News
Anthropic VS DoW
Anthropic, along most of the major US AI labs, have had deals with the US government to deploy their AI models for use in different departments, including for classified use cases.
After finding out one of their models (a fine tuned version of Sonnet 4.5) was used to help capture Venezuelan president Nicolas Maduro, Anthropic wanted assurances from the government that Claude was not being used for any use cases that Anthropic did not want it being used for; specifically, making autonomous weapons (the models are not good enough to do this yet) and mass surveillance of American citizens.
In response, the Department of War (DoW) (previously the Department of Defense) said that they should be allowed “all lawful use”, but Anthropic held firm in they demands.
Because they did not give in to the governments demands, Anthropic has now been labeled as a supply chain risk, which means that Claude cannot be used by the Department of War or for any DoW contracts.
After this happened, OpenAI signed a contract with the DoW themselves. Sam Altman claimed that the same ideals that Anthropic had were upheld by OpenAI as well, and that the DoW agreed with these terms. This is contradicted by the DoW UnderSecretary, who says that OpenAI gave them the “all lawful use” clause that they wanted, with “mutually agreed upon safety mechanisms”, which Anthropic was also offered but turned down.
The situation is still developing as I write this, so I will reserve any opinions until everything that has and will happen is clear.
Releases
Nano Banana 2
Into more lighthearted news, Google has released a new version of their popular Nano Banana image generation (and editing) model.
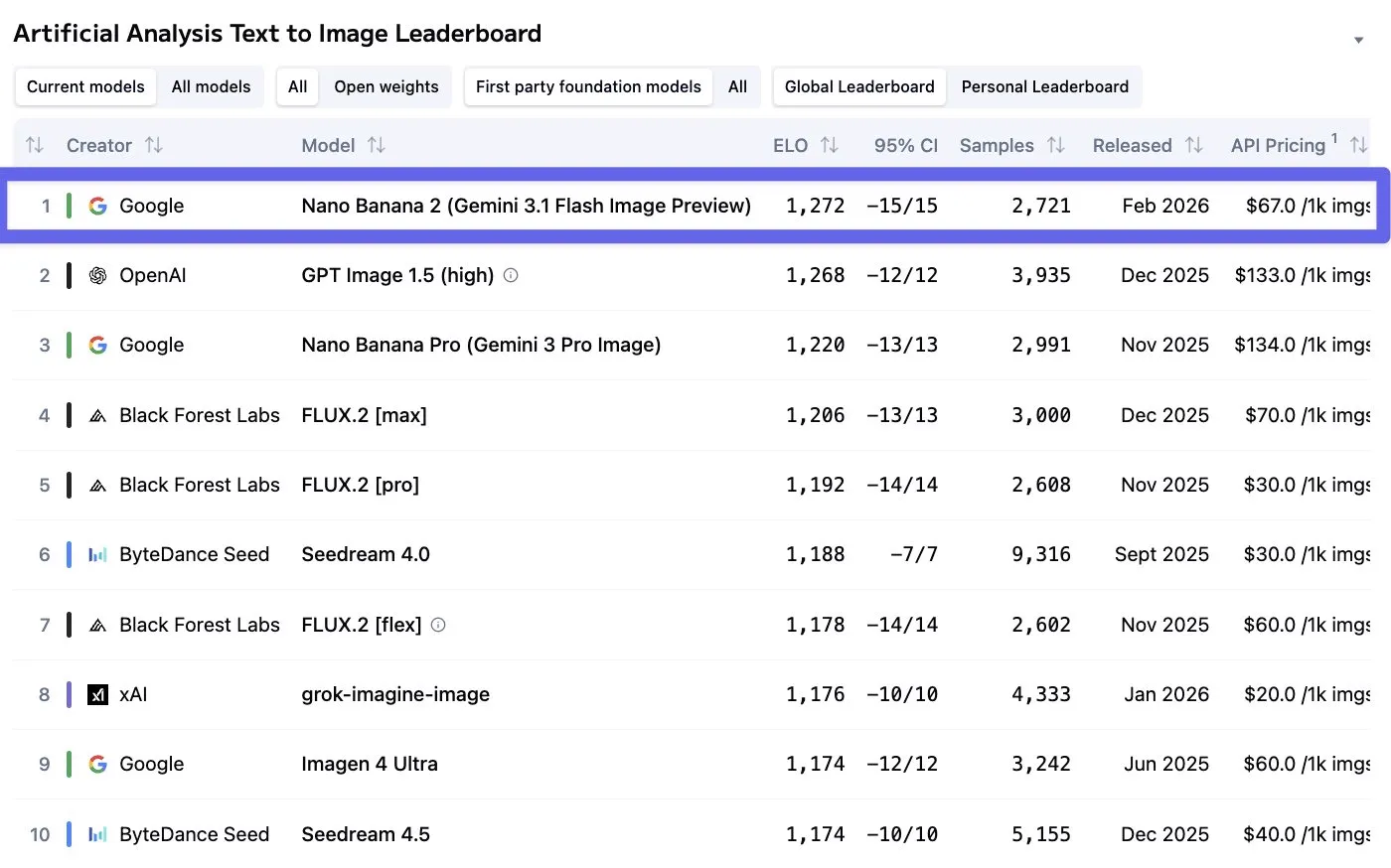
Nano Banana 2 is measurably better than its predecessor — data from Artificial Analysis
Not only is the quality measurably increased, it also has gotten cheaper and faster as well, as it is built on the (unreleased) Gemini 3.1 Flash model.
