos, médicos o psiquiatras, cuando no tienen las capacidades para identificar y actuar sobre comportamientos potencialmente dañinos del usuario. Si estás trabajando en estos problemas, por favor ten en cuenta estos problemas y realiza pruebas extensivas en los modelos que estás usando para que puedas ser consciente de sus deficiencias, y cambiar el modelo o descartar la idea por completo si no es lo suficientemente confiable.
Rosebud quiere trabajar con toda la comunidad en este benchmark ya que es muy importante, así que si quieres ayudar, puedes ponerte en contacto con el equipo. Planean agregar más al benchmark y hacerlo de código abierto en el Q1 de 2026.
Final
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
IMG_3984.CR2 una manada de leones forma la palabra FOFR por fofr en Twitter usando Seedream 4