Pricing has roughly halved to $0.15 per 4K image, and speeds are around 50% faster now as well.
The model also now supports more extreme aspect ratios, like 4:1 and 8:1, allowing you to make some very wide (or tall) images.

Prompt: A photo of a monstera leaf against a simple backdrop, cleverly and organically appearing within the natural gaps of the leaf are the words Nano Banana

Enamel banasaurus pin— from Twitter
Qwen 3.5 Medium Models
Qwen started the release of their 3.5 series of models last week, releasing the largest model in the family, a 400 billion parameter model. It was not very interesting or notably good however, so we did not cover it.
This week though, they released the medium sized models in the family, and they are much more interesting. We have 3 new open source models, being Qwen3.5-35B-A3B, Qwen3.5-122B-A10B, Qwen3.5-27B, and a closed source model, which is Qwen3.5-Flash, which is the 35B model with longer context length and some built in tools.
For the model naming, the A3B and A10B means that the models are mixture of experts models, with 3 billion and 10 billion parameters respectively.
This means that they will run as fast as a 3 (or 10) billion parameter model while having the intelligence of a 35 (or 122) billion parameter model (roughly).
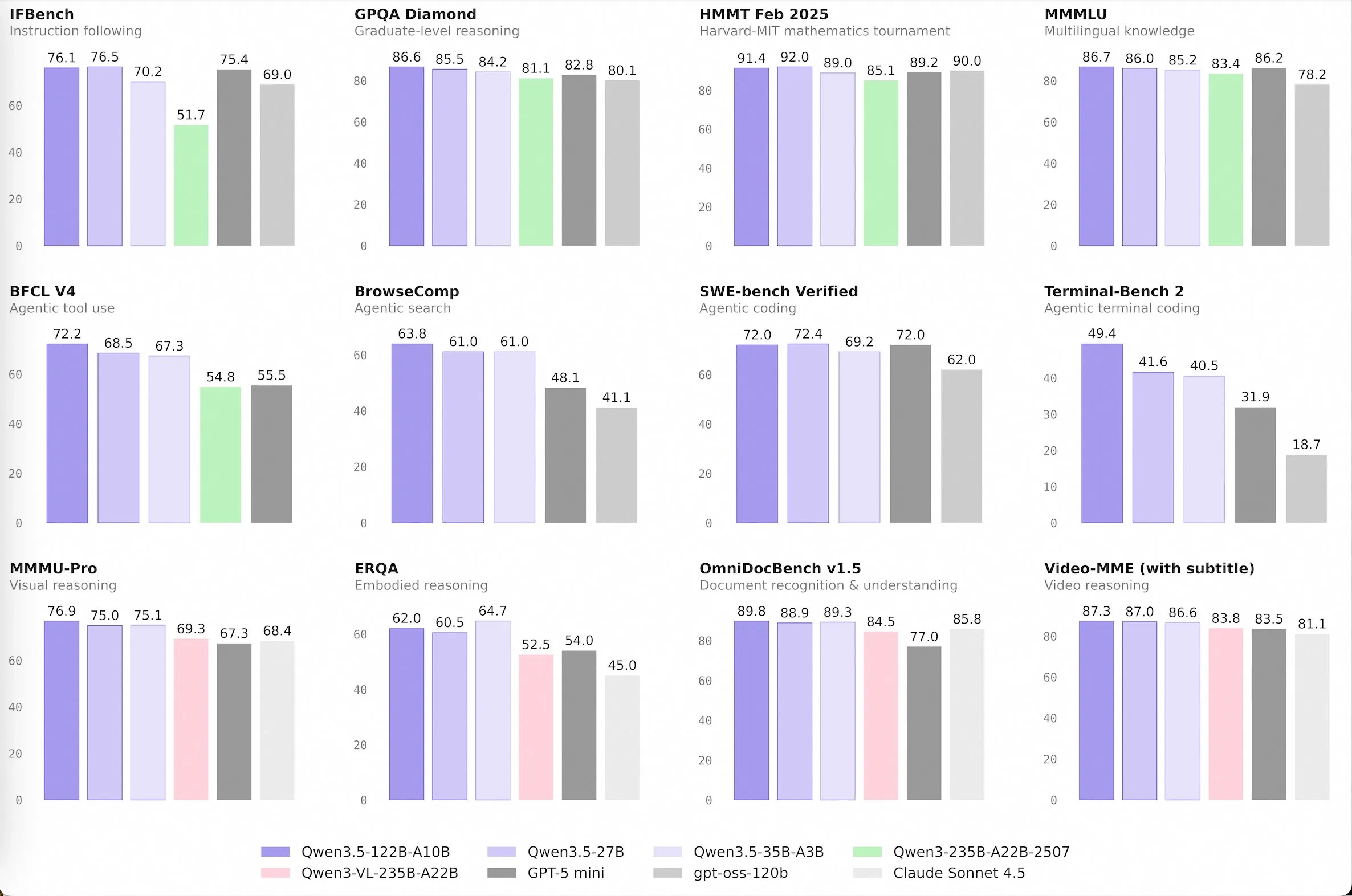
The standout of these models is the 35B-A3B model. This size is fairly easy to run at home, if you have a Mac with at least 24GB of memory or a PC with a GPU and >24GB of CPU + GPU memory you can run it.
For its size, it is the best model out there right now, beating the likes of GLM 4.7 Flash and NanBeige, and even outclassing models 5-10x larger like GPT-oss 120B and the old Qwen 3 flagship 235B model.
Normally, the Qwen models are text only models, and then the Qwen team makes a finetune of them a few months later to add in multimodal capabilities.
This is not the case this time however, as all of the Qwen 3.5 models support image (and video) inputs.
The dense 27 billion parameter model seems even smarter, the issue is that because it is not a MoE model it is 5-10x slower to run, especially on compute constrained devices.
It is noticeably better at difficult agentic applications, like coding.
If you like running local models and have decent hardware, I would highly recommend checking out some of these models.
If you are not compute middle class, worry not, as Qwen should be releasing the small models in the next week or two.
Finish
I hope you enjoyed the news this week. If you want to get the news every week, be sure to join our mailing list below.
Claude is a silly guy Nota: Este artigo foi traduzido automaticamente com Claude Sonnet 4.5; a qualidade pode estar reduzida, especialmente na terminologia técnica.
Notícias
Anthropic VS DoW
A Anthropic, junto com a maioria dos principais laboratórios de IA dos EUA, tem acordos com o governo dos EUA para implementar seus modelos de IA para uso em diferentes departamentos, incluindo casos de uso classificados.
Após descobrir que um de seus modelos (uma versão ajustada do Sonnet 4.5) foi usado para ajudar a capturar o presidente venezuelano Nicolás Maduro, a Anthropic quis garantias do governo de que o Claude não estava sendo usado para nenhum caso de uso que a Anthropic não quisesse que fosse usado; especificamente, fazer armas autônomas (os modelos ainda não são bons o suficiente para fazer isso) e vigilância em massa de cidadãos americanos.
Em resposta, o Departamento de Guerra (DoW) (anteriormente o Departamento de Defesa) disse que deveria ser permitido “todo uso legal”, mas a Anthropic se manteve firme em suas demandas.
Por não cederem às demandas do governo, a Anthropic agora foi rotulada como um risco de cadeia de suprimentos, o que significa que o Claude não pode ser usado pelo Departamento de Guerra ou para quaisquer contratos do DoW.
Depois disso, a OpenAI assinou um contrato com o próprio DoW. Sam Altman afirmou que os mesmos ideais que a Anthropic tinha foram mantidos pela OpenAI também, e que o DoW concordou com esses termos. Isso é contradito pelo Subsecretário do DoW, que diz que a OpenAI lhes deu a cláusula de “todo uso legal” que eles queriam, com “mecanismos de segurança mutuamente acordados”, que também foi oferecido à Anthropic, mas foi recusado.
A situação ainda está se desenvolvendo enquanto escrevo isso, então vou reservar quaisquer opiniões até que tudo o que aconteceu e acontecerá esteja claro.
Lançamentos
Nano Banana 2
Em notícias mais leves, o Google lançou uma nova versão de seu popular modelo de geração (e edição) de imagens Nano Banana.
Nano Banana 2 é mensuravelmente melhor que seu predecessor — dados da Artificial Analysis
Não apenas a qualidade aumentou mensuravelmente, mas também ficou mais barato e mais rápido, pois é construído sobre o modelo (não lançado) Gemini 3.1 Flash.
O preço foi reduzido aproximadamente pela metade para $0,15 por imagem 4K, e as velocidades estão cerca de 50% mais rápidas agora também.
O modelo agora também suporta proporções de aspecto mais extremas, como 4:1 e 8:1, permitindo que você crie imagens muito largas (ou altas).
Prompt: Uma foto de uma folha de monstera contra um pano de fundo simples, aparecendo de forma inteligente e orgânica dentro dos espaços naturais da folha estão as palavras Nano Banana
Pin de esmalte banassauro— do Twitter
Modelos Médios Qwen 3.5
A Qwen começou o lançamento de sua série 3.5 de modelos na semana passada, lançando o maior modelo da família, um modelo de 400 bilhões de parâmetros. No entanto, não foi muito interessante ou notavelmente bom, então não o cobrimos.
Esta semana, porém, eles lançaram os modelos de tamanho médio da família, e eles são muito mais interessantes. Temos 3 novos modelos de código aberto, sendo Qwen3.5-35B-A3B, Qwen3.5-122B-A10B, Qwen3.5-27B, e um modelo de código fechado, que é o Qwen3.5-Flash, que é o modelo 35B com maior comprimento de contexto e algumas ferramentas integradas.
Para a nomenclatura do modelo, A3B e A10B significa que os modelos são modelos de mistura de especialistas, com 3 bilhões e 10 bilhões de parâmetros respectivamente.
Isso significa que eles vão rodar tão rápido quanto um modelo de 3 (ou 10) bilhões de parâmetros enquanto têm a inteligência de um modelo de 35 (ou 122) bilhões de parâmetros (aproximadamente).
O destaque desses modelos é o modelo 35B-A3B. Este tamanho é bastante fácil de rodar em casa, se você tiver um Mac com pelo menos 24GB de memória ou um PC com uma GPU e >24GB de memória CPU + GPU você pode rodá-lo.
Para seu tamanho, é o melhor modelo disponível agora, superando o GLM 4.7 Flash e NanBeige, e até superando modelos 5-10x maiores como GPT-oss 120B e o antigo modelo principal Qwen 3 235B.
Normalmente, os modelos Qwen são modelos apenas de texto, e então a equipe Qwen faz um ajuste fino deles alguns meses depois para adicionar capacidades multimodais.
No entanto, este não é o caso desta vez, pois todos os modelos Qwen 3.5 suportam entradas de imagem (e vídeo).
O modelo denso de 27 bilhões de parâmetros parece ainda mais inteligente, o problema é que por não ser um modelo MoE ele é 5-10x mais lento para rodar, especialmente em dispositivos com recursos computacionais limitados.
É notavelmente melhor em aplicações agênticas difíceis, como codificação.
Se você gosta de rodar modelos locais e tem um hardware decente, eu recomendaria fortemente verificar alguns desses modelos.
Se você não é da classe média computacional, não se preocupe, pois a Qwen deve lançar os modelos pequenos na próxima semana ou duas.
Finalização
Espero que você tenha gostado das notícias desta semana. Se você quiser receber as notícias toda semana, não deixe de se juntar à nossa lista de e-mails abaixo.
Claude é um cara bobo Nota: Este artículo fue traducido automáticamente con Claude Sonnet 4.5; la calidad puede verse degradada, especialmente en la terminología técnica.
Noticias
Anthropic VS DoW
Anthropic, junto con la mayoría de los principales laboratorios de IA de EE.UU., ha tenido acuerdos con el gobierno estadounidense para implementar sus modelos de IA para uso en diferentes departamentos, incluyendo casos de uso clasificados.
Después de descubrir que uno de sus modelos (una versión ajustada de Sonnet 4.5) fue utilizado para ayudar a capturar al presidente venezolano Nicolás Maduro, Anthropic quiso garantías del gobierno de que Claude no estaba siendo utilizado para ningún caso de uso que Anthropic no quisiera; específicamente, crear armas autónomas (los modelos aún no son lo suficientemente buenos para hacer esto) y vigilancia masiva de ciudadanos estadounidenses.
En respuesta, el Departamento de Guerra (DoW) (anteriormente el Departamento de Defensa) dijo que deberían tener permitido “todo uso legal”, pero Anthropic se mantuvo firme en sus demandas.
Debido a que no cedieron a las demandas del gobierno, Anthropic ahora ha sido etiquetado como un riesgo en la cadena de suministro, lo que significa que Claude no puede ser utilizado por el Departamento de Guerra ni para ningún contrato del DoW.
Después de que esto sucediera, OpenAI firmó un contrato con el DoW. Sam Altman afirmó que los mismos ideales que tenía Anthropic también eran respetados por OpenAI, y que el DoW aceptó estos términos. Esto es contradicho por el Subsecretario del DoW, quien dice que OpenAI les dio la cláusula de “todo uso legal” que querían, con “mecanismos de seguridad mutuamente acordados”, que también se le ofreció a Anthropic pero rechazó.
La situación todavía se está desarrollando mientras escribo esto, así que reservaré cualquier opinión hasta que todo lo que ha sucedido y sucederá esté claro.
Lanzamientos
Nano Banana 2
Pasando a noticias más alegres, Google ha lanzado una nueva versión de su popular modelo de generación (y edición) de imágenes Nano Banana.
Nano Banana 2 es mediblemente mejor que su predecesor — datos de Artificial Analysis
No solo la calidad ha aumentado mediblemente, sino que también se ha vuelto más barato y más rápido, ya que está construido sobre el modelo (no lanzado) Gemini 3.1 Flash.
El precio se ha reducido aproximadamente a la mitad a $0.15 por imagen de 4K, y las velocidades son alrededor de un 50% más rápidas ahora también.
El modelo ahora también admite relaciones de aspecto más extremas, como 4:1 y 8:1, lo que te permite hacer imágenes muy anchas (o altas).
Prompt: Una foto de una hoja de monstera contra un fondo simple, apareciendo de manera inteligente y orgánica dentro de los espacios naturales de la hoja las palabras Nano Banana
Pin de banasaurio esmaltado— de Twitter
Qwen comenzó el lanzamiento de su serie de modelos 3.5 la semana pasada, lanzando el modelo más grande de la familia, un modelo de 400 mil millones de parámetros. Sin embargo, no fue muy interesante ni notablemente bueno, así que no lo cubrimos.
Esta semana, sin embargo, lanzaron los modelos de tamaño medio de la familia, y son mucho más interesantes. Tenemos 3 nuevos modelos de código abierto: Qwen3.5-35B-A3B, Qwen3.5-122B-A10B, Qwen3.5-27B, y un modelo de código cerrado, que es Qwen3.5-Flash, que es el modelo 35B con longitud de contexto más larga y algunas herramientas integradas.
Para el nombre del modelo, el A3B y A10B significa que los modelos son modelos de mezcla de expertos, con 3 mil millones y 10 mil millones de parámetros respectivamente.
Esto significa que se ejecutarán tan rápido como un modelo de 3 (o 10) mil millones de parámetros mientras tienen la inteligencia de un modelo de 35 (o 122) mil millones de parámetros (aproximadamente).
El destacado de estos modelos es el modelo 35B-A3B. Este tamaño es bastante fácil de ejecutar en casa, si tienes una Mac con al menos 24GB de memoria o una PC con una GPU y >24GB de memoria CPU + GPU puedes ejecutarlo.
Para su tamaño, es el mejor modelo que existe ahora mismo, superando a modelos como GLM 4.7 Flash y NanBeige, e incluso superando a modelos 5-10x más grandes como GPT-oss 120B y el antiguo modelo insignia Qwen 3 235B.
Normalmente, los modelos Qwen son modelos solo de texto, y luego el equipo de Qwen hace un ajuste de ellos unos meses después para agregar capacidades multimodales.
Sin embargo, este no es el caso esta vez, ya que todos los modelos Qwen 3.5 admiten entradas de imagen (y video).
El modelo denso de 27 mil millones de parámetros parece aún más inteligente, el problema es que debido a que no es un modelo MoE, es 5-10x más lento de ejecutar, especialmente en dispositivos con recursos computacionales limitados.
Es notablemente mejor en aplicaciones agénticas difíciles, como la programación.
Si te gusta ejecutar modelos locales y tienes hardware decente, recomendaría encarecidamente que pruebes algunos de estos modelos.
Si no eres de clase media computacional, no te preocupes, ya que Qwen debería estar lanzando los modelos pequeños en la próxima semana o dos.
Finalizar
Espero que hayas disfrutado las noticias de esta semana. Si quieres recibir las noticias cada semana, asegúrate de unirte a nuestra lista de correo a continuación.
Claude es un tipo tonto